Предварительные понятия и примеры
11. 1. Предварительные понятия и примеры
Рассмотрим пример, представленный на Рисунок 11.1. Задача состоит в выработке плана переупорядочивания кубиков, поставленных друг на друга, как показано на рисунке. На каждом шагу разрешается переставлять только один кубик. Кубик можно взять только тогда, когда его верхняя поверхность свободна. Кубик можно поставить либо на стол, либо на другой кубик. Для того, чтобы построить требуемый план, мы должны отыскать последовательность ходов, реализующую заданную трансформацию.
Эту задачу можно представлять себе как задачу выбора среди множества возможных альтернатив. В исходной ситуации альтернатива всего одна: поставить кубик С на стол. После того как кубик С поставлен на стол, мы имеем три альтернативы: поставить А на стол или поставить А на С, или поставить С на А.
Стратегия поиска в глубину
11. 2. Стратегия поиска в глубину
Существует много различных подходов к проблеме поиска решающего пути для задач, сформулированных в терминах пространства состояний. Основные две стратегии поиска - это поиск в глубину и поиск в ширину. В настоящем разделе мы реализуем первую из них.
Мы начнем разработку алгоритма и его вариантов со следующей простой идеи:
line();Для того, чтобы найти решающий путь Реш из заданной вершины В в некоторую целевую вершину, необходимо: если В - это целевая вершина, то положить Реш = [В], или если для исходной вершины В существует вершина-преемник В1, такая, что можно провести путь Реш1 из В1 в целевую вершину, то положить Реш = [В | Peш1]. line();
Списковое представление множества кандидатов
11. 3. 1. Списковое представление множества кандидатов
В нашей первой реализации этой идеи мы будем использовать следующее представление для множества
line(); решить( Старт, Решение) :-
вширину( [ [Старт] ], Решение).
вширину( [ [Верш | Путь] | _ ], [Верш | Путь] ) :-
цель( Верш).
вширину( [ [В | Путь] | Пути], Решение ) :-
bagof( [B1, В | Путь ],
( после( В, В1), not принадлежит( В1, [В | Путь])),
НовПути),
% НовПути - ациклические продолжения пути [В | Путь]
конк( Пути, НовПути, Пути1), !,
вширину( Путь1, Решение);
вширину( Пути, Решение).
% Случай, когда у В нет преемника
Древовидное представление множества кандидатов
11. 3. 2. Древовидное представление множества кандидатов
Рассмотрим теперь еще одно изменение нашей программы поиска в ширину. До сих пор мы представляли множества путей-кандидатов как списки путей. Это расточительный способ, поскольку начальные участки путей являются общими для нескольких из них. Таким образом, эти общие части путей приходится хранить во многих экземплярах. Избежать избыточности помогло бы более компактное представление множества кандидатов. Таким более компактным представлением является дерево, в котором общие участки путей хранятся в его верхней части без дублирования. Будем использовать в программе следующее представление дерева. Имеется два случая:
Случай 1: Дерево состоит только из одной вершины В; В этом случае оно имеет вид терма л( В); Функтор л указывает на то, что В - это лист дерева.
Случай 2: Дерево состоит из корневой вершины В и множества поддеревьев Д1, Д2, ... . Такое дерево представляется термом
д( В, Пд)
где Пд - список поддеревьев:
Пд = [ Д1, Д2, ...]
В качестве примера рассмотрим ситуацию, которая возникает после того, как порождены три уровня дерева Рисунок 11.9. Множество путей-кандидатов в случае спискового представления имеет вид:
[ [d, b, a], [e, b, а], [f, c, a], [g, c, a] ]
В виде дерева это множество выглядит так:
д( а, [д( b, [л( d), л( е)] ), д( с, [л( f), л( g)] )] )
На первый взгляд древовидное представление кажется еще более расточительным, чем списковое, однако это всего лишь поверхностное впечатление, связанное с компактностью прологовской нотации для списков.
В случае спискового представления множества кандидатов эффект распространения процесса в ширину достигