Быстрая сортировка
Автором так называемой "быстрой" сортировки является Хоар. Он назвал ее быстрой потому, что в общем случае эффективность этого алгоритма довольно высока. Идея метода следующая. Выбирается некоторый "барьерный" элемент, относительно которого мы разбиваем исходный список на два подсписка. В один мы помещаем элементы, меньшие барьерного элемента, во второй — большие либо равные. Каждый из этих списков мы сортируем тем же способом, после чего приписываем к списку тех элементов, которые меньше барьерного, вначале сам барьерный элемент, а затем — список элементов не меньших барьерного. В итоге получаем список, состоящий из элементов, стоящих в правильном порядке.
При воплощении в программный код этой идеи нам, как обычно, понадобится пара предикатов.
Вспомогательный предикат partition будет отвечать за разбиение списка на два подсписка. У него будет четыре аргумента. Первые два элемента — входные: первый — исходный список, второй — барьерный элемент. Третий и четвертый элементы — выходные, соответственно, список элементов исходного списка, которые меньше барьерного, и список, состоящий из элементов, которые не меньше барьерного элемента.
Предикат quick_sort будет реализовывать алгоритм быстрой сортировки Хоара. Он будет состоять из двух предложений. Правило будет осуществлять с помощью предиката partition разделение непустого списка на два подсписка, затем сортировать каждый из этих подсписков рекурсивным вызовом себя самого, после чего, используя предикат conc (созданный нами ранее), конкретизирует второй аргумент списком, получаемым объединением отсортированного первого подсписка и списка, сконструированного из барьерного элемента (головы исходного списка) и отсортированного второго подсписка. Запишем это:
quick_sort([],[]). /* отсортированный пустой список остается пустым списком */ quick_sort([H|T],O):– partition(T,H,L,G), /* делим список T на L (список элементов меньших барьерного элемента H) и G (список элементов не меньших H) */ quick_sort(L,L_s), /* список L_s — результат упорядочивания элементов списка L */ quick_sort(G,G_s), /* аналогично, список G_s — результат упорядочивания элементов списка G */ conc(L_s,[H|G_s],O). /* соединяем список L_s со списком, у которого голова H, а хвост G_s, результат обозначаем O */ partition([],_,[],[]). /* как бы мы ни делили элементы пустого списка, ничего кроме пустых списков не получим */ partition([X|T],Y,[X|T1],Bs):– X<Y,!, partition(T,Y,T1,Bs). /* если элемент X меньше барьерного элемента Y, то мы добавляем его в третий аргумент */ partition([X|T],Y,T1,[X|Bs]):– partition(T,Y,T1,Bs). /* в противном случае дописываем его в четвертый аргумент */
Прежде чем перейти к изучению следующего алгоритма сортировки, решим одну вспомогательную задачу.
Пусть у нас есть два упорядоченных списка, и мы хотим объединить их элементы в один список так, чтобы объединенный список также остался отсортированным.
Идея реализации предиката, осуществляющего слияние двух отсортированных списков с сохранением порядка, довольно проста. Будем на каждом шаге сравнивать головы наших упорядоченных списков и ту из них, которая меньше, будем переписывать в результирующий список. И так до тех пор, пока один из списков не закончится. Когда один из списков опустеет, нам останется дописать остатки непустого списка к уже построенному итогу. В результате получим список, состоящий из элементов двух исходных списков, причем элементы его расположены в нужном нам порядке.
Создадим предикат (назовем его fusion) реализующий приведенное описание. Так как мы не знаем, какой из списков опустеет раньше, нам необходимо "гнать" рекурсию сразу по обоим базовым спискам. У нас будет два факта — основания рекурсии, которые будут утверждать, что если мы сливаем некий список с пустым списком, то в итоге получим, естественно, тот же самый список. Причем этот факт имеет место и в случае, когда первый список пуст, и в случае, когда пуст второй список.
Шаг рекурсии нам дадут два правила: первое будет утверждать, что если голова первого списка меньше головы второго списка, то именно голову первого списка и нужно дописать в качестве головы в результирующий список, после чего перейти к слиянию хвоста первого списка со вторым. Результат этого слияния будет хвостом итогового списка. Второе правило, напротив, будет дописывать голову второго списка в качестве головы результирующего списка, сливать первый список с хвостом второго списка. Итог этого слияния будет хвостом объединенного списка.
fusion(L1,[ ],L1):–!. /* при слиянии списка L1 с пустым списком получаем список L1 */ fusion([ ],L2,L2):–!. /* при слиянии пустого списка со списком L2 получаем список L2 */ fusion([H1|T1],[H2|T2],[H1|T]):– H1<H2,!, /* если голова первого списка H1 меньше головы второго списка H2 */ fusion(T1, [H2|T2],T). /* сливаем хвост первого списка T1 со вторым списком [H2|T2] */ fusion(L1, [H2|T2],[H2|T]):– fusion(L1,T2,T). /* сливаем первый список L1 с хвостом второго списка T2 */
Теперь можно перейти к изучению алгоритма сортировки слияниями.
Пузырьковая сортировка
Идея этого метода заключается в следующем. На каждом шаге сравниваются два соседних элемента списка. Если оказывается, что они стоят неправильно, то есть предыдущий элемент меньше следующего, то они меняются местами. Этот процесс продолжаем до тех пор, пока есть пары соседних элементов, расположенные в неправильном порядке. Это и будет означать, что список отсортирован.
Аналогия с пузырьком вызвана тем, что при каждом проходе минимальные элементы как бы "всплывают" к началу списка.
Реализуем пузырьковую сортировку посредством двух предикатов. Один из них, назовем его permutation, будет сравнивать два первых элемента списка и в случае, если первый окажется больше второго, менять их местами. Если же первая пара расположена в правильном порядке, этот предикат будет переходить к рассмотрению хвоста.
Основной предикат bubble будет осуществлять пузырьковую сортировку списка, используя вспомогательный предикат permutation.
permutation([X,Y|T],[Y,X|T]):– X>Y,!. /* переставляем первые два элемента, если первый больше второго */ permutation([X|T],[X|T1]):– permutation(T,T1). /*переходим к перестановкам в хвосте*/ bubble(L,L1):– permutation(L,LL), /* вызываем предикат, осуществляющий перестановку */ !, bubble(LL,L1). /* пытаемся еще раз отсортировать полученный список */ bubble(L,L). /* если перестановок не было, значит список отсортирован */
Но наш пузырьковый метод работает только до тех пор, пока есть хотя бы пара элементов списка, расположенных в неправильном порядке. Как только такие элементы закончились, предикат permutation терпит неудачу, а bubble переходит от правила к факту и возвращает в качестве второго аргумента отсортированный список.
Модифицируйте предикат, вычисляющий сумму элементов списка так, чтобы он вычислял произведение элементов списка.Модифицируйте алгоритм сортировки выбором так, чтобы он был основан на выборе максимального элемента списка и приписывании его в конец.Измените предикаты, реализующие алгоритм сортировки вставкой, чтобы список получился упорядоченным по невозрастанию.Реализуйте предикат avg без использования предикатов summa и length.Измените предикаты, реализующие алгоритм пузырьковой сортировки, чтобы в итоге список получился упорядоченным по невозрастанию.Реализуйте предикат min_list без использования предиката min.Внесите изменения в предикат choice, реализующий алгоритм сортировки выбором, чтобы он был основан на выборе максимального элемента списка и приписывании его в конец списка.

Сортировка слияниями
Метод слияний — один из самых "древних" алгоритмов сортировки. Его придумал Джон фон Нейман еще в 1945 году. Идея этого метода заключается в следующем. Разобьем список, который нужно упорядочить, на два подсписка. Упорядочим каждый из них этим же методом, после чего сольем упорядоченные подсписки обратно в один общий список.
Для начала создадим предикат, который будет делить исходный список на два. Он будет состоять из двух фактов и правила. Первый факт будет утверждать, что пустой список можно разбить только на два пустых подсписка. Второй факт будет предлагать разбиение одноэлементного списка на тот же одноэлементный список и пустой список. Правило будет работать в случаях, не охваченных фактами, т.е. когда упорядочиваемый список содержит не менее двух элементов. В этой ситуации мы будем отправлять первый элемент списка в первый подсписок, второй элемент — во второй подсписок, и продолжать распределять элементы хвоста исходного списка.
splitting([],[],[])./* пустой список можно расщепить только на пустые подсписки */ splitting([H],[H],[]). /* одноэлементный список разбиваем на одноэлементный список и пустой список */ splitting([H1,H2|T],[H1|T1],[H2|T2]):– splitting(T,T1,T2). /* элемент H1 отправляем в первый подсписок, элемент H2 — во второй подсписок, хвост T разбиваем на подсписки T1 и T2 */
Теперь можно приступать к записи основного предиката, который, собственно, и будет осуществлять сортировку списка. Он будет состоять из трех предложений. Первое будет декларировать очевидный факт, что при сортировке пустого списка получается пустой список. Второе утверждает, что одноэлементный список также уже является упорядоченным. В третьем правиле будет содержаться суть метода сортировки слиянием. Вначале список расщепляется на два подсписка с помощью предиката splitting, затем каждый из них сортируется рекурсивным вызовом предиката fusion_sort, и, наконец, используя предикат fusion, сливаем полученные упорядоченные подсписки в один список, который и будет результатом упорядочивания элементов исходного списка.
Запишем изложенные выше соображения.
fusion_sort([],[]):–!./* отсортированный пустой список остается пустым списком */ fusion_sort([H],[H]):–!. /* одноэлементный список упорядочен */ fusion_sort(L,L_s):– splitting(L,L1,L2), /* расщепляем список L на два подсписка */ fusion_sort(L1,L1_s), /* L1_s — результат сортировки L1 */ fusion_sort(L2,L2_s), /* L2_s — результат сортировки L2 */ fusion(L1_s,L2_s,L_s). /* сливаем L1_s и L2_s в список L_s */
Фактически этот алгоритм при прямом проходе дробит список на одноэлементные подсписки, после чего на обратном ходе рекурсии сливает их двухэлементные списки. На следующем этапе сливаются двухэлементные списки и т.д. На последнем шаге два подсписка сливаются в итоговый, отсортированный список.
В качестве завершения темы сортировки разработаем предикат, который будет проверять, является ли список упорядоченным. Это совсем не сложно. Для того чтобы список был упорядоченным, он должен быть либо пустым, либо одноэлементным, либо любые два его соседних элемента должны быть расположены в правильном порядке. Запишем эти рассуждения.
sorted([ ]). /* пустой список отсортирован */ sorted([_])./* одноэлементный список упорядочен */ sorted([X,Y|T]):– X<=Y, sorted([Y|T]). /* список упорядочен, если первые два элемента расположены в правильном порядке и список, образованный вторым элементом и хвостом исходного, упорядочен */
Сортировка списков
В этой лекции речь пойдет о списках, элементами которых являются числа. Хотя в большинстве задач, которые будут рассматриваться, неважно, к какому домену относятся элементы списка, для определенности будем считать, что это целые числа.
Таким образом, списки, с которыми мы планируем работать, могут быть представлены в разделе описания доменов примерно следующим образом:
DOMAINS listI = integer*
Для разминки решим несложный пример.
Пример. Создадим предикат, позволяющий вычислить сумму элементов списка.
Решение будет напоминать подсчет количества элементов списка. Отличаться они будут шагом рекурсии. При подсчете количества элементов нам было неважно, чему равен первый элемент списка, мы просто добавляли единицу к уже подсчитанному количеству элементов хвоста. При вычислении суммы нужно будет учесть значение головы списка.
Так как в пустом списке элементов нет, сумма элементов пустого списка равна нулю. Для вычисления суммы элементов непустого списка нужно к сумме элементов хвоста добавить первый элемент списка. Запишем эту идею:
sum([], 0). /* сумма элементов пустого списка равна нулю */ sum([H|T], S) :– sum(T, S_T), /* S_T — сумма элементов хвоста */ S = S_T + H. /* S — сумма элементов исходного списка */
Попробуйте самостоятельно изменить этот предикат так, чтобы он вычислял не сумму элементов списка, а их произведение.
Еще один вариант данного предиката можно написать, используя накопитель. В нем будем хранить уже насчитанную сумму. Начинаем с пустым накопителем. Переходя от вычисления суммы непустого списка к вычислению суммы элементов его хвоста, будем добавлять первый элемент к уже насчитанной сумме. Когда элементы списка будут исчерпаны (список опустеет), передадим "накопленную" сумму в качестве результата в третий аргумент.
Запишем:
sum_list([],S,S). /* список стал пустым, значит в накопителе — сумма элементов списка */ sum_list([H|T],N,S) :– N_T=H+N, /* N_T — результат добавления к сумме, находящейся в накопителе, первого элемента списка */ sum_list(T,N_T,S). /* вызываем предикат от хвоста T и N_T */
Если нам нужно вызвать предикат от двух аргументов, а не от трех, то можно добавить вспомогательный предикат:
sum2(L,S):– sum_list(L,0,S).
Последний вариант, в отличие от первого, реализует хвостовую рекурсию.
Разберем еще один простой пример.
Пример. Напишем предикат, вычисляющий среднее арифметическое элементов списка.
Конечно, можно, как всегда, опереться на рекурсию, но проще воспользоваться тем, что у нас уже есть предикаты, которые позволяют вычислить количество и сумму элементов списка. Для нахождения среднего нам достаточно будет сумму элементов списка разделить на их количество. Это можно записать следующим образом:
avg(L,A):– summa(L,S), /* помещаем в переменную S сумму элементов списка */ length(L,K), /* переменная K равна количеству элементов списка */ A=S/K. /* вычисляем среднее как отношение суммы к количеству */
Единственная проблема возникает при попытке найти среднее арифметическое элементов пустого списка. Если мы попытаемся вызвать цель avg([],A), то получим сообщение об ошибке "Division by zero" ("Деление на ноль"). Это произойдет, потому что предикат length([],K) конкретизирует переменную K нулем, а при попытке достижения третьей подцели A=S/K и произойдет вышеупомянутая ошибка. Можно посчитать это нормальной реакцией предиката. Раз в пустом списке нет элементов, значит, нет и их среднего арифметического. А можно изменить этот предикат так, чтобы он работал и с пустым списком.
Дабы обойти затруднение с пустым списком, добавим в нашу процедуру, в виде факта, информацию о том, что среднее арифметическое элементов пустого списка равно нулю. Полное решение будет выглядеть следующим образом.
avg([],0):–!. avg(L,A):– summa(L,S), length(L,K), A=S/K.
Описывая этот предикат в разделе описания предикатов PREDICATES, обратите внимание на то, что второй аргумент будет не целого типа, а вещественного (при делении одного целого числа на другое целое число частное может получиться нецелым).
Пример. Создадим предикат, находящий минимальный элемент списка.
Как обычно, наше решение будет рекурсивным. Но так как для пустого списка понятие минимального элемента не имеет смысла, базис рекурсии мы запишем не для пустого, а для одноэлементного списка. В одноэлементном списке, естественно, минимальным элементом будет тот самый единственный элемент списка ("при всем богатстве выбора другой альтернативы нет!").
Шаг рекурсии: найдем минимум из первого элемента списка и минимального элемента хвоста — это и будет минимальный элемент всего списка.
Оформим эти рассуждения:
min_list([X],X). /* единственный элемент одноэлементного списка является минимальным элементом списка */ min_list([H|T],M):– min_list(T,M_T), /* M_T — минимальный элемент хвоста */ min(H,M_T,M). /* M — минимум из M_T и первого элемента исходного списка */
Обратите внимание на то, что в правиле, позволяющем осуществить шаг рекурсии, использован предикат min, подобный предикату max, который был разобран нами в третьей лекции.
Слегка модифицировав предикат min_list (подставив в правило вместо предиката min предикат max и поменяв его название), получим предикат, находящий не минимальный, а максимальный элемент списка.
Перейдем теперь к более интересной задаче, а именно, к сортировке списков. Под сортировкой обычно понимают расстановку элементов в некотором порядке. Для определенности мы будем упорядочивать элементы списков по неубыванию. То есть, если сравнить любые два соседних элемента списка, то следующий должен быть не меньше предыдущего.
Существует множество алгоритмов сортировки. Заметим, что имеется два класса алгоритмов сортировки: сортировка данных, целиком расположенных в основной памяти (внутренняя сортировка), и сортировка файлов, хранящихся во внешней памяти (внешняя сортировка). Мы займемся исключительно методами внутренней сортировки.
Рассмотрим наиболее известные методы внутренней сортировки и выясним, как можно применить их для сортировки списков в Прологе.
Начнем с наиболее известного "пузырькового" способа сортировки. Его еще называют методом прямого обмена или методом простого обмена.
Сортировка вставкой
Теперь рассмотрим сортировку вставкой. Она основана на том, что если хвост списка уже отсортирован, то достаточно поставить первый элемент списка на его место в хвосте, и весь список будет отсортирован. При реализации этой идеи создадим два предиката.
Задача предиката insert — вставить значение (голову исходного списка) в уже отсортированный список (хвост исходного списка), так чтобы он остался упорядоченным. Его первым аргументом будет вставляемое значение, вторым — отсортированный список, третьим — список, полученный вставкой первого аргумента в нужное место второго аргумента так, чтобы не нарушить порядок.
Предикат ins_sort, собственно, и будет организовывать сортировку исходного списка методом вставок. В качестве первого аргумента ему дают произвольный список, который нужно отсортировать. Вторым аргументом он возвращает список, состоящий из элементов исходного списка, стоящих в правильном порядке.
ins_sort([ ],[ ]). /* отсортированный пустой список остается пустым списком */ ins_sort([H|T],L):– ins_sort(T,T_Sort), /* T — хвост исходного списка, T_Sort — отсортированный хвост исходного списка */ insert(H,T_Sort,L). /* вставляем H (первый элемент исходного списка)в T_Sort, получаем L (список, состоящий из элементов исходного списка, стоящих по неубыванию) */ insert(X,[],[X]). /* при вставке любого значения в пустой список, получаем одноэлементный список */ insert(X,[H|T],[H|T1]):– X>H,!, /* если вставляемое значение больше головы списка, значит его нужно вставлять в хвост */ insert(X,T,T1). /* вставляем X в хвост T, в результате получаем список T1 */ insert(X,T,[X|T]). /* это предложение (за счет отсечения в предыдущем правиле) выполняется, только если вставляемое значение не больше головы списка T, значит, добавляем его первым элементом в список T */
Сортировка выбором
Идея алгоритма сортировки выбором очень проста. В списке находим минимальный элемент (используя предикат min_list, который мы придумали в начале этой лекции). Удаляем его из списка (с помощью предиката delete_one, рассмотренного в предыдущей лекции). Оставшийся список сортируем. Приписываем минимальный элемент в качестве головы к отсортированному списку. Так как этот элемент был меньше всех элементов исходного списка, он будет меньше всех элементов отсортированного списка. И, следовательно, если его поместить в голову отсортированного списка, то порядок не нарушится.
Запишем:
choice([ ],[ ]). /* отсортированный пустой список остается пустым списком */ choice(L,[X|T]):– /* приписываем X (минимальный элемент списка L) к отсортированному списку T */ min_list(L,X), /* X — минимальный элемент списка L */ delete_one(X,L,L1), /* L1 — результат удаления первого вхождения элемента X из списка L */ choice(L1,T). /* сортируем список L1, результат обозначаем T */
Множества
В данной лекции мы попробуем реализовать некоторое приближение математического понятия "множество" в Прологе. Заметим, что в Прологе, в отличие от некоторых императивных языков программирования, нет такой встроенной структуры данных, как множество. И, значит, нам придется реализовывать это понятие, опираясь на имеющиеся стандартные домены. В качестве базового домена используем стандартный списковый домен, с которым мы работали на протяжении двух последних лекций.
Итак, что мы будем понимать под множеством? Просто список, который не содержит повторных вхождений элементов. Другими словами, в нашем множестве любое значение не может встречаться более одного раза.
На самом деле я не знаю ни одной реализации понятия множества, которая бы достаточно точно соответствовала этому математическому объекту. Наше подобие множества также, по большому счету, лишь отчасти будет приближаться к "настоящему" множеству.
Нам предстоит разработать предикаты, которые реализуют основные теоретико-множественные операции.
Начнем с написания предиката, превращающего произвольный список во множество, в том смысле, в котором мы договорились понимать этот термин. Для этого нужно удалить все повторные вхождения элементов. При этом мы воспользуемся предикатом delete_all, который был создан нами ранее, в седьмой лекции. Предикат будет иметь два аргумента: первый — исходный список (возможно, содержащий повторные вхождения элементов), второй — выходной (то, что остается от первого аргумента после удаления повторных вхождений элементов).
Предикат будет реализован посредством рекурсии. Базисом рекурсии является очевидный факт: в пустом списке никакой элемент не встречается более одного раза. По правде говоря, в пустом списке нет ни одного элемента, который встречался бы в нем хотя бы один раз, то есть в нем вообще нет элементов. Шаг рекурсии позволит выполнить правило: чтобы сделать из непустого списка множество (в нашем понимании этого понятия), нужно удалить из хвоста списка все вхождения первого элемента списка, если таковые вдруг обнаружатся.
После выполнения этой операции первый элемент гарантированно будет встречаться в списке ровно один раз. Для того чтобы превратить во множество весь список, остается превратить во множество хвост исходного списка. Для этого нужно только рекурсивно применить к хвосту исходного списка наш предикат, удаляющий повторные вхождения элементов. Полученный в результате из хвоста список с приписанным в качестве головы первым элементом и будет требуемым результатом (множеством, т.е. списком, образованным элементами исходного списка и не содержащим повторных вхождений элементов).
Закодируем наши рассуждения.
list_set([],[]). /* пустой список является списком в нашем понимании */ list_set ([H|T],[H|T1]) :– delete_all(H,T,T2), /* T2 — результат удаления вхождений первого элемента исходного списка H из хвоста T */ list_set (T2,T1). /* T1 — результат удаления повторных вхождений элементов из списка T2 */
Например, если применить этот предикат к списку [1,2,1,2,3, 2,1], то результатом будет список [1,2,3].
Заметим, что в предикате, обратном только что записанному предикату list_set и переводящем множество в список, нет никакой необходимости по той причине, что наше множество уже является списком.
Теперь займемся реализацией теоретико-множественных операций, таких как принадлежность элемента множеству, объединение, пересечение, разность множеств и т.д.
При реализации этих предикатов можно было бы воспользоваться предикатами, предназначенными для работы с обыкновенными списками, но в результате их применения могут получаться списки, содержащие некоторые элементы несколько раз, даже если исходные списки были множествами, в нашем понимании этого слова.
Можно, конечно, после каждого применения теоретико-множественной операции превращать полученный список обратно во множество применением вышеописанного предиката list_set, но это было бы не очень удобно. Вместо этого мы попробуем написать каждую из теоретико-множественных операций так, чтобы в результате ее работы гарантированно получалось множество.
Итак, приступим.
В качестве реализации операции принадлежности элемента множеству вполне можно использовать предикат member3, который мы разработали в седьмой лекции, когда только начинали знакомиться со списками. Напомним, что факт принадлежности элемента x множеству A в математике принято обозначать следующим образом: x

Для того чтобы найти мощность множества, вполне подойдет предикат length, рассмотренный нами в седьмой лекции. Напомним, что для конечного множества мощность — это количество элементов во множестве.
Пример. Реализуем операцию объединения двух множеств. На всякий случай напомним, что под объединением двух множеств понимают множество, элементы которого принадлежат или первому, или второму множеству. Обозначается объединение множеств A и B через A

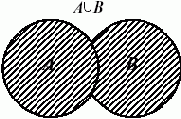
Рис. 9.1. Объединение множеств A и B
У соответствующего этой операции предиката должно быть три параметра: первые два — множества, которые нужно объединить, третий параметр — результат объединения двух первых аргументов. В третий аргумент должны попасть все элементы, которые входили в первое или второе множество. При этом нам нужно проследить, чтобы ни одно значение не входило в итоговое множество несколько раз. Такое могло бы произойти, если бы мы попытались, например, воспользоваться предикатом conc (который мы рассмотрели в седьмой лекции), предназначенным для объединения списков. Если бы какое-то значение встречалось и в первом, и во втором списках, то в результирующий список оно бы попало, по крайней мере, в двойном количестве. Значит, вместо использования предиката conc нужно написать новый предикат, применение которого не приведет к ситуации, в которой итоговый список уже не будет множеством за счет того, что некоторые значения будут встречаться в нем более одного раза.
Без рекурсии мы не обойдемся и здесь. Будем вести рекурсию по первому из объединяемых множеств.
Базис индукции: объединяем пустое множество с некоторым множеством. Результатом объединения будет второе множество. Шаг рекурсии будет реализован посредством двух правил. Правил получается два, потому что возможны две ситуации: первая — голова первого множества является элементом второго множества, вторая — первый элемент первого множества не входит во второе множество. В первом случае мы не будем добавлять голову первого множества в результирующее множество, она попадет туда из второго множества. Во втором случае ничто не мешает нам добавить первый элемент первого списка. Так как этого значения во втором множестве нет, и в хвосте первого множества оно также не может встречаться (иначе это было бы не множество), то и в результирующем множестве оно также будет встречаться только один раз.
Давайте запишем эти рассуждения:
union([ ],S2,S2). /* результатом объединения пустого множества со множеством S2 будет множество S2 */ union([H|T],S2,S):– member3(H,S2), /* если голова первого множества H принадлежит второму множеству S2, */ !, union(T,S2,S). /* то результатом S будет объединение хвоста первого множества T и второго множества S2 */ union([H |T],S2,[H|S]):– union(T,S2,S). /* в противном случае результатом будет множество, образованное головой первого множества H и хвостом, полученным объединением хвоста первого множества T и второго множества S2 */
Если объединить множество [1,2,3,4] со множеством [3,4,5], то в результате получится множество [1,2,3,4,5].
Пример. Теперь можно приступить к реализации операции пересечения двух множеств. Напомним, что пересечение двух множеств — это множество, образованное элементами, которые одновременно принадлежат и первому, и второму множествам. Обозначается пересечение множеств A и B через A

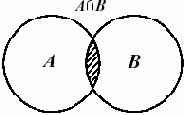
Рис. 9.2. Пересечение множеств A и B
У предиката, реализующего эту операцию, как и у предиката, осуществляющего объединение двух множеств, есть три параметра: первые два — исходные множества, третий — результат пересечения двух первых аргументов.
В итоговом множестве должны оказаться те элементы, которые входят и в первое, и во второе множество одновременно.
Этот предикат, наверное, будет немного проще объединения. Его мы также проведем рекурсией по первому множеству. Базис рекурсии: пересечение пустого множества с любым множеством будет пустым множеством. Шаг рекурсии так же, как и в случае объединения, разбивается на два случая в зависимости от того, принадлежит ли первый элемент первого множества второму. В ситуации, когда голова первого множества является элементом второго множества, пересечение множеств получается приписыванием головы первого множества к пересечению хвоста первого множества со вторым множеством. В случае, когда первый элемент первого множества не встречается во втором множестве, результирующее множество получается пересечением хвоста первого множества со вторым множеством.
Запишем это.
intersection([],_,[]). /* в результате пересечения пустого множества с любым множеством получается пустое множество */ intersection([H|T1],S2,[H|T]):– member3(H,S2), /* если голова первого множества H принадлежит второму множеству S2 */ !, intersection(T1,S2,T). /* то результатом будет множество, образованное головой первого множества H и хвостом, полученным пресечением хвоста первого множества T1 со вторым множеством S2 */ intersection([_|T],S2,S):– intersection(T,S2,S). /* в противном случае результатом будет множество S, полученное объединением хвоста первого множества T со вторым множеством S2 */
Если пересечь множество [1,2,3,4] со множеством [3,4,5], то в результате получится множество [3,4].
Пример. Следующая операция, которую стоит реализовать, — это разность двух множеств. Напомним, что разность двух множеств — это множество, образованное элементами первого множества, не принадлежащими второму множеству. Обозначается разность множеств A и B через A–B или A\B. В математических обозначениях это выглядит следующим образом: A\B={x|x

На рисунках разность множеств A и B (B и A) обозначена штриховкой.
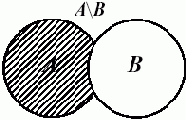
Рис. 9.3. Разность множеств A и B

Рис. 9.4. Разность множеств В и А
В этой операции, в отличие от двух предыдущих, важен порядок множеств. Если в объединении или пересечении множеств поменять первый и второй аргументы местами, результат останется прежним. В то время как при A={1,2,3,4}, B={3,4,5}, A\B={1,2}, но B\A={5}.
У предиката, реализующего разность, как и у объединения и пересечения, будет три аргумента: первый — множество, из которого нужно вычесть, второй — множество, которое нужно отнять, третий — результат вычитания из первого аргумента второго. В третий параметр должны попасть те элементы первого множества, которые не принадлежат второму множеству.
Рекурсия по первому множеству поможет нам реализовать вычитание. В качестве базиса рекурсии возьмем очевидный факт: при вычитании произвольного множества из пустого множества ничего кроме пустого множества получиться не может, так как в пустом множестве элементов нет. Шаг рекурсии, как и в случае объединения и пересечения, зависит от того, принадлежит ли первый элемент множества, из которого вычитают, множеству, которое вычитают. В случае, когда голова первого множества является элементом второго множества, разность множеств получается путем вычитания второго множества из хвоста первого. Когда первый элемент множества, из которого производится вычитание, не встречается в вычитаемом множестве, ответом будет множество, образованное приписыванием головы первого множества к результату вычитания второго множества из хвоста первого множества.
Запишем эти рассуждения.
minus([],_,[]). /* при вычитании любого множества из пустого множества получится пустое множество */ minus([H|T],S2,S):– member3(H,S2), /* если первый элемент первого множества H принадлежит второму множеству S2*/ !, minus(T,S2,S). /* то результатом S будет разность хвоста первого множества T и второго множества S2 */ minus([H|T],S2,[H|S]):– minus(T,S2,S). /* в противном случае, результатом будет множество, образованное первым элементом первого множества H и хвостом, полученным вычитанием из хвоста первого множества T второго множества S2 */
Можно попробовать реализовать пересечение через разность. Из математики нам известно тождество A
intersection2(A,B,S):– minus(A,B,A_B), /*A_B=A\B */ minus(A,A_B,S). /* S = A\A_B = A\(A\B) */
Проверка на примерах показывает, что этот предикат, так же, как, впрочем, и ранее созданный предикат intersection, возвращает именно те результаты, которые ожидаются.
Пример. Не помешает иметь предикат, позволяющий проверить, является ли одно множество подмножеством другого. В каком случае одно множество содержится в другом? В случае, если каждый элемент первого множества принадлежит второму множеству. Тот факт, что множество A является подмножеством множества B, обозначается через A




Предикат, реализующий данное отношение, будет иметь два параметра, оба входные. В качестве первого параметра будем указывать множество, включение которого мы хотим проверить. То множество, включение в которое первого аргумента нужно проверить, указывается в качестве второго параметра.
Решение, как обычно, будет рекурсивным. Базис рекурсии будет представлен фактом, утверждающим, что пустое множество является подмножеством любого множества. Шаг рекурсии: чтобы одно множество было подмножеством другого, нужно, чтобы его первый элемент принадлежал второму множеству (проверить это нам позволит предикат
member3, рассмотренный нами ранее в седьмой лекции), а его хвост, в свою очередь, должен быть подмножеством второго множества. Этих рассуждений достаточно, чтобы записать предикат, реализующий операцию включения.
subset([],_). /* пустое множество является подмножеством любого множества */ subset([H|T],S):– /* множество [H|T] является подмножеством множества S */ member3(H,S), /* если его первый элемент H принадлежит S */ subset(T,S). /* и его хвост T является подмножеством множества S */
Можно также определить это отношение, воспользовавшись уже определенными предикатами union и intersection.
Из математики известно, что A
Запишем эти математические соотношения на Прологе.
subsetU(A,B):– union(A,B,B). /* объединение множеств совпадает со вторым множеством */ subsetI(A,B):– intersection(A,B,A). /* пересечение множеств совпадает с первым множеством*/
Проверка на примерах показывает, что оба предиката, как и ранее созданный предикат subset, возвращают именно те результаты, какие и должны возвращать.
Используя только что написанный предикат, реализующий отношение включения множеств, можно создать предикат, осуществляющий проверку совпадения двух множеств. Напомним, что два множества A и B называются равными, если одновременно выполнено A
Напишем предикат, реализующий отношение равенства двух множеств.
equal(A,B):– /* множество A совпадает со множеством B, */ subset(A,B), /* если множество A содержится во множестве B */ subset(B,A). /* и множество B является подмножеством множества A*/
Убедимся, что множество [1,2,3] и множество [3,4,5] не равны, а множества [1,2,3] и [2,1,3] совпадают.
Если множество A содержится во множестве B, причем во множестве В имеются элементы, не принадлежащие множеству А, то говорят, что А — собственное подмножество множества В. Обозначается этот факт как A

Закодируем это отношение:
Prop_subset(A,B):– subset(A,B), /* множество A содержится во множестве B */ not(equal(A,B)). /* множества A и B не совпадают*/
Проверим, что множество [1,3] является собственным подмножеством множества [1,2,3], в отличие от множеств [1,4] и [2,1,3].
Пример. Рассмотрим еще одну операцию на множествах. Она называется симметрическая разность и, как видно из ее названия, в отличие от обычной разности, не зависит от порядка ее аргументов. Симметрической разностью двух множеств называется множество, чьи элементы либо принадлежат первому и не принадлежат второму множеству, либо принадлежат второму и не принадлежат первому множеству. Она не столь известна, как предыдущие рассмотренные нами операции, однако тоже имеет право на существование. Обозначается симметрическая разность множеств A и B через A?B. В математических обозначениях это выглядит следующим образом: A?B={x|(x

Рис. 9.5. Симметрическая разность множеств А и В
Например, при A={1,2,3,4}, B={3,4,5}, A?B=B?A={1,2,5}.
Воспользуемся тем, что симметрическую разность можно выразить через уже реализованные нами операции. А именно, A?B=(A\B)
Запишем это на Прологе:
Sim_minus(A,B,SM):– minus(A,B,A_B), /* A_B — это разность множеств A и B */ minus(B,A,B_A), /* B_A — это разность множеств B и A */ union(A_B,B_A,SM). /* SM — это объединение множеств A_B и B_A */
Убедимся, что симметрическая разность множеств [1,2,3,4] и [3,4,5] равна множеству [1,2,5], а симметрическая разность множеств [3,4,5] и [1,2,3,4] равна множеству [5,1,2]. Множество [1,2,5] с точностью до порядка элементов совпадает с множеством [5,1,2]. Таким образом, мы выяснили, что результат не зависит от порядка аргументов.
Пример. Еще одна операция, которую обычно используют при работе со множествами, это дополнение. Дополнением множества обычно называется множество, чьи элементы не принадлежат исходному множеству. Обозначается дополнение множества A через A.
В математических обозначениях это выглядит следующим образом: A={x|x
Давайте, для определенности, возьмем в качестве универсального множества множество цифр ({0,1,2,3,4,5,6,7,8,9}). Напишем дополнение над этим универсальным множеством.
Воспользуемся при этом очередным тождеством, которое известно в математике. А именно, тем, что A=U\A, где символ U обозначает универсальное множество. Операция разности двух множеств у нас уже реализована.
Закодируем вышеприведенную формулу на Прологе.
supp(A,D):– U=[0,1,2,3,4,5,6,7,8,9], minus(U,A,D). /* D — это разность универсального множества U и множества A */
Проверяем, что дополнение множества [1,2,3,4] равно множеству [0,5,6,7,8,9].
Имея дополнение, можно выразить операцию объединения через пересечение и дополнение, или, наоборот, операцию пересечения через объединение и дополнение, используя законы де Моргана (A
Запишем эти соотношения на Прологе.
unionI(A,B,AB):– supp(A,A_), /* A_ — это дополнение множества A */ supp(B,B_), /* B_ — это дополнение множества B */ intersection(A_,B_,A_B), /* A_B — это пересечение множеств A_ и B_ */ supp(A_B,AB). /* AB — это дополнение множества A_B */ intersectionU(A,B,AB):– supp(A,A_), /* A_ — это дополнение множества A */ supp(B,B_), /* B_ — это дополнение множества B */ union(A_,B_,A_B), /* A_B — это объединение множеств A_ и B_ */ supp(A_B,AB). /* AB — это дополнение множества A_B */
Проверка на примерах показывает, что оба предиката работают на множествах, являющихся подмножествами универсального множества (в нашем примере это множество {0,1,2,3,4,5,6,7,8,9}), как и ранее созданные предикаты union и intersection.
Самостоятельные задания
Создайте предикат, порождающий всевозможные перестановки исходного множества.Создайте предикат, порождающий всевозможные подмножества исходного множества.
Деревья
Данная лекция будет посвящена изучению и реализации на Прологе такой структуры данных, как деревья .
Начнем с маленького введения из теории графов , частным случаем которых являются деревья .
Обычно графом называют пару множеств: множество вершин и множество дуг (множество пар из множества вершин).Различают ориентированные и неориентированные графы . В ориентированном графе каждая дуга имеет направление (рассматриваются упорядоченные пары вершин). Графически обычно принято изображать вершины графа точками, а связи между ними - линиями, соединяющими точки-вершины.
Путем называется последовательность вершин, соединенных дугами. Для ориентированного графа направление пути должно совпадать с направлением каждой дуги, принадлежащей пути . Циклом называется путь , у которого совпадают начало и конец.
Две вершины ориентированного графа , соединенные дугой, называются отцом и сыном (или главной и подчиненной вершинами). Известно, что если граф не имеет циклов , то обязательно найдется хотя бы одна вершина, которая не является ничьим сыном. Такую вершину называют корневой. Если из одной вершины достижима другая, то первая называется предком , вторая - потомком .
Деревом называется граф , у которого одна вершина корневая, остальные вершины имеют только одного отца и все вершины являются потомками корневой вершины.
Листом дерева называется его вершина, не имеющая сыновей. Кроной дерева называется совокупность всех листьев . Высотой дерева называется наибольшая длина пути от корня к листу .
Нам будет удобно использовать следующее рекурсивное определение бинарного дерева : дерево либо пусто, либо состоит из корня , а также левого и правого поддеревьев, которые в свою очередь также являются деревьями .
В вершинах дерева может храниться информация любого типа. Для простоты в этой лекции будем считать, что в вершинах дерева располагаются целые числа. Тогда соответствующее этому определению описание альтернативного домена будет выглядеть следующим образом:
DOMAINS tree=empty;tr(i,tree,tree) /* дерево либо пусто, либо состоит из корня (целого числа), левого и правого поддеревьев, также являющихся деревьями */
Заметим, что идентификатор empty не является зарезервированным словом Пролога. Вместо него вполне можно употреблять какое-нибудь другое обозначение для пустого дерева . Например, можно использовать для обозначения дерева , не имеющего вершин, идентификатор nil, как в Лиспе, или void, как в Си. То же самое относится и к имени домена (и имени функтора): вместо tree (tr) можно использовать любой другой идентификатор.
Например, дерево

можно задать следующим образом:
tr(2,tr(7,empty, empty),tr(3,tree(4,empty,empty), tr(1,empty,empty))).
Теперь займемся написанием предикатов для реализации операций на бинарных деревьях .
Пример. Начнем с реализации предиката, который будет проверять принадлежность значения дереву . Предикат будет иметь два аргумента. Первым аргументом будет исходное значение, вторым - дерево , в котором мы ищем данное значение.
Следуя рекурсивному определению дерева , заметим, что некоторое значение принадлежит данному дереву , если оно либо содержится в корне дерева , либо принадлежит левому поддереву, либо принадлежит правому поддереву. Других вариантов нет.
Запишем это рассуждение на Прологе.
tree_member(X,tr(X,_,_)):-!. /* X - является корнем дерева */ tree_member(X,tr(_,L,_)):- tree_member(X,L),!. /* X принадлежит левому поддереву */ tree_member(X,tr(_,_,R)):- tree_member(X,R). /* X принадлежит правому поддереву */
Пример. Разработаем предикат, который будет заменять в дереве все вхождения одного значения на другое. У предиката будет четыре аргумента: три входных (значение, которое нужно заменять; значение, которым нужно заменять; исходное дерево ), четвертым - выходным - аргументом будет дерево , полученное в результате замены всех вхождений первого значения на второе.
Базис рекурсивного решения будет следующий. Из пустого дерева можно получить только пустое дерево . При этом абсолютно неважно, что на что мы заменяем. Шаг рекурсии зависит от того, находится ли заменяемое значение в корне дерева . Если находится, то нужно заменить корневое значение вторым значением, после чего перейти к замене первого значения на второе в левом и правом поддереве.
Если же в корне содержится значение, отличное от заменяемого, то оно должно остаться. Замену нужно произвести в левом и правом поддеревьях.
tree_replace(_,_,empty,empty). /* пустое дерево остается пустым деревом*/ tree_replace(X,Y,tr(X,L,R),tr(Y,L1,R1)):- /* корень содержит заменяемое значение X*/ !,tree_replace(X,Y,L,L1), /* L1 - результат замены в дереве L всех вхождений X на Y */ tree_replace(X,Y,R,R1). /* R1 - результат замены в дереве R всех вхождений X на Y */ tree_replace(X,Y,tr(K,L,R),tr(K,L1,R1)):- /* корень не содержит заменяемое значение X */ tree_replace(X,Y,L,L1), /* L1 - результат замены в дереве L всех вхождений X на Y */ tree_replace(X,Y,R,R1). /* R1 - результат замены в дереве R всех вхождений X на Y */
Пример. Напишем предикат, подсчитывающий общее количество вершин дерева . У него будет два параметра. Первый (входной) параметр - дерево , второй (выходной) - количество вершин в дереве .
Как всегда, пользуемся рекурсией. Базис: в пустом дереве количество вершин равно нулю. Шаг рекурсии: чтобы посчитать количество вершин дерева , нужно посчитать количество вершин в левом и правом поддереве, сложить полученные числа и добавить к результату единицу (посчитать корень дерева ).
Пишем:
tree_length (empty,0). /* В пустом дереве нет вершин */ tree_length(tr(_,L,R),N):- tree_length (L,N1), /* N1 - число вершин левого поддерева */ tree_length (R,N2), /* N2 - число вершин правого поддерева */ N=N1+N2+1. /* число вершин исходного дерева получается сложением N1, N2 и единицы */
Пример. Решим еще одну подобную задачу. Разработаем предикат, подсчитывающий не общее количество вершин дерева , а только количество листьев , т.е. вершин, не имеющих сыновей. Предикат будет иметь два параметра. Входной - исходное дерево , выходной - количество листьев дерева , находящегося в первом параметре.
Понятно, что, так как в пустом дереве нет вершин, в нем нет и вершин, являющихся листьями . Это первый базис рекурсии. Второй базис будет заключаться в очевидном факте, что дерево , состоящее из одной вершины, имеет ровно один лист .
Шаг: для того, чтобы посчитать количество листьев дерева , нужно просто сложить количество листьев в левом и правом поддереве.
Запишем:
tree_leaves(empty,0). /* в пустом дереве листьев нет */ tree_leaves(tr(_,empty,empty),1):-!. /* в дереве с одним корнем - один лист */ tree_leaves(tr(_,L,R),N):- tree_leaves(L,N1), /* N1 - количество листьев в левом поддереве */ tree_leaves(R,N2), /* N2 - количество листьев в правом поддереве */ N=N1+N2.
Пример. Создадим предикат, находящий сумму чисел, расположенных в вершинах дерева . Он будет иметь два аргумента. Первый - исходный список, второй - сумма чисел, находящихся в вершинах дерева , расположенного в первом аргументе.
Идея реализации будет очень простой и немного похожей на подсчет количества вершин. Базис рекурсии: сумма элементов пустого дерева равна нулю, потому что в пустом дереве нет элементов. Чтобы подсчитать сумму значений, находящихся в вершинах непустого дерева , нужно сложить сумму элементов, хранящихся в левом и правом поддереве, и не забыть добавить корневое значение.
На Прологе это записывается следующим образом:
tree_sum (empty,0). /* В пустом дереве вершин нет */ tree_sum(tr(X,L,R),N):- tree_sum (L,N1), /* N1 - сумма элементов левого поддерева */ tree_sum (R,N2), /* N2 - сумма элементов правого поддерева */ N=N1+N2+X. /* складываем N1, N2 и корневое значение */
Пример. Создадим предикат, позволяющий вычислить высоту дерева . Напомним, что высота дерева - это наибольшая длина пути от корня дерева до его листа . Предикат будет иметь два параметра. Первый (входной) - дерево , второй (выходной) - высота дерева , помещенного в первый параметр.
Базис рекурсии будет основан на том, что высота пустого дерева равна нулю. Шаг рекурсии - на том, что для подсчета высоты всего дерева нужно найти высоты левого и правого поддеревьев, взять их максимум и добавить единицу (учесть уровень, на котором находится корень дерева ). Предикат max (или max2), вычисляющий максимум из двух элементов, был разработан нами еще в третьей лекции.
Мы воспользуемся им при вычислении высоты дерева .
Получается следующее.
tree_height(empty,0). /* Высота пустого дерева равна нулю */ tree_height(tr(_,L,R),D) :- tree_height(L,D1), /* D1 - высота левого поддерева */ tree_height(R,D2), /* D2 - высота правого поддерева */ max(D1,D2,D_M), /* D_M - максимум из высот левого и правого поддеревьев */ D=D_M+1. /* D - высота дерева получается путем увеличения числа D_M на единицу*/
Существует особый вид бинарных деревьев - так называемые двоичные справочники . В двоичном справочнике все значения, входящие в левое поддерево, меньше значения, находящегося в корне , а все значения, расположенные в вершинах правого поддерева, больше корневого значения, а левое и правое поддеревья, в свою очередь, также являются двоичными справочниками . Такие деревья еще называют упорядоченными слева направо.
Пример. Усовершенствуем предикат tree_member для проверки принадлежности значения двоичному справочнику . Повысить эффективность этого предиката мы сможем, воспользовавшись тем, что в двоичном справочнике если искомое значение не совпадает с тем, которое хранится в корне , то его имеет смысл искать только в левом поддереве, если оно меньше корневого, и, соответственно, только в правом поддереве, если оно больше корневого значения.
Модифицированный предикат будет выглядеть следующим образом:
tree_member2(X,tr(X,_,_)):-!. /* X - корень дерева */ tree_member2(X,tr(K,L,_)):- X<K,!, tree_member2(X,L). /* X - принадлежит левому поддереву */ tree_member2(X,tr(K,_,R)):- X>K,!, tree_member2(X,R). /* X - принадлежит правому поддереву */
Пример. Создадим предикат, позволяющий добавить в двоичный справочник новое значение. При этом результирующее дерево должно получиться двоичным деревом . Предикат будет иметь три аргумента. Первым аргументом будет добавляемое значение, вторым - дерево , в которое нужно добавить данное значение, третьим - результат вставки первого аргумента во второй.
Решение, конечно, будет рекурсивным. На чем будет основано наше решение? Наша рекурсия будет основана на двух базисах и двух правилах.
Первый базис: если вставлять любое значение в пустое дерево , то в результате получим дерево , у которого левое и правое поддеревья - пустые, в корне записано добавляемое значение. Второй базис: если вставляемое значение совпадает со значением, находящимся в корневой вершине исходного дерева , то результат не будет отличаться от исходного дерева (в двоичном справочнике все элементы различны). Два правила рекурсии определяют, как нужно действовать, если исходное дерево непустое и его корневое значение отличается от вставляемого значения. В этой ситуации, если добавляемое значение меньше корневого, то его нужно добавить в левое поддерево, иначе - искать ему место в правом поддереве.
Запишем на Прологе реализацию этих рассуждений.
tree_insert(X,empty,tr(X,empty,empty)). /* вставляем X в пустое дерево, получаем дерево с X в корневой вершине,пустыми левым и правым поддеревьями */ tree_insert(X,tr(X,L,R),tr(X,L,R)):-!. /* вставляем X в дерево со значением X в корневой вершине, оставляем исходное дерево без изменений */ tree_insert(X,tr(K,L,R),tr(K,L1,R)):- X<K,!, tree_insert(X,L,L1). /* вставляем X в дерево с большим X элементом в корневой вершине, значит, нужно вставить X в левое поддерево исходногодерева */ tree_insert(X,tr(K,L,R),tr(K,L,R1)):- tree_insert(X,R,R1). /* вставляем X в дерево с меньшим X элементом в корневой вершине, значит, нужно вставить X в правое поддерево исходного дерева */
Можно обратить внимание на две особенности работы данного предиката. Во-первых, вершина, содержащая новое значение, будет добавлена в качестве нового листа дерева . Это следует из первого предложения нашей процедуры. Во-вторых, если добавляемое значение уже содержится в нашем двоичном справочнике , то оно не будет добавлено, дерево останется прежним, без изменений. Это следует из второго предложения процедуры, описывающей наш предикат.
Пример. Создадим предикат, генерирующий дерево , которое является двоичным справочником и состоит из заданного количества вершин, в которых будут размещены случайные целые числа.
Как можно было заметить, записывать деревья вручную довольно сложно. Этот предикат позволит нам автоматически создавать деревья с нужным количеством элементов. В дальнейшем он пригодится для проверки других предикатов, обрабатывающих деревья .
Предикат будет иметь два аргумента. Первый, входной, будет задавать требуемое количество элементов. Второй, выходной, будет равен сгенерированному дереву .
Решение будет, естественно, рекурсивным. Рекурсия по количеству вершин дерева . Базис рекурсии: нулевое количество вершин имеется только в пустом дереве . Если количество вершин должно быть больше нуля, то нужно (с помощью встроенного предиката random, рассмотренного в пятой лекции) сгенерировать случайное значение, построить дерево , имеющее вершин на одну меньше, чем итоговое дерево , вставить случайное значение в построенное дерево , воспользовавшись созданным перед этим предикатом tree_insert.
tree_gen(0,empty):-!. /* ноль вершин соответствует пустому дереву */ tree_gen (N,T):- random(100,X), /* X - случайное число из промежутка [0,100) */ N1= N-1, tree_gen (N1,T1), /* T1 - дерево, имеющее N-1 вершин */ tree_insert(X,T1,T). /* вставляем X в дерево T1 */
Обратите внимание на то, что, на самом деле, дерево , сгенерированное этим предикатом, не обязательно будет иметь столько вершин, сколько было указано в первом параметре. Если вспомнить реализацию предиката tree_insert, то можно обратить внимание на то, что в ситуации, когда вставляемое значение уже содержится в двоичном справочнике , оно не будет добавлено в дерево . Т.е. всякий раз, когда случайное число, генерируемое встроенным предикатом random, уже содержится в некоторой вершине дерева , оно не попадет в дерево , и, следовательно, итоговое дерево будет содержать на одну вершину меньше. Если во время построения двоичного справочника такая ситуация будет возникать несколько раз, то в итоговом дереве будет на соответствующее количество вершин меньше, чем можно было ожидать.
Если нам обязательно нужно по какой-то причине получить дерево , содержащее ровно столько вершин, сколько было указано в первом параметре, нужно модифицировать этот предикат.
Это можно сделать несколькими способами.
Первый вариант: можно модифицировать предикат, осуществляющий добавление значения в двоичный справочник так, чтобы в случае, когда вставляемое значение совпадало с корневым значением, генерировалось новое случайное число, после чего еще раз осуществлялась попытка вставки вновь сгенерированного значения в дерево .
Другой вариант: можно поменять местами вызов предикатов random и tree_gen и после генерации случайного числа проверять с помощью предиката tree_member2, не содержится ли это значение в уже построенном дереве . Если его там нет, значит, его можно спокойно вставить в двоичный справочник с помощью предиката tree_insert. Если же это значение уже содержится в одной из вершин дерева , значит, нужно сгенерировать новое случайное число, после чего опять проверить его наличие и т.д.
Надо заметить, что если задать требуемое количество вершин дерева , заведомо большее, чем первый аргумент предиката random (количество различных случайных чисел, генерируемых этим предикатом), мы получим зацикливание. Например, в приведенном выше примере вызывается предикат random(100,X). Этот предикат будет возвращать целые случайные числа из промежутка от 0 до 99. Различных чисел из этого промежутка всего сто. Следовательно, и справочник , генерируемый с помощью нашего предиката, может содержать не более ста вершин.
Эту проблему можно обойти, если сделать первый аргумент предиката random зависящим от заказанного числа вершин дерева (заведомо больше).
Пример. Далее логично заняться предикатом, который будет удалять заданное значение из двоичного справочника . У него будет три параметра. Два входных (удаляемое значение и исходное дерево ) и результат удаления первого параметра из второго.
Реализовать этот предикат оказывается не так просто, как хотелось бы. Без особых проблем можно написать базисы рекурсии для случая, когда удаляемое значение является корневым, а левое или правое поддерево пусты. В этом случае результатом будет, соответственно, правое или левое поддерево.
Шаг рекурсии для случая, когда значение, содержащееся в корне дерева , отличается от удаляемого значения, также реализуется без проблем. Нам нужно выяснить, меньше удаляемое значение корневого или больше. В первом случае перейти к удалению данного значения из левого поддерева, во втором - к удалению этого значения из правого поддерева. Проблема возникает, когда нам нужно удалить корневую вершину в дереве , у которого и левое, и правое поддеревья не пусты.
Есть несколько вариантов разрешения возникшей проблемы. Один из них заключается в следующем. Можно удалить из правого поддерева минимальный элемент (или из левого дерева максимальный) и заменить им значение, находящееся в корне . Так как любой элемент правого поддерева больше любого элемента левого поддерева, дерево , получившееся в результате такого удаления и замены корневого значения, останется двоичным справочником .
Для удаления из двоичного справочника вершины, содержащей минимальный элемент, нам понадобится отдельный предикат. Его реализация будет состоять из двух предложений. Первое будет задавать базис рекурсии и срабатывать в случае, когда левое поддерево пусто. В этой ситуации минимальным элементом дерева является значение, находящееся в корне , потому что, по определению двоичного справочника , все значения, находящиеся в вершинах правого поддерева, больше значения, находящегося в корневой вершине. И, значит, нам достаточно удалить корень , а результатом будет правое поддерево.
Второе предложение будет задавать шаг рекурсии и выполняться, когда левое поддерево не пусто. В этой ситуации минимальный элемент находится в левом поддереве и его нужно оттуда удалить. Так как минимальное значение нам потребуется, чтобы вставить его в корневую вершину, у этого предиката будет не два аргумента, как можно было бы ожидать, а три. Третий (выходной) аргумент будет нужен нам для возвращения минимального значения.
Запишем оба эти предиката.
Начнем со вспомогательного предиката, удаляющего минимальный элемент двоичного справочника .
tree_del_min(tr(X,empty,R), R, X). /* Если левое поддерево пусто, то минимальный элемент - корень, а дерево без минимального элемента - это правое поддерево.*/ tree_del_min(tr(K,L,R), tr(K,L1,R), X):- tree_del_min(L, L1, X). /* Левое поддерево не пусто, значит, оно содержит минимальное значениевсего дерева, которое нужно удалить */
Основной предикат, выполняющий удаление вершины из дерева , будет выглядеть следующим образом.
tree_delete(X,tr(X,empty,R), R):-!. /* X совпадает с корневым значением исходного дерева, левое поддерево пусто */ tree_delete (X,tr(X,L,empty), L):-!. /* X совпадает с корневым значением исходного дерева, правое поддерево пусто */ tree_delete (X,tr(X,L,R), tr(Y,L,R1)):- tree_del_min(R,R1, Y). /* X совпадает с корневым значением исходного дерева, причем ни левое, ни правое поддеревья не пусты */ tree_delete (X,tr(K,L,R), tr(K,L1,R)):- X<K,!, tree_delete (X,L,L1). /* X меньше корневого значения дерева */ tree_delete (X,tr(K,L,R), tr(K,L,R1)):- tree_delete (X,R,R1). /* X больше корневого значения дерева */
Пример. Создадим предикат, который будет преобразовывать произвольный список в двоичный справочник . Предикат будет иметь два аргумента. Первый (входной) - произвольный список, второй (выходной) - двоичный справочник , построенный из элементов первого аргумента.
Будем переводить список в дерево рекурсивно. То, что из элементов пустого списка можно построить лишь пустое дерево , даст нам базис рекурсии. Шаг рекурсии будет основан на той идее, что для того, чтобы перевести непустой список в дерево , нужно перевести в дерево его хвост, после чего вставить голову в полученное дерево .
То же самое на Прологе:
list_tree([],empty). /* Пустому списку соответствует пустое дерево */ list_tree([H|T],Tr):- list_tree(T,Tr1), /* Tr1 - дерево, построенное из элементов хвоста исходного списка */ tree_insert(H,Tr1,Tr). /* Tr - дерево, полученное в результате вставки головы списка в дерево Tr1 */
Пример. Создадим обратный предикат, который будет "сворачивать" двоичный справочник в список с сохранением порядка элементов.
Предикат будет иметь два аргумента. Первый (входной) - произвольный двоичный справочник , второй (выходной) - список, построенный из элементов первого аргумента.
tree_list(empty,[]). /* Пустому дереву соответствует пустой список */ tree_list(tr(K,L,R),S):- tree_list(L,T_L), /* T_L - список, построенный из элементов левого поддерева */ tree_list(R,T_R), /* T_L - список, построенный из элементов правого поддерева */ conc(T_L,[K|T_R],S). /* S - список, полученный соединением списков T_L и [K|T_R] */
Заметьте, что, используя предикаты list_tree и tree_list, можно отсортировать список, состоящий из различных элементов, переписав его в двоичный справочник , а затем переписав двоичный справочник обратно в список.
Запишем предикат, выполняющий сортировку списка, переписывая его в двоичный список и обратно.
sort_listT(L,L_S):- list_tree(L,T), /* T- двоичный справочник, построенный из элементов исходного списка L */ tree_list(T,L_S). /* L_S - список, построенный из элементов двоичного справочника T */
Так как в двоичном справочнике все элементы различны, при переписывании списка в двоичный справочник и обратно повторяющиеся элементы будут из него удалены. Неизменным останется количество элементов списка, только если все его элементы были различны.
Самостоятельные задания
Допишите генератор деревьев, чтобы выдаваемые им деревья имели количество вершин, точно соответствующее числу, указанному в его первом аргументе.Измените предикат, удаляющий значение из двоичного справочника, так, чтобы удалялся не минимальный элемент правого поддерева, а максимальный элемент левого поддерева.Создайте предикат, находящий максимальное из значений, находящихся в вершинах дерева.Создайте предикат, проверяющий, что дерево является двоичным справочником.Создайте предикат, переписывающий дерево в двоичный справочник.Создайте предикат, который будет находить среднеарифметическое значений, находящихся в вершинах дерева.Создайте предикат, который будет находить среднеарифметическое значений, находящихся в листьях дерева.Модифицируйте предикат, находящий сумму чисел, расположенных в вершинах дерева так, чтобы он суммировал только положительные числа.Измените его еще раз, чтобы он вычислял произведение отрицательных чисел.Модифицируйте предикат, "сворачивающий" двоичный справочник в список с сохранением порядка элементов, чтобы на выходе получалось два списка, содержащих, соответственно, положительные и отрицательные значения.Создайте предикат, подсчитывающий количество всех вершин данного дерева, значения которых принадлежат заданному диапазону.Создайте предикат, подсчитывающий количество всех вершин данного дерева заданной высоты.Создайте предикат, выводящий значения находящиеся в вершинах заданной высоты.Создайте предикат, проверяющий, является ли одно дерево поддеревом второго.Создайте предикат, выводящий дерево на экран (или в файл), расположив дерево следующим образом: корень находится слева, а листья справа.Создайте предикат, выводящий дерево на экран (или в файл), расположив дерево обычным образом: корень находится сверху, а листья снизу.
Самостоятельные задания
Создайте предикат, который будет находить последнюю позицию вхождения символа в строку.Создайте предикат, который подсчитает общее количество латинских букв в списке символов.Создайте предикат, который будет подсчитывать количество русских гласных букв в строке.Создайте предикат, находящий в исходной строке слово, в котором наибольшее количество русских гласных букв.Создайте предикат, который будет удалять из данной строки все вхождения заданного символа.Создайте предикат, удаляющий из данной строки все повторные вхождения символов.Создайте предикат, который продублирует вхождение каждого символа в строку.Создайте предикат, "переворачивающий" строку (меняющий в строке порядок символов на обратный).Создайте предикат, проверяющий, является ли данная строка палиндромом.Создайте предикат, составляющий список символов, которые входят одновременно в обе данных строки.Создайте предикат, находящий в исходной строке слово максимальной (минимальной) длины.Создайте предикат, преобразующий строку в список слов, состоящих из четного количества символов.Создайте предикат, преобразующий строку в список слов, которые упорядочены по длине.Создайте предикат, преобразующий строку в список слов, которые упорядочены в лексикографическом порядке.Создайте предикат, преобразующий исходную строку в строку, состоящую из первых букв слов первоначальной строки.Создайте предикат, преобразующий исходную строку в строку, состоящую из последних букв слов первоначальной строки.Создайте предикат, проверяющий правильность расстановки скобок в исходной строке.Создайте предикат, меняющий местами первую и последнюю буквы в каждом слове исходной строки.
Строки
В этой лекции мы займемся изучением строк. Такая структура данных, как строки, имеется практически в каждом языке программирования. Попробуем разобраться с тем, как можно обрабатывать строки в Прологе. На всякий случай напомню, что под строкой в Прологе понимается последовательность символов, заключенная в двойные кавычки.
Знакомство со спецификой обработки строк мы начнем с изучения некоторых встроенных предикатов Турбо Пролога, предназначенных для работы со строками, которыми нам предстоит в дальнейшем воспользоваться.
Начнем со встроенного предиката str_len, который предназначен для определения длины строки, т.е. количества символов, входящих в строку. Он имеет два аргумента: первый — строка, второй — количество символов. Имеется три варианта использования данного предиката.
Первый, наиболее естественный вариант использования этого предиката, когда первый аргумент связан, а второй свободен. В этом случае во второй аргумент будет помещено количество символов в первом аргументе.
Второй, также ожидаемый для стандартного "прологовского" предиката вариант использования этого предиката, когда оба аргумента связаны. В этом случае предикат будет успешен, если длина первого аргумента будет совпадать со вторым аргументом, и неуспешен в противном случае.
И, наконец, третий, не столь распространенный вариант использования, в случае, когда второй аргумент связан, а первый — свободен. В этой ситуации первый аргумент будет означен строкой, состоящей из пробелов, причем количество пробелов будет равно второму аргументу.
Следующий стандартный предикат concat предназначен, вообще говоря, для соединения двух строк, или, как еще говорят, для их конкатенации. У него три аргумента, каждый строкового типа, по крайней мере, два из трех аргументов должны быть связаны. Итого получаем четыре возможных шаблона или четыре варианта использования этого предиката.
Первый вариант, когда связаны первые два аргумента. В этом случае третий аргумент будет означен строкой, полученной приписыванием второго аргумента к первому.
Второй вариант, когда связанными оказались первый и третий аргументы. В этой ситуации второй аргумент будет означен строкой, при приписывании которой к первому аргументу получится третий аргумент (если, конечно, такая строка существует). Если такой строки не может быть, предикат будет неуспешен.
Третий вариант аналогичен второму, за исключением того, что связанными аргументами оказываются второй и третий, а свободным — первый. В этом случае, естественно, первый аргумент будет означен строкой, при приписывании к которой можно получить третий аргумент, если это вообще возможно. Иначе предикат терпит неудачу.
И, наконец, четвертый вариант возникает, когда все три аргумента означены. Предикат будет успешен, если при соединении первого аргумента со вторым получится третий аргумент, и неуспешен — в противном случае.
Следующие три встроенных предиката предназначены для "разделки" строки на составляющие.
Предикат frontchar служит для разделения исходной строки на первый символ и "хвост", состоящий из оставшихся после удаления первого символа, символов строки. Это чем-то напоминает представление списка в виде головы и хвоста. Причем первый и третий аргументы данного предиката принадлежат строковому домену, а второй — символьному. У этого предиката пять вариантов использования.
Первый вариант, когда первый аргумент связан, а второй и третий — свободны. В этом случае второй аргумент будет означен первым символом строки, а в третий аргумент будут записаны все символы исходной строки, начиная со второго.
Второй, также часто используемый вариант этого предиката, когда наоборот, первый аргумент свободен, а второй и третий — связаны. В этом случае в первый аргумент попадет строка, образованная приписыванием строки, находящейся в третьем аргументе, к символу, которым означен второй аргумент. Некий аналог конкатенации, но соединяются не две строки, а символ и строка.
Третий вариант получается, когда первый и второй аргументы означены, а третий нет. В этой ситуации в третий аргумент будут переписаны все символы первого аргумента, начиная со второго, в случае, если первый символ первого аргумента совпадает со вторым аргументом.
В противном случае предикат терпит неудачу.
Четвертый вариант похож на третий, но свободен второй аргумент, а связаны — первый и третий. В этом случае второй аргумент означивается первым символом первого аргумента, если оставшиеся символы первого аргумента образуют в точности третий аргумент. Иначе предикат будет неуспешен.
И, наконец, пятый вариант использования этого предиката возникает, когда все три его аргументы означены. В этом случае он будет истинен, если строка, хранящаяся в первом аргументе, совпадает со строкой, полученной приписыванием к символу из второго аргумента строки из третьего аргумента. В противном случае предикат будет ложен.
Предикат frontstr обобщает предикат frontchar в том смысле, что он тоже позволяет "откусить" от данной строки некоторое количество символов, но не обязательно один. Предикат имеет четыре параметра. В первом параметре указывается количество символов, которые копируются из второго параметра в третий, остатком второго параметра означивается четвертый аргумент. Как ни странно, этот предикат может использоваться только единственным описанным выше способом, а именно, первые два параметра у него входные, а третий и четвертый — выходные.
Если количество символов, указанных в первом параметре предиката frontstr, превышает длину строки из второго параметра, предикат терпит неудачу.
И, наконец, предикат fronttoken также дробит исходную строку, указанную в качестве первого параметра предиката, на две части. Во второй аргумент предиката попадает первый атом, входящий в строку, размещенную в первом аргументе, в третий — остаток входной строки, полученный после удаления из нее атома. Напомним, что атом — это или идентификатор, или беззнаковое число (целое или вещественное), или символ. У этого предиката существует пять вариантов использования.
Первый вариант, когда первый аргумент связан, а второй и третий — свободны. В этом случае второй аргумент будет означен первым атомом строки, находящейся в первом аргументе, а в третий аргумент будет записан остаток исходной строки.
Второй вариант использования этого предиката — когда, наоборот, первый аргумент свободен, а второй и третий — связаны. В таком случае этот предикат работает точно так же, как и конкатенация строк. В первый аргумент попадет строка, образованная приписыванием строки, находящейся в третьем аргументе, к строке, которой означен второй аргумент.
Третий вариант получается, когда первый и второй аргументы означены, а третий нет. В этой ситуации в третий аргумент будут переписаны все символы первого аргумента, остающиеся после удаления первого атома, в случае, если первый атом первого аргумента совпадает со вторым аргументом. В противном случае предикат терпит неудачу.
Четвертый вариант подобен третьему, но свободен второй аргумент, а связаны первый и третий. В этом случае второй аргумент означивается первым атомом первого аргумента, если оставшиеся символы первого аргумента совпадают со строкой, находящейся в третьем аргументе. Иначе предикат будет неудачен.
И, наконец, пятый вариант использования этого предиката возникает, когда все три его аргументы означены. В этом случае он будет истинным, если строка, хранящаяся в первом аргументе, совпадает со строкой, полученной приписыванием к атому из второго аргумента строки из третьего аргумента. В противном случае предикат будет ложным.
Для полноты картины следует еще упомянуть о предикате isname, который истинен, если его строковый аргумент является идентификатором, и ложен в противном случае.
Пример. Теперь попробуем применить рассмотренные предикаты. Создадим предикат, который будет преобразовывать строку в список символов. Предикат будет иметь два аргумента. Первым аргументом будет данная строка, вторым — список, состоящий из символов исходной строки.
Решение, как всегда, будет рекурсивным. Базис: пустой строке будет соответствовать пустой список. Шаг: с помощью встроенного предиката frontchar разобьем строку на первый символ и остаток строки, остаток строки перепишем в список, после чего добавим первый символ исходной строки в этот список в качестве первого элемента.
Запишем эту идею:
str_list("",[]). /* пустой строке соответствует пустой список */ str_list(S,[H|T]):– frontchar(S,H,S1), /* H — первый символ строки S, S1 — остаток строки */ str_list(S1,T). /* T — список, состоящий из символов, входящих в строку S1*/
Пример. Теперь попробуем немного модифицировать описанный предикат так, чтобы он преобразовывал строку не в список символов, а в список атомов.
Отличаться предыдущее решение будет заменой предиката frontchar на предикат fronttoken. Да еще надо не забыть в разделе описания предикатов заменить домен второго параметра со списка символов на список строк.
Запишем эту идею:
str_a_list("",[]). /* пустой строке по-прежнему соответствует пустой список */ str_a_list(S,[H|T]):– fronttoken(S,H,S1), /* H — первый атом строки S, S1 — остаток строки */ str_a_list(S1,T). /* T — список, состоящий из атомов, входящих в строку S1*/
Кстати, этот же предикат можно задействовать для создания списка слов, входящих в строку. Если слова разделены только пробелами, то он подойдет безо всяких изменений. Если же в строку могут входить еще и знаки препинания, то каждый из них попадет в итоговый список отдельным элементом. Для того чтобы получить список, элементами которого являются только слова, можно просто удалить из него все знаки препинания, что не сложно. К сожалению, работать эта идея будет только на английских словах. Русский текст этот предикат разобьет на отдельные символы, а не на слова.
Пример. Разработаем предикат, который будет преобразовывать список символов в строку. Предикат будет иметь два аргумента. Первым аргументом будет список символов, вторым — строка, образованная из элементов списка.
Базис рекурсии: пустому списку соответствует пустая строка. Шаг: если исходный список не пуст, то нужно перевести в строку его хвост, после чего, используя стандартный предикат frontchar, приписывать к первому элементу списка строку, полученную из хвоста исходного списка.
Запишем эту идею:
list_str([],""). /* пустой строке соответствует пустой список */ list_str([H|T],S):– list_str(T,S1), /* S1 — строка, образованная элементами списка T */ frontchar(S,H,S1). /* S — строка, полученная дописыванием строки S1 к первому элементу списка H */
Пример. Создадим предикат, который по строке и символу подсчитает количество вхождений этого символа в данную строку. Предикат будет иметь три аргумента: первые два — входные (строка и символ), третий — выходной (количество вхождений второго аргумента в первый).
Решение, как обычно, будет рекурсивным. Рекурсия по строке, в которой ведется подсчет количества вхождений данного символа. Если строка пустая, то не важно, вхождения какого символа мы считаем, все равно ответом будет ноль. Это базис. Шагов рекурсии будет два в зависимости от того, будет ли первым символом строки символ, вхождения которого мы считаем, или нет. В первом случае нужно подсчитать, сколько раз искомый символ встречается в остатке строки, и увеличить полученное число на единицу. Во втором случае (когда первый символ строки отличен от символа, который мы считаем) увеличивать полученное число не нужно. При расщеплении строки на первый символ и хвост нужно воспользоваться уже знакомым нам предикатом frontchar.
char_count("",_,0). /* Любой символ не встречается в пустой строке ни разу*/ char_count(S,C,N):– frontchar(S,C,S1),!, /* символ C оказался первым символом строки S, в S1 — оставшиеся символы строки S */ char_count(S1,C,N1), /* N1 — количество вхождений символа C в строку S1 */ N=N1+1. /* N — количество вхождений символа C в строку S получается из количества вхождений символа C в строку S1 добавлением единицы */ char_count(S,C,N):– frontchar(S,_,S1), /* первым символом строки S оказался символ, отличный от исходного символа C, в S1 — оставшиеся символы строки S */ char_count(S1,C,N). /* в этом случае количество вхождений символа C в строку S совпадает с количеством вхождений символа C в строку S1 */
Пример. Попробуем разработать предикат, который по символу и строке будет возвращать первую позицию вхождения символа в строку, если символ входит в строку, и ноль, если не входит. У предиката будет три параметра. Первые два — входные — символ и строка, третий — выходной — первая позиция вхождения первого параметра во второй параметр или ноль.
Не самая легкая задачка, но мы с ней справимся. Можно, конечно, записать в качестве базиса, что в пустой строке не встречаются никакие символы, но мы пойдем другим путем.
Вначале с помощью предиката frontchar разделим исходную строку на первый символ и остаток строки. Если первым символом строки окажется тот самый символ, позицию которого мы ищем, значит, больше ничего делать не нужно. Ответом будет единица. В этом случае нам даже неважно, какие символы оказались в хвосте строки, поскольку мы ищем первое вхождение данного символа в строку.
В противном случае, если первым символом исходной строки является какой-то символ, отличный от искомого, нам нужно искать позицию вхождения символа в остаток строки. Если искомый символ найдется в хвосте, позиция вхождения символа в исходную строку будет на единицу больше, чем позиция вхождения этого символа в остаток строки. Во всех остальных ситуациях наш символ не встречается в исходной строке и, следовательно, мы должны означить третий аргумент нулем.
Давайте попробуем записать эти рассуждения.
str_pos(C,S,1):– frontchar(S,C,_),!. /* Искомый символ C оказался первым символом данной строки S */ str_pos(C,S,N) :– frontchar(S,_,S1), /* S1 — состоит из всех символов строки S, кроме первого, который отличается от искомого символа C */ str_pos(C,S1,N1), /* N1 — это позиция, в которой символ C встречается первый раз в хвосте S1 или ноль*/ N1<>0,!, /* если позиция вхождения символа C в строку S1 не равна нулю, то есть если он встречается в строке S1, / N=N1+1. /* то, увеличив позицию его вхождения на единицу, мы получим позицию его вхождения в исходную строку */ str_pos(_,_,0). /* искомый символ не входит в данную строку */
Пример. Создадим предикат, который будет заменять в строке все вхождения одного символа на другой символ. У предиката будет четыре параметра. Первые три — входные (исходная строка; символ, вхождения которого нужно заменять; символ, которым нужно заменять первый символ); четвертым — выходным — параметром должен быть результат замены в первом параметре всех вхождений второго параметра на третий параметр.
Решение, как обычно, будет рекурсивным. Если строка пустая, значит, в ней нет символов, и, следовательно, заменять нечего. Результатом будет тоже пустая строка. Если же строка непустая, то мы должны разделить ее с помощью предиката frontchar на первый символ и строку, состоящую из остальных символов исходной строки.
Возможны два варианта. Либо первый символ исходной строки совпадает с тем, который нужно заменять, либо не совпадает.
В первом случае заменим все вхождения первого символа вторым символом в хвосте исходной строки, после чего, опять-таки с помощью предиката frontchar, приклеим полученную строку ко второму символу. В итоге в результирующей строке все вхождения первого символа будут заменены вторым символом.
Во втором случае, когда первый символ исходной строки не равен заменяемому символу, заменим в хвосте данной строки все вхождения первого символа на второй, после чего присоединим полученную строку к первому символу первоначальной строки.
str_replace("",_,_,""):–!. /* из пустой строки можно получить только пустую строку */ str_replace(S,C,C1,SO):– frontchar(S,C,S1),!, /* заменяемый символ C оказался первым символом строки S, S1 — остаток строки S */ str_replace(S1,C,C1,S2), /* S2 — результат замены в строке S1 всех вхождений символа C на символ C1 */ frontchar(SO,C1,S2). /* SO — результат склейки символа C1 и строки S2 */ str_replace(S,C,C1,SO):– frontchar(S,C2,S1), /* разделяем исходную строку S на первый символ C2 и строку S2, образованную всеми символами строки S, кроме первого */ str_replace(S1,C,C1,S2), /* S2 — результат замены в строке S1 всех вхождений символа C на символ C1 */ frontchar(SO,C1,S2). /* SO — результат соединения символа C1 и строки S2 */
Если нам понадобится предикат, который будет заменять не все вхождения первого символа на второй, а только первое вхождение первого символа, то нужно просто из первого правила удалить вызов предиката str_replace(S1,C,C1,S2).
Пример. Разработаем предикат, который будет удалять часть строки.
Предикат будет иметь четыре параметра. Первые три входные: первый — исходная строка, второй — позиция, начиная с которой нужно удалять символы, третий — количество удаляемых символов. Четвертым — выходным — параметром будет результат удаления из строки, указанной в первом параметре, символов, в количестве, указанном в третьем параметре, начиная с позиции, указанной во втором параметре.
Запишем решение этой задачи. Начнем с того, что при помощи стандартного предиката frontstr разобьем исходную строку на две подстроки. Во вторую попадут все символы, начиная с той позиции, с которой нужно удалять символы. В первую — начало исходной строки. Вторую подстроку еще раз разделим на две подстроки. В первую подстроку поместим те символы, которые нужно удалить. В этом месте можно будет воспользоваться анонимной переменной. Во вторую подстроку попадут оставшиеся символы остатка исходной строки. Чтобы получить ответ, нам остается только соединить первую подстроку исходной строки с последней подстрокой второй подстроки. Мы получим строку, состоящую в точности из тех символов, которые и должны были остаться в итоговой строке.
Давайте запишем эти немного путаные размышления в виде предложения на Прологе.
str_delete(S,I,C,SO) :– I1=I–1, /* I1 — количество символов, которые должны остаться в начале строки S */ frontstr(I1,S,S1,S2), /* S1 — первые I1 символов строки S, S2 — символы строки S, с I —го до последнего */ frontstr(C,S2,_,S3), /* S3 — последние символы строки S2 ( или, что тоже самое, последние символы строки S */ concat(S1,S3,SO). /* SO — строка, полученная соединением строк S1 и S3 */
Пример. Не помешает иметь в нашем хозяйстве предикат, который будет копировать часть строки. Предикат будет иметь четыре параметра. Первые три входные: первый — исходная строка, второй — позиция, начиная с которой нужно копировать символы, третий — количество копируемых символов. Четвертым — выходным — параметром будет результат копирования символов из строки, указанной в первом параметре, в количестве, указанном в третьем параметре, начиная с позиции, указанной во втором параметре.
Для решения этой задачи опять воспользуемся предикатом frontstr. Сначала получим хвост нашей строки, начиная с той позиции, c которой нужно копировать символы. Если после этого взять столько первых символов новой строки, сколько их нужно копировать, получим в точности ту подстроку исходной строки, которую требуется получить.
Зафиксируем наши рассуждения.
str_copy(S,I,C,SO) :– I1=I–1, /* I1 — это количество символов, расположенных в начале строки S, которые не нужно копировать */ frontstr(I1,S,_,S1), /* S1 — строка, состоящая из всех символов строки S, с I-го и до последнего */ frontstr(C,S1,SO,_). /* SO — первые C символов строки S1 */
Пример. Мы реализовали почти все операции, которые есть в большинстве стандартных алгоритмических языков типа Паскаля. Недостает, наверное, только предиката, который позволит нам вставить одну строку внутрь другой строки. Предикат будет иметь четыре параметра. Первые три входные: первый — вставляемая строка; второй — строка, в которую нужно вставить первый аргумент; третий — позиция, начиная с которой нужно вставить первый параметр во второй. Четвертым — выходным — параметром будет результат вставки строки, указанной в первом параметре, в строку, указанную во втором параметре, начиная с позиции, указанной в третьем параметре.
Для реализации этого предиката разделим, используя предикат frontstr, исходную строку на две подстроки. Во вторую поместим все символы, начиная с позиции, в которую должна быть вставлена вторая строка, в первую — оставшееся начало исходной строки. После этого припишем, используя конкатенацию, к полученной строке ту строку, которую нужно было вставить. Для получения окончательного результата нам остается только дописать вторую подстроку исходной строки.
Запишем:
str_insert(S,S1,I,SO) :– I1=I–1, /* I1 — это количество символов, расположенных в начале строки S, после которых нужно вставить новые символы */ frontstr(I1,S1,S1_1,S1_2), /* S1_1 — первые I1 символов строки S1, S1_2 — остаток строки S1, с I —го и до последнего */ concat(S1_1,S,S2), /* S2 — строка, полученная объединением строк S1_1 и S */ concat(S2,S1_2,SO). /* SO — строка, полученная слиянием строк S2 и S1_2 */
Пример. Создадим, для разнообразия, предикат, который будет подсчитывать количество имеющихся в строке цифр. Предикат будет иметь всего два аргумента. Входным аргументом будет строка, количество цифр в которой нужно подсчитать, выходным аргументом будет количество цифр в первом аргументе.
Для того чтобы реализовать этот предикат, нам придется разработать вспомогательный предикат, который будет означивать второй аргумент единицей (если его первый аргумент является цифрой) и нулем (в противном случае). Основной предикат будет использовать рекурсию по длине строки. Базисом будет очевидный факт, говорящий, что в пустой строке цифр нет. Непустую строку с помощью предиката frontchar разделим на первый символ и хвост. Подсчитаем количество цифр в хвосте, после чего к полученному числу добавим единицу, если первый символ — цифра, и ноль, если первый символ — не цифра.
Запишем оба предиката, вспомогательный и основной:
dig(C,1):– ‘0’<=C,C<=’9’,!. /* C — цифра*/ dig(_,0). count_digit("",0):–!. /* В пустой строке цифр нет */ count_digit(S,N):– frontchar(S,C,S2), /* C — первый символ строки S, S2 — хвост строки S */ dig(C,M), /* M равен единице, если C — цифра, и нулю — иначе */ count_digit(S2,N2), /* N2 — количество цифр в строке S2*/ N=N2+M. /* Количество цифр во всей строке больше на единицу, чем количество цифр в хвосте, если первый символ строки — цифра, и равно количеству цифр в хвосте — иначе */
Файлы
Данная лекция посвящена работе с файлами. Обычно файлом называют именованную (то есть имеющую имя) совокупность данных, записанных на диске. Файл состоит из компонентов (элементов). При чтении или записи файловая переменная перемещается к очередному компоненту и делает его доступным для обработки. Попробуем разобраться с тем, как можно работать с файлами в Прологе.
Для начала вспомним, что пользовательские файлы описываются в разделе описания доменов следующим образом:
file = <символическое имя файла1>;...; <символическое имя файлаN>
Обратите внимание, что при описании файловых доменов тип домена file располагается слева от равенства, а символические имена файлов — справа. Их еще называют внутренними или логическими именами файлов, в отличие от внешних или физических имен файлов. Символическое имя файла должно начинаться со строчной буквы.
Кроме пользовательских файлов, имеются стандартные файлы (или устройства), которые не нужно описывать в разделе описания доменов. Это:
stdin(стандартное устройство ввода);
stdout(стандартное устройство вывода);
stderror(стандартное устройство вывода сообщений об ошибках);
keyboard(клавиатура);
screen(монитор);
printer(параллельный порт принтера);
coml(последовательный порт).
По умолчанию стандартным устройством ввода является клавиатура, а стандартным устройством вывода — монитор. Чтобы начать работу с пользовательским файлом, его нужно открыть, а по завершении работы— закрыть. Стандартные устройства ввода/вывода, а также параллельный и последовательный порты открывать и закрывать не нужно.
Далее мы познакомимся со встроенными предикатами Турбо Пролога, с помощью которых можно осуществлять операции открытия и закрытия файлов, а также многие другие операции с файлами.
Начнем наше знакомство со встроенных предикатов, предназначенных для открытия файлов. Каждый из следующих четырех предикатов имеет два входных параметра. Первый параметр — это внутреннее символическое имя, указанное в разделе описания доменов, второй параметр — это строка, представляющая внешнее имя файла.
Предикат openread открывает файл только для чтения. Если файл с указанным внешним именем не будет обнаружен, предикат терпит неудачу и выводит соответствующее сообщение об ошибке.
Предикат openwrite открывает файл только для записи. Этот предикат создает на диске новый файл. Если файл с указанным внешним именем уже существует, он будет стерт. Если по какой-то причине файл не может быть создан, предикат терпит неудачу и выводит соответствующее сообщение об ошибке.
Предикат openappend открывает файл только для дозаписи в конец файла. Если файл с указанным именем не будет обнаружен, предикат выводит соответствующее сообщение об ошибке.
Предикат openmodify открывает файл для чтения и записи одновременно. Если файл с указанным именем не будет обнаружен, предикат выводит соответствующее сообщение об ошибке.
Для того чтобы проверить, существует ли файл с указанным именем в указанном месте, используется предикат existfile. Этот предикат имеет один аргумент. Предикат истинен, если файл с именем, указанным в качестве его единственного параметра, существует, и ложен — в противном случае.
Обратите внимание на то, что эти предикаты, связывают символическое имя файла с физическим именем открываемого файла. Поэтому, в отличие от других языков программирования, например Паскаля, нам нет необходимости перед операцией открытия файла проводить операцию связывания внутреннего и внешнего имен файла.
Поскольку символ "\", обычно используемый для разделения имен каталогов, применяется в Турбо Прологе для записи кодов символов, требуется использовать вместо одного обратного слэша два ("\\"). Например, чтобы указать путь "C:\Prolog\BIN", нужно записать строку "C:\\Prolog\\BIN".
Пример. Напишем замену для стандартного предиката openread. Предикат, который будет открывать файл на чтение (в случае, если он существует) и выводить сообщение о том, что файл с таким именем не найден (иначе). Этот предикат, как и предикат openread, будет иметь два аргумента.
Первым аргументом будет внутреннее символическое имя файла, вторым — строка, представляющая внешнее дисковое имя файла. Наша модификация предиката должна быть корректной и завершаться успехом в любом случае, вне зависимости от того, наличествует открываемый файл или отсутствует.
При реализации этого предиката воспользуемся встроенными предикатами: existfile для проверки существования; предикатом openread для открытия существующего файла на чтение; предикатом write для вывода сообщения.
openFile(F,N):– existfile(N),!, /* проверяем существование файла с именем N */ openread(F,N). /* связываем внешний файл с именем N с файловой переменной F и открываем его на чтение */ openFile(_,N):– write("Файл с именем ",N," не найден!"). /* выдаем сообщение, если предикат existfile потерпел неудачу */
Аналогичным образом можно модифицировать предикаты openappend и openmodify. Предикат openwrite можно модифицировать таким образом, чтобы при попытке открыть существующий файл на запись предикат вначале выдавал бы предупреждение о том, что содержимое этого файла будет уничтожено.
Для того чтобы корректно закрыть открытый файл, используется предикат closefile. В качестве его единственного параметра указывается символическое имя файла. Предикат в любом случае успешен, даже если соответствующий файл не был открыт.
С закрытым файлом можно работать только целиком. Он может быть переименован или удален с помощью предикатов renamefile и deletefile.
Предикат deletefile удаляет файл, указанный в качестве его единственного параметра. Если по какой-то причине удалить файл не получается, этот предикат выдает сообщение об ошибке.
Предикат renamefile изменяет имя файла, указанного в качестве его первого параметра, на имя, указанное в качестве его второго параметра. Если не существует файла, чье имя указано в первом параметре, или существует файл, чье имя указано во втором параметре, предикат выдаст сообщение об ошибке.
Предикат disk позволяет задать или узнать текущий диск и/или каталог, в зависимости от того, связан его единственный аргумент или свободен.
Кроме того, имеется предикат dir, который позволяет выбрать из списка файлы, соответствующие шаблону, указанному в качестве второго параметра этого предиката, находящиеся в каталоге, указанном в первом параметре. Выбранное нажатием клавиши Enter имя попадает в переменную, чье имя указано в качестве третьего параметра этого предиката.
Есть еще вариант этого предиката, имеющий три дополнительных входных параметра: четвертый — включает/отключает отображение подкаталогов; пятый — разрешает/запрещает изменять нажатием клавиши F4 шаблон, в соответствии с которым отображаются файлы; шестой — разрешает/запрещает отображение пути в заголовке окна. Ноль в четвертом, пятом и шестом параметрах означает запрет соответствующей опции, ненулевое значение — разрешение.
Предикат eof (сокращение от End Of File — "конец файла") успешен, если достигнут конец файла, в противном случае он неуспешен. В качестве его единственного входного параметра указывается символическое имя файла. Он обычно используется при организации рекурсивного считывания всех компонентов файла. Если его попытаться применить к файлу, открытому на запись, будет выдано сообщение об ошибке.
Содержимое файла можно рассматривать как поток компонентов. Каждый компонент файла находится на какой-то позиции. Для того чтобы узнать текущую позицию чтения или записи в файле, либо для того, чтобы изменить эту позицию, служит предикат filepos.
У него три аргумента. Первый аргумент — это символическое имя файла, второй — позиция внутри первого аргумента, которую нужно узнать или установить, третий — номер режима, который задает, откуда отсчитывается позиция.
Номер режима может принимать одно из трех значений: ноль, единица или двойка.
Если он равен нулю, то позиция считается от начала файла. Если он равен единице, позиция отсчитывается от текущей позиции. Этот режим имеет смысл только при означенном втором аргументе, когда предикат используется для изменения текущей позиции. Потому что если второй аргумент предиката не был означен, а третий аргумент равен единице, то во второй аргумент будет помещен ноль.
Смещение текущей позиции чтения или записи в файле относительно текущей позиции, естественно, равно нулю. Если же третий аргумент равен двойке, то позиция отсчитывается от конца файла.
Предикат может быть использован двояко. Если все три его аргумента связаны, то позиция, из которой осуществляется чтение или в которую производится запись, будет изменена в соответствии с числом, которым означен второй аргумент. Если его второй аргумент свободен, а первый и третий связаны, то второй аргумент будет означен текущей позицией чтения или записи.
Опишем ниже два предиката, служащие для перенаправления потоков ввода-вывода.
Для переопределения текущего устройства ввода или для того, чтобы узнать, какое устройства ввода является текущим, служит предикат readdevice. Этот предикат имеет один параметр, в качестве которого указывается символическое имя файла. Если предикат readdevice используется с несвязанным параметром, то он возвращает в него имя устройства, которое в настоящий момент является активным устройством чтения информации. Если его параметр означен именем открытого для чтения устройства, то этот предикат переопределит активное устройство ввода информации.
Предикат writedevice подобен предикату readdevice, однако используется для переопределения текущего устройства вывода или для получения имени текущего устройства вывода. Он также имеет один параметр, который может быть использован либо как входной, либо как выходной. В первом случае будет переопределено текущее устройство записи информации (должно быть открыто на запись или дозапись), во втором — параметр будет связан с именем активного устройства вывода.
Для записи данных в текущее устройство записи служит уже знакомый нам предикат write, который до этого мы использовали для вывода информации на монитор. Для чтения информации из активного устройства вывода — также уже знакомые нам предикаты readln (читает строку), readint (читает целое), readreal (читает вещественное число), readchar (читает символ), readterm (читает терм).
Имеется также предикат file_str, который целиком читает символы файла в строку или, наоборот, записывает содержимое строки в файл, в зависимости от того, свободен ли второй параметр этого предиката. Первым входным параметром этого предиката является символическое имя файла, а вторым — строка, в которую считывается содержимое файла или из которой записывается информация в него.
Предикат flush используется для принудительной записи в файл содержимого внутреннего буфера, выделенного для файла, указанного в его единственном параметре. Обычно он используется при работе с принтером.
И, наконец, последний встроенный предикат, о котором будет упомянуто в этой лекции, это предикат filemode. Он позволяет узнать или задать режим доступа к файлу. У этого предиката два параметра. Первый параметр — символическое имя файла, второй параметр задает или принимает режим работы с файлом, имя которого указано в первом параметре. Если второй параметр свободен, то он будет означен текущим режимом работы с файлом, а если связан, то указанный режим будет установлен. Второй параметр может принимать одно из двух значений. Значение ноль соответствует двоичному (бинарному) режиму работы с файлом, а значение единица — текстовому режиму. В текстовом режиме к строкам добавляются символы возврата каретки и перевода строки. Чаще используется текстовый режим, поскольку при работе в двоичном режиме данные можно записывать только посимвольно.
Рассмотрим на примерах, как можно использовать описанные предикаты.
Пример. Начнем с предиката, выводящего содержимое произвольного файла на экран. Предикат будет иметь один параметр строкового типа, представляющий собой внешнее дисковое имя файла.
При реализации этого предиката воспользуемся встроенными предикатами: existfile для проверки наличия файла на диске; openread для открытия существующего файла на чтение; readdevice для перенаправления ввода; eof для проверки, не исчерпали ли мы содержимое файла; readchar для чтения символов из файла, write для вывода прочитанного символа на экран.
Сначала напишем вспомогательный предикат, который будет читать символы из файла и выводить их на экран до тех пор, пока не будет достигнут конец файла.
Основной предикат будет проверять существование файла, указанного в качестве его параметра. Если файла с таким именем не существует, будет выдано соответствующее сообщение. Если файл с указанным именем существует, откроем его на чтение предикатом openread и определим его в качестве текущего устройства ввода информации, используя предикат readdevice. Далее воспользуемся нашим вспомогательным предикатом для вывода содержимого файла на экран. Закроем файл предикатом closefile. Сделаем текущим устройством чтения клавиатуру, воспользовавшись предикатом readdevice. В принципе, можно на этом остановиться, а можно организовать паузу до нажатия любой клавиши предикатом readchar(_). До этого неплохо бы вывести сообщение о том, что работа будет продолжена после нажатия любой клавиши.
Так как это — наш первый опыт работы с файлами в Прологе, приведем всю программу целиком, со всеми разделами. В разделе описания внутренней цели организуем ввод имени файла и вызов основного предиката.
DOMAINS /* раздел описания доменов */ file = f /* f — внутреннее имя файла */ PREDICATES /* раздел описания предикатов */ write_file(file) writeFile(string) CLAUSES /* раздел описания предложений */ write_file(f):– not(eof(f)),!, /* если файл f еще не закончился */ readchar(C), /* читаем из него символ */ write(C," "), /* выводим символ на экран*/ write_file(f). /* продолжаем процесс */ write_file(_). /* это предложение нужно, чтобы предикат не потерпел неудачу в случае, когда будет достигнут конец файла */ writeFile(F_N):– existfile(F_N),!, /* убеждаемся в существовании файла с именем F_N */ openread(f,F_N), /* связываем внешний файл F_N с внутренним файлом f и открываем его на чтение */ readdevice(f), /* устанавливаем в качестве устройства чтения файл f */ write_file(f), /* вызываем предикат, выводящий на экран все символы файла f */ closefile(f), /* закрываем файл */ readdevice(keyboard), /* перенаправляем ввод на клавиатуру */ nl,nl, /* пропускаем строку */ write("Нажмите любую клавишу"), /* выводим сообщение на экран */ readchar(_)./* ждем нажатия любой клавиши */ writeFile(F_N):– write("Файл с именем ",F_N," не наден!"). /* выдаем сообщение, если предикат existfile потерпел неудачу */ GOAL /* раздел описания внутренней цели*/ write("Введите имя файла: "), readln(F_N), /* читаем название файла в переменную F_N */ writeFile(F_N).
Пример. Теперь создадим предикат, который будет формировать файл из символов, вводимых с клавиатуры. Предикат будет иметь один параметр, представляющий собой внутреннее имя файла.
Начнем реализацию предиката с того, что сделаем экран текущим устройством вывода информации, выведем пользователю предложение ввести символ, сообщим о том, какой символ будет завершать ввод. Прочитаем символ с клавиатуры, выведем его на экран и сравним с тем символом, который завершает ввод. Если символы совпадают, закроем файл. Иначе: сделаем текущим устройством записи файл, запишем символ в файл, вызовем основной предикат.
Еще раз процитируем программу целиком, а в дальнейшем будем приводить только основной предикат. В разделе описания внутренней цели организуем ввод имени файла, открытие файла на запись и вызов основного предиката.
DOMAINS file=f PREDICATES Readfile CLAUSES readfile:– writedevice(screen), /* назначаем текущим устройством записи экран */ write("Введите символ (# — конец ввода)"), nl, /* выводим сообщение */ readchar(C), /* читаем символ с клавиатуры */ write(C), /* дублируем символ на экран */ C<>'#',!, /* если это не #*/ writedevice(f), /* , то перенаправляем вывод в файл */ write(C), /* записываем символ в файл */ readfile. readfile:– closefile(f). /* если введенный символ оказался равен символу '#', то закрываем файл */ GOAL write("Введите имя файла: "), readln(F_N), /* читаем название файла в переменную F_N */ openwrite(f,F_N), /* связываем внешний файл F_N с внутренним файлом f и открываем его на запись */ readfile(f).
Попробуйте изменить эту программу так, чтобы в файл записывались с клавиатуры не символы, а целые строки. При этом не забудьте при записи строки в файл добавить символы конца строки и перевода каретки. Это можно сделать с помощью встроенного предиката nl или сцепив записываемую строку с двумя символами с кодами 13 и 10.
Пример. Запишем предикат, который будет выводить содержимое файла на экран и принтер. Предикат будет иметь один параметр, представляющий собой внутреннее имя файла.
Напишем только этот предикат, оставив "за кадром" проверку на существование внешнего файла, его открытие на чтение. Все это мы делали не раз. Наш предикат должен проверять, не достигнут ли конец файла. В случае достижения конца файла его нужно закрыть. Если мы еще не добрались до конца файла, читаем символ, используя предикат readchar. Выводим его на экран посредством предиката write, перенаправляем вывод на принтер предикатом writedevice, выводим символ на принтер, заставляем принтер немедленно напечатать символ, используя предикат flush, устанавливаем для последующего вывода символа текущим устройством записи информации экран. Повторяем этот процесс, пока не будут исчерпаны все символы исходного файла.
writeFile_to_scr_and_pr(f):– not(eof(f)),!, /* если файл f еще не закончился */ readchar(C), /* читаем из файла f символ в переменную C */ write(C), /* выводим символ C на экран */ writedevice(printer), /* устанавливаем текущим устройством записи принтер*/ write(C), /* выводим символ C на экран */ flush(printer), /* сбрасываем данные из буфера на принтер */ writedevice(screen), /* перенаправляем вывод на экран*/ writeFile_to_scr_and_pr(f). /* продолжаем */ writeFile_to_scr_and_pr:– closefile(f). /* закрываем файл f */
Обратите внимание на использование стандартного предиката flush. Как правило, принтер выводит данные на печать только тогда, когда будет заполнен его внутренний буфер. Предикат flush позволяет осуществить немедленный вывод на печатающее устройство накопленной в буфере информации.
Попробуйте изменить этот предикат так, чтобы чтение из файла и, соответственно, вывод на экран и принтер осуществлялись не посимвольно, а построчно. Для этого замените предикат readchar на предикат readln, а также не забудьте добавить символы конца строки и перевода каретки при выводе.
Пример. Напишем предикат, который будет переписывать компоненты одного файла в другой файл так, чтобы в итоговом файле все английские буквы были большими. У предиката будет два аргумента строкового типа.
Первым параметром будет внешнее имя исходного файла, вторым параметром — внешнее имя итогового файла.
Начнем с создания вспомогательного предиката, который будет читать из первого файла строки, переводить их символы в верхний регистр, используя встроенный предикат upper_lower, а полученные строки записывать во второй файл. Когда первый файл буден исчерпан, этот предикат должен закрыть оба файла.
Основной предикат будет проверять существование исходного файла. Если файла с указанным именем не существует, он должен вывести соответствующее сообщение. Если файл существует, он должен быть открыт на чтение. Итоговый файл должен быть открыт на запись, первый файл установлен в качестве текущего устройства чтения информации, второй — в качестве текущего устройства записи информации. После этого остается только вызвать вспомогательный предикат.
Запишем эти два предиката. Надеюсь, что недостающие разделы описаний читатели уже в состоянии дописать самостоятельно.
transform:– not(eof(f)),!, /* если файл f еще не закончился */ readln(S), /* читаем из файла f строку в переменную S */ upper_lower(S_U,S), /* S_U — результат преобразования всех символов строки S в верхний егистр */ write(S_U),nl, /* записываем строку S_U в файл f_o */ transform. /* продолжаем процесс */ transform:– closefile(f), /* закрываем файл f */ closefile(f_o). /* закрываем файл f_o */ upper_file(N_F,N_o_F):– existfile(N_F),!, /* проверяем существование файла с именем N_F */ openread(f,N_F), /* связываем внешний файл с именем N_F с внутренним файлом f и открываем его на чтение */ readdevice(f), /* устанавливаем в качестве текущего устройства чтения файл f */ openwrite(f_o,N_o_F), /* связываем внешний файл с именем N_o_F с внутренним файлом f и открываем его на запись */ writedevice(f_o), /* устанавливаем в качестве текущего устройства записи файл f_o */ transform. /* вызываем вспомогательный предикат */ upper_file(N_F,_):– write("Файл с именем ",N_F," не наден!"). /* выдаем сообщение, если предикат existfile был неуспешен */
Самостоятельные задания
Напишите замену для стандартного предиката openwrite, который будет открывать файл на запись, если файл существует, и выводить соответствующее сообщение, если он отсутствует.Напишите замену для стандартного предиката openmodify, который будет открывать файл на чтение и запись, если файл существует, и выводить соответствующее сообщение, если файл отсутствует.Напишите замену для стандартного предиката openappend, который будет открывать файл на дозапись, если файл существует, и выводить соответствующее сообщение, если он отсутствует.Создайте предикат, осуществляющий переписывание из одного файла, содержащего числа, в другой файл только тех чисел, которые являются четными.Создайте предикат, вычисляющий количество отрицательных чисел в файле.Создайте предикат, вычисляющий сумму чисел, хранящихся в файле.Создайте предикат, вычисляющий количество чисел, меньших среднего арифметического значения всех чисел в файле.Создайте предикат, формирующий из текста, хранящегося в файле, список слов, в которых имеются повторяющиеся символы.Создайте предикат, дополняющий все строки, хранящиеся в файле, символом "*" до самой длинной строки.
Самостоятельные задания
Напишите программу, моделирующую компьютерную версию англо-русского словаря. Пользователь должен иметь возможность получать перевод как русских, так и английских слов, а также добавлять в словарь новые слова.Напишите программу, моделирующую компьютерную версию географического справочника, содержащего информацию о столицах стран. Пользователь должен иметь возможность получать название столицы по названию страны, название страны по названию столицы, добавлять в справочник новую информацию, изменять существующую (например, в ситуации, когда столица "переезжает" в другой город). Напишите программу, моделирующую компьютерную версию расписания авиарейсов, содержащего информацию о номерах рейсов и соответствующих пунктах назначения. Пользователь должен иметь возможность: узнать название пункта прибытия самолета по номеру рейса, и наоборот, номер рейса по названию пункта прибытия; добавлять в справочник новую информацию о рейсах; изменять существующую и удалять устаревшую информацию.Напишите программу, моделирующую компьютерную версию книжного каталога, содержащего информацию о книгах, их авторах и т.д. Пользователь должен иметь возможность: узнать названия книг по фамилии автора, и наоборот, фамилию автора по названию книги; добавлять в каталог новую информацию о книгах; изменять существующую и удалять устаревшую информацию.
Внутренние (динамические) базы данных
В этой лекции мы начнем изучать работу с базами данных в Прологе.
С одной стороны, Пролог-программы не зря называют базами знаний. На Прологе легко реализуются реляционные базы данных, наиболее распространенные в настоящее время. Любая таблица реляционной базы данных может быть описана соответствующим набором фактов, где каждой записи исходной таблицы будет соответствовать один факт. Каждому полю будет соответствовать аргумент предиката, реализующего таблицу. Многие дистрибутивы Пролога содержат в качестве примера реализацию базовой части языка SQL. Можно сказать, что структура реляционных баз данных включается в структуру Пролог-программ.
С другой стороны, Турбо Пролог, на который мы все-таки ориентируемся в нашем курсе, имеет встроенные средства для работы с двумя типами баз данных: внутренними и внешними. Внутренние базы данных так называются потому, что они обрабатываются исключительно в оперативной памяти компьютера, в отличие от внешних баз данных, которые могут обрабатываться на диске или в памяти. Так как внутренние базы данных размещаются в оперативной памяти компьютера, конечно, работать с ними существенно быстрее, чем с внешними. С другой стороны, емкость оперативной памяти, как правило, намного меньше, чем емкость внешней памяти. Отсюда следует, что объем внешней базы данных может быть существенно больше объема внутренней базы данных. И если предполагается, что база может оказаться довольно большой, то следует использовать именно внешние базы данных.
Изучение внешних баз данных выходит за рамки данного курса.
В этой лекции мы займемся изучением внутренних или, как их еще называют, динамических баз данных.
Внутренняя база данных состоит из фактов, которые можно динамически, в процессе выполнения программы, добавлять в базу данных и удалять из нее, сохранять в файле, загружать факты из файла в базу данных. Эти факты могут использовать только предикаты, описанные в разделе описания предикатов базы данных.
DATABASE [ — <имя базы данных>] <имя предиката>(<имя домена первого аргумента>,..., < имя домена n-го аргумента>) ...
Если раздел описания предикатов базы данных в программе только один, то он может не иметь имени. В этом случае он автоматически получает стандартное имя dbasedom. В случае наличия в программе нескольких разделов описания предикатов базы данных только один из них может быть безымянным. Все остальные должны иметь уникальное имя, которое указывается после названия раздела DATABASE и тире. Когда объявлен раздел описания предикатов базы данных, компилятор внутренне объявляет соответствующий домен с таким же именем, как у этого раздела; это позволяет специальным предикатам обрабатывать факты как термы.
Описание предикатов базы данных совпадает с их описанием в разделе описания предикатов PREDICATES. Однако эти предикаты можно задействовать в качестве параметров встроенных предикатов, с которыми мы познакомимся чуть позже. Кроме того, факты, использующие эти предикаты, могут добавляться и удаляться во время выполнения программы.
Обратите внимание на то, что в базе данных могут содержаться только факты, а не правила вывода, причем факты базы данных не могут содержать свободных переменных. Это еще одно существенное отличие Турбо Пролога от классического Пролога, в котором во время работы программы можно добавлять и удалять не только факты, но и правила. Заметим, что в Visual Prolog, который является наследником Турбо Пролога, в названии раздела описания предикатов внутренней базы данных слово DATABASE заменено синонимом FACTS, что еще больше подчеркивает, что во внутренней базе данных могут храниться только факты, а не правила.
Давайте познакомимся со встроенными предикатами Турбо Пролога, предназначенными для работы с внутренней базой данных. Все рассматриваемые далее предикаты могут использоваться в варианте с одним или двумя аргументами. Причем одноаргументный вариант используется, если внутренняя база данных не имеет имени. Если же база поименована, то нужно использовать двухаргументный предикат, в котором второй аргумент — это имя базы.
Начнем с предикатов, с помощью которых во время работы программы можно добавлять или удалять факты базы данных.
Для добавления фактов во внутреннюю базу данных может использоваться один из трех предикатов assert, asserta или assertz. Разница между этими предикатами заключается в том, что предикат asserta добавляет факт перед другими фактами (в начало внутренней базы данных), а предикат assertz добавляет факт после других фактов (в конец базы данных). Предикат assert добавлен для совместимости с другими версиями Пролога и работает точно так же, как и assertz. В качестве первого параметра у этих предикатов указывается добавляемый факт, в качестве второго, необязательного — имя внутренней базы данных, в которую добавляется факт. Можно сказать, что предикаты assert и assertz работают с совокупностью фактов, как с очередью, а предикат asserta — как со стеком.
Для удаления фактов из базы данных служат предикаты retract и retractall. Предикат retract удаляет из внутренней базы данных первый с начала факт, который может быть отождествлен с его первым параметром. Вторым необязательным параметром этого предиката является имя внутренней базы данных.
Для удаления всех предикатов, соответствующих его первому аргументу, служит предикат retractall. Для удаления всех фактов из некоторой внутренней базы данных следует вызвать этот предикат, указав ему в качестве первого параметра анонимную переменную. Так как анонимная переменная сопоставляется с любым объектом, а предикат retractall удаляет все факты, которые могут быть отождествлены с его первым аргументом, все факты будут удалены из внутренней базы данных. Если вторым аргументом этого предиката указано имя базы данных, то факты удаляются из указанной базы данных. Если второй аргумент не указан, факты удаляются из единственной неименованной базы данных. Заметим, что предикат retractall может быть заменен комбинацией предикатов retract и fail следующим образом:
retractall2(Fact):– retract(Fact), fail. retractall2(_).
Для сохранения динамической базы на диске служит предикат save. Он сохраняет ее в текстовый файл с именем, которое было указано в качестве первого параметра предиката.
Если второй необязательный параметр был опущен, происходит сохранение фактов из единственной неименованной внутренней базы данных. Если было указано имя внутренней базы данных, в файл будут сохранены факты именно этой базы данных.
Факты, сохраненные в текстовом файле на диске, могут быть загружены в оперативную память командой consult. Первым параметром этого предиката указывается имя текстового файла, из которого нужно загрузить факты. Если второй параметр опущен, факты будут загружены в единственную неименованную внутреннюю базу данных. Если второй параметр указан, факты будут загружены в ту внутреннюю базу данных, чье имя было помещено во второй параметр предиката. Предикат будет неуспешен, если для считываемого файла недостаточно свободного места в оперативной памяти или если указанный файл не найден на диске, или если он содержит ошибки (ниже будет разъяснено чуть подробнее, какими они бывают).
Заметим, что сохраненная внутренняя база данных представляет собой обычный текстовый файл, который может быть просмотрен и/или изменен в любом текстовом редакторе. При редактировании или создании файла, который планируется применить для последующей загрузки фактов с использованием предиката consult, нужно учитывать, что каждый факт должен занимать отдельную строку. Количество аргументов и их тип должны соответствовать описанию предиката в разделе database. В файле не должно быть пустых строк, внутри фактов не должно быть пробелов, за исключением тех, которые содержатся внутри строк в двойных кавычках, других специальных символов типа конца строки, табуляции и т.д. Давайте на примере разберемся со всеми этими предикатами.
Пример. Напишем программу, реализующую компьютерный вариант телефонного справочника. Основное назначение этой не очень сложной программы — находить по фамилии человека его телефонный номер или, наоборот, по телефонному номеру — фамилию владельца телефона. У пользователя нашей программы должна быть возможность добавлять информацию в базу данных, а также удалять и изменять устаревшую информацию.
Приступим к реализации нашего проекта. Внутренняя база данных будет содержать факты, описывающие единственный предикат, имеющий два аргумента. Первым аргументом предиката будет фамилия человека, а вторым — его телефонный номер. Для упрощения программы будем считать, что соответствие между фамилиями и номерами телефонов взаимооднозначное, то есть каждой фамилии соответствует не более одного телефонного номера, и наоборот.
Сделаем так, чтобы при запуске программы появлялось меню, из которого пользователь мог выбрать, какое действие с телефонной базой он хотел бы осуществить. Реализуем пять операций:
Получение информации о телефонном номере по фамилии человека.Получение информации о фамилии абонента по телефонному номеру.Добавление новой записи в телефонную базу.Изменение существующей в телефонной базе записи.Удаление записи из телефонной базы.
Нужно учесть, что пользователь может ошибиться и нажать клавишу, не соответствующую ни одной из пяти указанных операций. После выполнения каждой из операций программа должна вернуться обратно в меню, чтобы у пользователя не было необходимости запускать программу заново, если ему нужно выполнить еще одно действие.
Кроме того, у пользователя должна быть возможность выйти из программы, не совершая никаких действий. При выходе из программы факты телефонной базы должны быть сохранены из оперативной памяти в файл на диске, а оперативная память очищена от ненужных фактов.
Эти действия выполняет следующее правило (символ '0' означает, что пользователь нажал соответствующую клавишу):
m('0'):– save("phones.ddb "), /* сохраняем телефонную базу в файл */ retractall(_)./* удаляем все факты из внутренней базы данных */
В начале работы программы факты из телефонной базы, хранящейся в файле на диске, должны загружаться во внутреннюю базу данных, в случае, если такой файл существует.
Предикат, предназначенный для выполнения этих действий, выглядит следующим образом:
start:– existfile("phones.ddb"),!, /* если существует файл с телефонной базой */ consult("phones.ddb "), /* , то загружаем факты во внутреннюю базу данных */ menu. /* и вызываем меню */ start:– menu. /* если такого файла еще нет, просто вызываем меню */
Если пользователь выбрал первую операцию, должен быть выдан телефонный номер абонента (если в телефонной базе имеется соответствующий факт) или сообщение о том, что в телефонной базе нет такой информации.
Это реализуют два приведенных ниже предиката.
m('1'):– write("Введите фамилию"), nl, /* выводим приглашение ввести фамилию */ readln(Name), /* читаем введенную фамилию в переменную Name */ name_phone(Name, Phone), /* вызываем предикат, который помещает в переменную Phone телефонный номер, соответствующий фамилии Name или сообщение об отсутствии информации */ write("Номер телефона: ",Phone), /* выводим значение переменной Phone */ readchar(_), /* ждем нажатия любой клавиши */ menu. /* возвращаемся в меню */ name_phone(Name,Phone):– phone(Name,Phone),!. name_phone(_,"Нет информации о телефонном номере"). /* если нужного факта во внутренней базе данных не нашлось, то вместо телефонного номера возвращаем соответствующее сообщение */
Если пользователь желает выполнить вторую операцию, то должна быть выведена фамилия абонента, если в нашей телефонной базе имеется соответствующий факт. Иначе выводится сообщение о том, что у нас нет такой информации.
Соответствующие предикаты будут выглядеть следующим образом:
m('2'):– write("Введите номер телефона"),nl, readln(Phone), phone_name(Name, Phone), write("Фамилия абонента: ",Name), readchar(_), menu. /* вызываем меню */ phone_name(Name,Phone):– phone(Name,Phone). phone_name("Нет информации о владельце телефона",_). /* если нужного факта во внутренней базе данных не нашлось, то вместо фамилии абонента возвращаем соответствующее сообщение */
Если пользователем была выбрана третья операция, то нужно дать ему возможность ввести фамилию и номер абонента, после чего добавить соответствующий факт в базу данных.
Это будет выглядеть следующим образом:
m('3'):– write("Введите фамилию"),nl, readln(Name), write("Введите номер телефона"),nl, readln(Phone), assert(phone(Name,Phone)), /* добавляем факт во внутреннюю базу данных */ menu. /* вызываем меню */
Если пользователь желает выполнить четвертую операцию, то нужно дать ему возможность ввести фамилию абонента и его новый телефонный номер, после чего удалить устаревшую информацию из телефонной базы (с помощью предиката retract) и добавить туда новую информацию (используя встроенный предикат assert).
Соответствующее этим рассуждениям предложение:
m('4'):– clearwindow, write("Введите фамилию"),nl, readln(Name), write("Введите новый номер телефона"),nl, readln(Phone), retract(phone(Name,_)), /* удаляем устаревшую информацию из внутренней базы данных */ assert(phone(Name,Phone)), /* добавляем новую информацию в телефонную базу */ menu. /* вызываем меню */
Если пользователем была выбрана пятая операция, то нужно узнать у него, например, номер (или фамилию) абонента, после чего удалить соответствующую информацию из внутренней базы данных, воспользовавшись предикатом retract.
Запишем это предложение:
m('5'):– write("Укажите номер телефона, запись о котором нужно удалить из телефонной базы"), nl, readln(Phone), retract(phone(_,Phone)), /* удаляем соответствующий факт из внутренней базы данных */ menu. /* вызываем меню */
Приведем полный текст программы.
DOMAINS /* раздел описания доменов */ name, number = String /* фамилию абонента и телефонный номер будем хранить в виде строк */ file=f /* файловый домен будем использовать для считывания с диска и записи на диск нашей телефонной базы */ DATABASE /* раздел описания предикатов внутренней базы данных */ phone(name, number) PREDICATES /* раздел описания предикатов */ name_phone(name, number) /* этот предикат находит номер телефона по фамилии абонента */ phone_name(name, number) /* этот предикат находит фамилию абонента по номеру телефона */ m(char) /* этот предикат реализует выполнение соответствующего пункта меню */ menu /* этот предикат реализует вывод меню и обработку выбора пользователя */ start /* этот предикат проверяет наличие файла с телефонной базой на диске и либо загружает факты из нее во внутреннюю базу данных, если такой файл существует, либо создает этот файл, если его не было */ CLAUSES /* раздел описания предложений */ name_phone(Name,Phone):– phone(Name,Phone),!.
name_phone(_,"Нет информации о телефонном номере"). /* если соответствующего факта во внутренней базе данных не нашлось, вместо телефонного номера возвращаем соответствующее сообщение */ phone_name(Name,Phone):– phone(Name,Phone). phone_name("Нет информации о владельце телефона",_). /* если соответствующего факта во внутренней базе данных не нашлось, вместо фамилии абонента возвращаем соответствующее сообщение */ menu:– clearwindow, /* очистка текущего окна */ write("1– Получение телефонного номера по фамилии "),nl, write("2 — Получение фамилии абонента по номеру телефона "),nl, write("3 — Добавление новой записи в телефонную базу."),nl, write("4 — Изменение номера абонента"),nl, write("5 — Удаление записи из телефонной базы"),nl, write("0 — Выйти"),nl, readchar(C), /* читаем символ с клавиатуры */ m(C). /* вызываем выполнение соответствующего пункта меню */ m('1'):– clearwindow, write("Введите фамлию"), nl, readln(Name), name_phone(Name, Phone), write("Номер телефона: ",Phone), readchar(_), menu. m('2'):– clearwindow, write("Введите номер телефона"),nl, readln(Phone), phone_name(Name, Phone), write("Фамилия абонента: ",Name), readchar(_), menu. m('3'):– clearwindow, write("Введите фамилию"),nl, readln(Name), write("Введите номер телефона"),nl, readln(Phone), assert(phone(Name,Phone)), /* добавляем факт во внутреннюю базу данных */ menu. m('4'):– clearwindow, write("Введите фамилию"),nl, readln(Name), write("Введите новый номер телефона"),nl, readln(Phone), retract(phone(Name,_)), /* удаляем устаревшую информацию из внутренней базы данных */ assert(phone(Name,Phone)), /* добавляем новую информацию в телефонную базу */ menu. m('5'):– clearwindow, write("Укажите номер телефона, запись о котором нужно удалить из телефонной базы"), nl, readln(Phone), retract(phone(_,Phone)), /* удаляем соответствующий факт из внутренней базы данных */ menu.
m('0'):– save("phones.ddb "), /* сохраняем телефонную базу в файл */ retractall(_)./* удаляем все факты из внутренней базы данных */ m(_):– menu. /* если пользователь по ошибке нажал клавишу, отличную от тех, реакция на которые предусмотрена, ничего плохого не произойдет, будет отображено меню еще раз */ start:– existfile("phones.ddb"),!, /* если файл с телефонной базой существует */ consult("phones.ddb "), /* загружаем факты во внутреннюю базу данных */ menu. /* вызываем меню */ start:– openwrite(f,"phones.ddb"), /* если файла с телефонной базой не существует, создаем его */ closefile(f), menu. /* вызываем меню */ GOAL /* раздел внутренней цели*/ Start
Листинг 13.1. Программа, реализующая компьютерный вариант телефонного справочника.
Пример. Другой распространенный вариант использования внутренних баз данных — это повышение эффективности программ за счет добавления уже вычисленных фактов в базу данных. При попытке вычислить предикат сначала проверяется, нет ли в базе данных уже вычисленного значения, и если оно там уже есть, то просто берется это значение. Если же ответа еще нет, он вычисляется обычным способом, после чего добавляется в базу данных для повторного использования. Эта техника еще называется мемоизация или табулирование.
Давайте разработаем табулированную версию предиката, вычисляющего число Фиббоначи по его номеру. В пятой лекции мы уже рассматривали предикат, вычисляющий числа Фиббоначи. Выглядел он следующим образом:
fib(0,1):–!. /* нулевое число Фиббоначи равно единице */ fib(1,1):–!. /* первое число Фиббоначи равно единице */ fib(N,F) :– N1=N–1, fib(N1,F1), /* F1 это N–1-е число Фиббоначи */ N2=N–2, fib(N2,F2), /* F2 это N–2-е число Фиббоначи */ F=F1+F2. /* N-е число Фиббоначи равно сумме N–1-го числа Фиббоначи и N–2-го числа Фиббоначи */
Чем плох этот вариант предиката, вычисляющего числа Фиббоначи? Получается, что при вычислении очередного числа происходит многократное перевычисление предыдущих чисел Фиббоначи, что не может не приводить к замедлению работы программы.
Изменим нашу программу следующим образом: добавим в нее раздел описания предикатов внутренней базы данных. В этот раздел добавим описание одного-единственного предиката, который будет иметь два аргумента. Первый аргумент — это номер числа Фиббоначи, а второй аргумент — само число.
Сам предикат, вычисляющий числа Фиббоначи, будет выглядеть следующим образом. Базис индукции для первых двух чисел Фиббоначи оставим без изменений. Для шага индукции добавим еще одно правило. Первым делом будем проверять внутреннюю базу данных на предмет наличия в ней уже вычисленного числа. Если оно там есть, то никаких дополнительных вычислений проводить не нужно. Если же числа в базе данных не окажется, вычислим его по обычной схеме как сумму двух предыдущих чисел, после чего добавим соответствующий факт в базу данных.
Попробуем придать этим рассуждениям некоторое материальное воплощение:
fib2(0,1):–!. /* нулевое число Фиббоначи равно единице */ fib2(1,1):–!. /* первое число Фиббоначи равно единице */ fib2(N,F):– fib_db(N,F),!. /* пытаемся найти N-е число Фиббоначи среди уже вычисленных чисел, хранящихся во внутренней базе данных */ fib2(N,F) :– N1=N–1, fib2(N1,F1), /* F1 это N–1-е число Фиббоначи */ N2=N–2, fib2(N2,F2), /* F2 это N–2-е число Фиббоначи */ F=F1+F2, /* N-е число Фиббоначи равно сумме N–1-го числа Фиббоначи и N–2-го числа Фиббоначи */ asserta(fib_db(N,F)). /* добавляем вычисленное N-е число Фиббоначи в нашу внутреннюю базу данных*/
Заметьте, что при каждом вызове подцели fib2(N2,F2) используются значения, уже вычисленные при предыдущем вызове подцели fib2(N1,F1).
Попробуйте запустить два варианта предиката вычисляющего числа Фиббоначи для достаточно больших номеров (от 30 и выше) и почувствуйте разницу во времени работы. Минуты — работы первого варианта и доли секунды — работы его табулированной модификации.
Справедливости ради стоит заметить, что существует другой вариант ускорения работы предиката, вычисляющего числа Фиббоначи, без использования баз данных.
Будем искать сразу два числа Фиббоначи.То, которое нам нужно найти, и следующее за ним. Соответственно, предикат будет иметь третий дополнительный аргумент, в который и будет помещено следующее число. Базис рекурсии из двух предложений сожмется в одно, утверждающее, что первые два числа Фиббоначи равны единице.
Вот как будет выглядеть этот предикат:
fib_fast(0,1,1):–!. fib_fast(N,FN,FN1):– N1=N–1,fib_fast(N1,FN_1,FN), FN1=FN+FN_1.
Если следующее число Фиббоначи искать не нужно, можно сделать последним аргументом анонимную переменную или добавить описанный ниже двухаргументный предикат:
fib_fast(N,FN):– fib_fast(N,FN,_).
Пролог и искусственный интеллект
В этой лекции речь пойдет о возможных применениях Пролога в области искусственного интеллекта. Конечно, ознакомиться с данной темой достаточно полно в рамках одной лекции мы не успеем. Однако хочется надеяться, что сможем пробежаться по верхушкам и рассмотреть пару простых примеров.
В 1950 году Алан Тьюринг в статье "Вычислительная техника и интеллект" (книга "Может ли машина мыслить?") предложил эксперимент, позднее названный "тест Тьюринга", для проверки способности компьютера к "человеческому" мышлению. В упрощенном виде смысл этого теста заключается в том, что можно считать искусственный интеллект созданным, если человек, общающийся с двумя собеседниками, один из которых человек, а второй — компьютер, не сможет понять, кто есть кто. То есть в соответствии с тестом Тьюринга, компьютеру требуется научиться имитировать человека в диалоге, чтобы его можно было считать "интеллектуальным".
Такой подход к распознаванию искусственного интеллекта многие критиковали, однако никаких достойных альтернатив тесту Тьюринга предложено не было.
Первый пример, который мы рассмотрим, будет относиться к области обработки естественного языка.
Пример. Создадим программу, имитирующую разговор психотерапевта с пациентом. Прообразом нашей программы является "Элиза", созданная Джозефом Вейценбаумом в лаборатории искусственного интеллекта массачусетского технологического института в 1966 году (названная в честь Элизы из "Пигмалиона"). Она была написана на языке Лисп и состояла всего из нескольких десятков строк программного кода. Эта программа моделировала методику известного психотерапевта Карла Роджерса. В этом подходе психотерапевт играет роль "вербального зеркала" пациента. Он переспрашивает пациента, повторяет его слова, позволяя ему самому найти выход из сложившейся ситуации, прийти в состояние душевного равновесия.
На самом деле эта программа пытается сопоставить вводимые пользователем ответы с имеющимися у нее шаблонами и, если ей это удается, шаблонно же отвечает.
Вейценбаум создал эту программу в качестве шутки. Многие пациенты, пообщавшись с детищем Вейценбаума, утверждали, что "Элиза" им помогла, и отказывались верить, что их собеседником был не психотерапевт, а компьютерная программа. Всю оставшуюся жизнь Вейценбаум пытался охладить восторженных поклонников его программы и убедить общественность, что машина не может мыслить.
Наша программа будет действовать по следующему алгоритму.
Попросит человека описать имеющуюся у него проблему.Прочитает строку с клавиатуры.Попытается подобрать шаблон, которому соответствует введенная человеком строка.Если удалось — выдаст соответствующий этому шаблону ответ пользователю.Если подобрать шаблон не удалось — попросит продолжать рассказ.Возвращаемся к пункту 2 и продолжаем процесс.
Для решения этой задачи нам понадобится предикат, преобразующий строку, вводимую пользователем в список слов. Можно было бы воспользоваться модифицированной версией предиката str_a_list, рассмотренного нами в одиннадцатой лекции. Однако он использует предикат fronttoken, который в Турбо Прологе, в отличие от Визуального Пролога, из русских предложений выделяет не слова, а отдельные символы. Поэтому мы напишем новый вспомогательный предикат, который будет считывать символ за символом до тех пор, пока не встретит символ-разделитель (пробел, запятая, точка и другой знак препинания). Так как проверять совпадение очередного символа с символом-разделителем нам придется не раз, заведем список символов-разделителей. Поместим его в раздел описания констант и назовем separators (символы-разделители). После этого все символы до символа-разделителя будут помещены в первое слово строки, а все символы, идущие после символа-разделителя, обработаны подобным образом.
Кроме того, при переписывании строки в список ее слов мы переведем все русские символы, записанные в верхнем регистре (большие буквы), в нижний регистр (маленькие буквы). Это облегчит в дальнейшем процесс распознавания слов. Нам не придется предусматривать всевозможные варианты написания пользователем слова (например, "Да", "да", "ДА"), мы будем уверены, что все символы слова — строчные ("да").
При реализации этого предиката нам понадобится три вспомогательных предиката.
Первый предикат будет преобразовывать прописные русские буквы в строчные, а все остальные символы оставлять неизменными. У него будет два аргумента: первый (входной) — исходный символ, второй (выходной) — символ, полученный преобразованием первого аргумента.
При написании данного предиката стоит учесть, что строчные русские буквы расположены в таблице символов двумя группами. Первая группа (буквы от 'а' до 'п') имеют, соответственно, коды от 160 до 175. Вторая группа (буквы от 'р' до 'я') — коды от 224 до 239.
С учетом вышеизложенного предикат можно записать, например, так:
lower_rus(C,C1):– 'А'<=C,C<='П',!, /* символ C лежит между буквами 'А' и 'П' */ char_int(C,I), /* I — код символа C */ I1=I+(160–128), /* 160 — код буквы 'а', 128 — код буквы 'А'*/ char_int(C1,I1). /* C1 — символ с кодом I1 */ lower_rus(C,C1):– 'Р'<=C,C<='Я',!, /* символ C лежит между буквами 'Р' и 'Я' */ char_int(C,I), /* I — код символа C */ I1=I+(224–144), /* 224 — код буквы 'р', 144 — код буквы 'Р'*/ char_int(C1,I1). /* C1 — символ с кодом I1 */ lower_rus(C,C). /* символ C отличен от прописной русской буквы и, значит, мы не должны его изменять */
Второй предикат first_word будет иметь три аргумента. Первый (входной) — исходная строка, второй и третий (выходные) — соответственно, первое слово строки (не содержащее прописных русских букв) и остаток строки, полученный удалением из него первого слова.
Выглядеть его реализация будет следующим образом:
first_word("","",""):–!. /* из пустой строки можно выделить только пустые подстроки */ first_word(S,W,R):– /* W — первое слово строки S, R — остальные символы исходной строки S */ frontchar(S,C,R1), /* C — первый символ строки S, R1 — остальные символы */ not(member(C,separators)),!, /* символ C не является символом-разделителем */ first_word(R1,S1,R), /* S1 — первое слово строки R1, R — оставшиеся символы строки R1 */ lower_rus(C,C1), /* если C — прописная русская буква , то C1 — соответствующая ей строчная буква, иначе символ C1 не отличается от символа C */ frontchar(W,C1,S1). /* W — результат "приклеивания" символа C1 в начало строки S1 */ first_word(S,"",R):– /* в случае, если первый символ оказался символом-разделителем, */ frontchar(S,_,R). /* его нужно выбросить, */
Третий предикат del_sep будет предназначен для удаления из начала строки символов-разделителей. У него будет два аргумента. Первый (входной) — исходная строка, второй (выходной) — строка, полученная из первого аргумента удалением символов-разделителей, расположенных в начале строки, если таковые имеются.
del_sep("",""):–!. del_sep(S,S1):– frontchar(S,C,R), /* C — первый символ строки, R — остальные символы */ member(C,separators),!, /* если C является символом-разделителем, */ del_sep(R,S1). /* то переходим к рассмотрению остатка строки */ del_sep(S,S) . /* если первый символ строки не является символом-разделителем, то удалять нечего */
И, наконец, предикат, преобразующий строку в список слов.
str_w_list("",[]):–!. /* пустой строке соответствует пустой список слов, входящих в нее */ str_w_list(S,[H T]):– first_word(S,H,R),!, /* H — первое слово строки S, R — оставшиеся символы строки S */ str_w_list(R,T). /* T — список, состоящий из слов, входящих в строку R */
Основную работу в программе будет осуществлять предикат recognize, задачей которого будет распознавать шаблон, которому можно сопоставить введенную строку. Этот предикат на входе будет получать список слов строки, а на выходе будет выдавать номер шаблона. По этому номеру другой предикат должен будет выдать на экран соответствующую реакцию (вопрос, реплику, уточнение).
Наша учебная программа будет распознавать одиннадцать шаблонов:
Человек хочет закончить работу с программой. Об этой ситуации свидетельствует наличие в списке таких слов, как "пока", "свидания" (часть словосочетания "до свидания"). В ответ программа также прощается и выражает надежду, что она смогла чем-нибудь помочь.Человек испытывает какое-то чувство (наличие в списке слова "испытываю"). Программа реагирует вопросом о том, как давно человек испытывает это чувство.Если во вводимой строке встретились слова "любовь" или "чувства", то программа поинтересуется, не боится ли человек эмоций.При обнаружении слова "секс" во входном списке слов будет выдано сообщение о важности сообщения.В случае наличия слов "бешенство", "гнев" или "ярость", программа уточнит, что человек испытывает в данный момент времени.В ответ на краткий ответ ("да" или "нет") будет выдана просьба рассказать подробнее.Если в списке слов найдутся слова "комплекс" или "фиксация", программа отреагирует замечанием о том, что человек слишком много "играет".Появление слова "всегда" в строке, введенной человеком, приводит к ответной реакции — вопросу о том, может ли человек привести какой-нибудь пример.В случае, если человек упомянул кого-то из своих родных ("папа", "мама", "жена", "муж", "брат", "сестра", "сын", "дочь" и т.д.), программа попросит рассказать поподробнее о его семье.
При этом упомянутый родственник будет помещен в базу данных, чтобы потом продолжить этот разговор.Если в процессе разговора была сделана запись во внутреннюю базу данных и в данный момент спросить больше не о чем, программа "вспомнит" об упомянутом родственнике и выдаст фразу: "ранее Вы упоминали ..."И, наконец, если введенная строка не подходит ни под один шаблон, программа просит продолжить рассказ.
А теперь запишем всю программу целиком.
CONSTANTS /* раздел описания констант */ separators=[' ', ',', '.', ';'] /* символы-разделители (пробел, запятая, точка, точка с запятой и т.д.) */ DOMAINS /* раздел описания доменов */ i=integer s=string ls=s* /* список слов */ lc=char* /* список символов */ DATABASE /* раздел описания предикатов базы данных */ Important(s) PREDICATES /* раздел описания предикатов */ member(s,ls) /* проверяет принадлежность строки списку строк */ member(char,lc) /* проверяет принадлежность символа списку символов */ lower_rus(char,char) /* преобразует прописную русскую букву в строчную букву */ del_sep(s,s) /* удаляет из начала строки символы-разделители */ first_word(s,s,s) /* делит строку на первое слово и остаток строки */ str_w_list(s,ls) /* преобразует строку в список слов */ read_words(ls) /* читает строку с клавиатуры, возвращает список слов, входящих в строку*/ recognize(ls,i) /* сопоставляет списку слов число, кодирующее шаблон */ answ(ls) /* выводит ответ человеку */ eliz /* основной предикат */ repeat CLAUSES /* раздел описания предложений */ eliz:– repeat, read_words(L), /* читаем строку с клавиатуры, преобразуем ее в список слов L */ recognize(L,I), /* сопоставляем списку слов L номер шаблона I */ answ(I),nl, /* выводим ответ, соответствующий номеру шаблона I */ I=0 /* номер шаблона I, равный нулю, означает, что человек попрощался */. read_words(L):– readln(S), /* читаем строку */ str_w_list(S,L). /* преобразуем строку в список слов */ recognize(L,0):– member("пока",L),!; member("свидания",L),!.
recognize(L,1):– member("испытываю",L),!. recognize(L,2):– member("любовь",L),!; member("чувства",L),!. recognize(L,3):– member("секс",L),!. recognize(L,4):– member("бешенство",L),!; member("гнев",L),!; member("ярость",L),!. recognize(L,5):– L=["да"],!; L=["нет"],!. recognize(L,6):– member("комплекс",L),!; member("фиксация",L),!. recognize(L,7):– member("всегда",L),!. recognize(L,8):– member("мать",L),assert(important("своей матери")),!; member("мама",L),assert(important("своей маме")),!; member("отец",L),assert(important("своем отце")),!; member("папа",L),assert(important("своем папе")),!; member("муж",L),assert(important("своем муже")),!; member("жена",L),assert(important("своей жене")),!; member("брат",L),assert(important("своем брате")),!; member("сестра",L),assert(important("своей сестре")),!; member("дочь",L),assert(important("своей дочери")),!; member("сын",L),assert(important("своем сыне")),!. recognize(_,9):– important(_),!. recognize(_,10). answ(0):– write("До свидания"),nl, write(" Надеюсь наше общение помогло Вам"). answ(1):– write("Как давно Вы это испытываете?"). answ(2):– write("Вас пугают эмоции?"). answ(3):– write("Это представляется важным"). answ(4):– write("А что Вы испытываете сейчас?"). answ(5):– write("Расскажите об этом подробнее"). answ(6):– write("Слишком много игр"). answ(7):– write("Вы можете привести какой–нибудь пример?"). answ(8):– write("Расскажите мне подробнее о своей семье"). answ(9):– important(X),!, write("Ранее Вы упомянули о ",X), retract(X). answ(10):– write("Продолжайте, пожалуйста"). repeat. repeat:– repeat.
member(X,[X|_]):–!. member(X,[_|S]):–member(X,S). lower_rus(C,C1):– 'А'<=C,C<='П',!, /* символ C лежит между буквами 'А' и 'П' */ char_int(C,I), /* I — код символа C */ I1=I+(160–128), /* 160 — код буквы 'а', 128 — код буквы 'А'*/ char_int(C1,I1). /* C1 — символ с кодом I1 */ lower_rus(C,C1):– 'Р'<=C,C<='Я',!, /* символ C лежит между буквами 'Р' и 'Я' */ char_int(C,I), /* I — код символа C */ I1=I+(224–144), /* 224 — код буквы 'р', 144 — код буквы 'Р'*/ char_int(C1,I1). /* C1 — символ с кодом I1 */ lower_rus(C,C). /* символ C отличен от прописной русской буквы и, значит, мы не должны его изменять */ del_sep("",""):–!. del_sep(S,S1):– frontchar(S,C,R), /* C — первый символ строки, R — остальные символы */ member(C,separators),!, /* если C является символом-разделителем, */ del_sep(R,S1). /* то переходим к рассмотрению остатка строки */ del_sep(S,S) . /* если первый символ строки не является символом-разделителем, то удалять нечего */ str_w_list("",[]):–!. /* пустой строке соответствует пустой список слов, входящих в нее */ str_w_list(S,[H|T]):– first_word(S,H,R),!, /* H — первое слово строки S, R — оставшиеся символы строки S */ str_w_list(R,T). /* T — список, состоящий из слов, входящих в строку R */ first_word("","",""):–!. /* из пустой строки можно выделить только пустые подстроки */ first_word(S,W,R):– /* W — первое слово строки S, R — остальные символы исходной строки S */ frontchar(S,C,R1), /* C — первый символ строки S, R1 — остальные символы */ not(member(C,separators)),!, /* символ C не является символом-разделителем */ first_word(R1,S1,R), /* S1 — первое слово строки R1, R — оставшиеся символы строки R1 */ lower_rus(C,C1), /* если C — прописная русская буква , то C1 — соответствующая ей строчная буква, иначе символ C1 не отличается от символа C */ frontchar(W,C1,S1). /* W — результат "приклеивания" символа C1 в начало строки S1 */ first_word(S,"",R):– /* в случае, если первый символ оказался символом-разделителем, */ frontchar(S,_,R). /* его нужно выбросить, */ GOAL /* раздел описания цели */ write("Расскажите, в чем заключается Ваша проблема"),nl, eliz, readchar(_).
Листинг 14.1. Программа, имитирующая разговор психотерапевта с пациентом
Усовершенствовать работу этой программы можно двумя способами. С одной стороны, можно увеличить количество шаблонов, с другой стороны, можно организовать разные реакции на некоторые из шаблонов (например, используя случайные числа).
В 1977 г. Кеннет Колби, основываясь на принципах организации "Элизы", создал программу, которая подобным образом вводила в заблуждение уже не клиентов психиатров, а самих докторов. Большинство из них после общения с его программой решили, что имели дело с реальным параноиком.
В 1996 г. Грег Гарви создал программную модель католического исповедника, которая опиралась на те же идеи, что и "Элиза".
Другие варианты "Элизы" можно найти в следующих книгах:
Л. Стерлинг, Э. Шапиро. Искусство программирования на языке Пролог. — М.:Мир, 1990.Д. Марселлус. Программирование экспертных систем на Турбо-Прологе. — М.: Финансы и статистика, 1994.
Теперь рассмотрим еще один пример применения Пролога в области искусственного интеллекта. Создадим небольшую экспертную систему. Экспертными системами обычно называют программы, которые могут заменить эксперта в какой-то предметной области. Мы построим классификационную экспертную систему, которая будет пытаться угадать загаданное человеком животное. Если загаданное человеком животное окажется неизвестно нашей программе, у нее будет возможность пополнить свою базу знаний новой информацией.
В связи с тем, что мы планируем пополнять нашу базу знаний, мы будем по окончании работы сохранять ее в файл, а при начале работы считывать информацию из файла в оперативную память. Для этого мы воспользуемся изученными в предыдущей лекции внутренними (динамическими) базами данных.
Так как в Турбо Прологе в базе данных можно размещать только факты, представим правила, определяющие животных в виде фактов.
Определим два предиката внутренней базы данных, которые позволят нам хранить информацию о животных.
Один из них предназначен для хранения характеристик животных и будет иметь два аргумента: первый — номер свойства, второй — его словесное описание.
Небольшой базовый набор свойств может выглядеть, например, так:
cond(1,"кормит детенышей молоком"). cond(2,"имеет перья"). cond(3,"плавает"). cond(4,"ест мясо"). cond(5,"имеет копыта"). cond(6,"летает"). cond(7,"откладывает яйца"). cond(8,"имеет шерсть"). cond(9,"имеет полосы"). cond(10,"имеет пятна"). cond(11,"имеет черно-белую окраску"). cond(12,"имеет длинную шею"). cond(13,"имеет длинные ноги"). cond(14,"имеет щупальца").
Второй предикат будет хранить описание животных. Первый его аргумент — название животного, второй — список, элементами которого являются номера свойств, присущих данному животному.
Выглядеть эта база знаний может примерно следующим образом:
rule("гепард",[1,4,8,10]). rule("тигр",[1,4,8,9]). rule("жираф",[1,5,8,10,12,13]). rule("зебра",[1,5,8,9,11]). rule("страус",[2,14]). rule("пингвин",[2,3,11]). rule("орел",[2,6]). rule("кит",[1,3,11]). rule("осьминог",[3,14]).
По сути дела, в виде фактов записаны правила. Например, правило: "если животное кормит детенышей молоком, имеет копыта, пятна, длинную шею и ноги, то это жираф", записано в виде rule("жираф", [1,5,11,13,14]).
Во второй базе мы будем хранить ответы человека в следующем виде:
cond_is(N,'1') /* если загаданное животное имеет свойство с номером N */ cond_is(N,'2') /* если загаданное животное не имеет свойства с номером N */
Первую базу назовем knowledge, а вторую — dialog.
Процесс отгадывания задуманного животного будет проходить следующим образом. Будем последовательно перебирать животных, имеющихся в нашей базе знаний. Если загаданное животное обладает всеми характеристиками известного программе животного, делается вывод о том, кто был загадан. Если не удается сопоставить загаданному животному ни одно из животных, имеющихся в базе знаний, производится пополнение базы.
Вот как будет выглядеть реализация написанного выше.
animals:– rule(X,L), check(L), nl,write("Я думаю это ",X), nl,write("Я прав? (1 — да, 2 — нет)"), read_true_char(C),C='1',!. animals:– nl,write("Я не знаю, что это за животное"),nl, nl,write("Давайте добавим его в мою базу знаний."),nl, update.
Предикат check осуществляет проверку свойств, номера которых входят в список, указанный в качестве его единственного аргумента.
check([H|T]):– test_cond(H), check(T). check([]).
Предикат test_cond проверяет наличие у загаданного животного свойства с номером, указанным в качестве его единственного аргумента. Если человеком ранее уже был дан ответ (положительный или отрицательный) по поводу наличия данного свойства, информация об этом имеется в базе данных. Если же в базе нет никакой информации о наличии данного свойства у загаданного животного, нужно задать человеку соответствующий вопрос и добавить его ответ в базу.
Вот как это можно записать.
test_cond(H):– cond_is(H,'1'),!. /* в базе имеется информация о наличии данного свойства */ test_cond(H):– cond_is(H,'2'),!, fail. /* в базе имеется информация об отсутствии данного свойства */ test_cond(H):– /* в базе нет никакой информации о данном свойстве, получаем ее у человека */ cond(H,S), nl,write("Оно ",S,"? (1 — да, 2 — нет)"), read_true_char(A), assert(cond_is(H,A)), test_cond(H).
Предикат read_true_char осуществляет проверку нажатой пользователем клавиши, и если она отлична от '1' или '2', выводит соответствующее сообщение и повторно считывает символ с клавиатуры.
read_true_char(C):– readchar(C1), test(C1,C). test(C,C):– '1'<=C,C<='2',!. test(_,C):– write("Нажмите 1 или 2!"),nl, readchar(C1), test(C1,C).
Предикат update осуществляет добавление новой информации в базу знаний. Он читает название нового животного, с помощью предиката add_cond формирует список номеров свойств загаданного животного, добавляет соответствующий факт в базу знаний, сохраняет базу в файл.
Вот как он будет выглядеть:
update:– nl,write("Введите название животного:"), readln(S), add_cond(L), /* указываем свойства животного */ assert(rule(S,L),knowledge), /* добавляем информацию в базу знаний*/ save("animals.ddb",knowledge) /* сохраняем базу знаний в файл */.
Предикат add_cond с помощью предиката print_cond выводит уже имеющуюся в базе информацию о свойствах загаданного животного и спрашивает, известно ли еще что-нибудь о нем. В случае необходимости добавляет его новые характеристики, используя предикат read_cond.
add_cond(L):– cond_is(_,'1'),!, /* имеется информация о свойствах животного */ nl,write("О нем известно, что оно: "), print_cond(1,[],L1), /* вывод имеющейся информации о животном */ nl,write("Известно ли о нем еще что-нибудь? (1 — да, 2 — нет)"), read_true_char(C), read_cond(C,L1,L). add_cond(L):– read_cond('1',[],L).
Предикат read_cond, используя предикат ex_cond, добавляет в список номера свойств, уже имеющихся в базе; используя предикат new_cond, добавляет в список номера новых свойств, а также описания самих свойств — в базу знаний.
read_cond('1',L,L2):– ex_cond(1,L,L1,N), new_cond(N,L1,L2),!. read_cond(_,L,L):–!.
Основные предикаты мы рассмотрели, а вот как будет выглядеть вся программа целиком:
DOMAINS i=integer s=string c=char li=i* /* список целых чисел */ DATABASE — knowledge cond(i,s) /* свойства животных */ rule(s,li) /* описания животных */ DATABASE — dialog cond_is(i,c) /* номер условия; '1' — имеет место, '2' — не имеет места у загаданного животного */ PREDICATES start animals /* отгадывает животное */ check(li) /* добавляет в базу информацию о новом животном */ test_cond(i) /* проверяет, обладает ли загаданное животное свойством с данным номером */ update /* добавляет в базу информацию о новом животном */ add_cond(li) /* возвращает список, состоящий из номеров свойств, имеющихся у нового животного */ print_cond(i,li,li) /* добавляет в список номера свойств, относительно которых уже были даны утвердительные ответы */ read_cond(c,li,li) /* добавляет в список номера свойств, о которых еще не спрашивалось */ ex_cond(i,li,li,i) /* добавляет в список номера имеющихся в базе свойств, которыми обладает новое животное */ wr_cond(c,i,li,li) new_cond(i,li,li) /* добавляет в список номера новых свойств, которыми обладает новое животное, а также добавляет описания новых свойств в базу знаний */ read_true_char(c) /* с помощью предиката test читает символ с клавиатуры, пока он не окажется равен '1' или '2'*/ test(c,c) /* добивается, чтобы пользователь нажал один из символов, '1' или '2' */ CLAUSES start:– consult("animals.ddb",knowledge), /* загружаем в базу информацию из базы знаний */ write("Загадайте животное, а я попытаюсь его отгадать"),nl, animals, /* попытка отгадать загаданное животное */ retractall(_,dialog), /* очищаем текущую информацию */ retractall(_,knowledge), /* очищаем информацию об известных животных и свойствах */ nl,nl,write("Хотите еще раз сыграть? (1 — Да, 2 — Нет)"), read_true_char(C), C='1',!,start.
start:– nl,nl,write("Всего доброго! До новых встреч"), readchar(_). animals:– rule(X,L), check(L), nl,write("Я думаю, это ",X), nl,write("Я прав? (1 — да, 2 — нет)"), read_true_char(C),C='1',!. animals:– nl,write(" Я не знаю, что это за животное"),nl, nl,write("Давайте добавим его в мою базу знаний."),nl, update. update:– nl,write("Введите название животного:"), readln(S), add_cond(L), /* указываем свойства животного */ assert(rule(S,L),knowledge), /* добавляем информацию в базу знаний*/ save("animals.ddb",knowledge) /* сохраняем базу знаний в файл */. add_cond(L):– cond_is(_,'1'),!, /* имеется информация о свойствах животного */ nl,write("О нем известно, что оно: "), print_cond(1,[],L1), /* вывод имеющейся о животном информации */ nl,write("Известно ли о нем еще что-нибудь? (1 — да, 2 — нет)"), read_true_char(C), read_cond(C,L1,L). add_cond(L):– read_cond('1',[],L). print_cond(H,L,L):– not(cond(H,_)),!. print_cond(H,L,L1):– cond_is(H,'1'),!, cond(H,T), H1=H+1, nl,write(T), print_cond(H1,[H L],L1). print_cond(H,L,L1):– H1=H+1, print_cond(H1,L,L1). read_cond('1',L,L2):– ex_cond(1,L,L1,N), new_cond(N,L1,L2),!. read_cond(_,L,L):–!. ex_cond(N,L,L,N):– not(cond(N,_)),!. ex_cond(N,L,L1,N2):– cond_is(N,_),!, N1=N+1, ex_cond(N1,L,L1,N2). ex_cond(N,L,L1,N2):– cond(N,S), nl,write("Оно ",S,"? (1 — да, 2 — нет)"), read_true_char(A), wr_cond(A,N,L,L2), N1=N+1, ex_cond(N1,L2,L1,N2). wr_cond('1',N,L,[N L]):–!. wr_cond('2',_,L,L):–!. new_cond(N,L,L1):– nl,write("Есть еще свойства? (1 — да, 2– нет)"), read_true_char(A), A='1',!, nl,write("Укажите новое свойство, которым обладает животное"), nl,write("в виде 'оно <описание нового свойства>'"), readln(S), assertz(cond(N,S)), /* добавление нового свойства в базу знаний */ N1=N+1, new_cond(N1,[N L],L1). new_cond(_,L,L). check([HT]):– test_cond(H), check(T). check([]). test_cond(H):- cond_is(H,'1'),!. /* в базе имеется информация о наличии свойства */ test_cond(H):– cond_is(H,'2'),!, fail. /* в базе имеется информация об отсутствии свойства */ test_cond(H):– /* в базе нет никакой информации о данном свойстве, получаем ее у человека */ cond(H,S), nl,write("Оно ",S,"? (1 — да, 2 — нет)"), read_true_char(A), assert(cond_is(H,A)), test_cond(H).
read_true_char(C):– readchar(C1), test(C1,C). test(C,C):– '1'<=C,C<='2',!. test(_,C):– write("Нажмите 1 или 2!"),nl, readchar(C1), test(C1,C). GOAL start
Листинг 14.2. Самообучающийся определитель животных
В идеале экспертная система должна уметь объяснять пользователю свое решение, а также почему она задает тот или иной вопрос. Попробуйте добавить в нашу экспертную систему механизм объяснения.
Две версии этой программы, основанной на правилах (реализующие, соответственно, прямую и обратную цепочки рассуждений), можно найти в книге Д. Марселлус, Программирование экспертных систем на Турбо-Прологе. — М.: Финансы и статистика, 1994. Однако эти программы умеют распознавать только тех животных, которые заложены в них изначально. Возможности динамического пополнения базы знаний они не имеют. Для добавления описания нового животного требуется модификация программного кода.
Кроме того, я рекомендую читателям изучить программу GEOBASE, которая входит в состав и Турбо Пролога, и Visual Prolog. Эта программа содержит информацию по географии США и позволяет создавать запросы к базе данных на естественном (английском) языке.
Самостоятельные задания
Создайте "определитель растений" (собак, грибов). Создайте программу, позволяющую диагностировать заболевание по симптомам. Создайте программу, позволяющую диагностировать неисправность какого-либо технически сложного устройства (велосипед, автомобиль, компьютер, телевизор и т.д.).Создайте программу, помогающую школьнику определиться с выбором будущей профессии.Создайте программу, отыскивающую такие расстановки ферзей на пустой шахматной доске, в которой ни один из ферзей не находится под боем другого.Создайте программу, решающую задачу раскраски карты. Задача заключается в следующем. Имеется набор пар, в котором первая компонента представляет собой название страны, вторая - список стран, граничащих со страной, чье название находится в первой компоненте. Требуется сопоставить каждой стране цвет так, чтобы ни одна пара соседних стран не была окрашена в одинаковые цвета. При этом разрешается использовать не более четырех цветов.Создайте программу, осуществляющую поиск пути в лабиринте. Задача заключается в следующем. Имеется описание лабиринта в виде набора координат стен, а также координаты текущей позиции в лабиринте и координаты выхода. Требуется найти путь от текущей позиции до выхода. В качестве дополнительного задания можно подсчитать длину пройденного пути. Создайте программу, осуществляющую Символьное дифференцирование введенной формулы.
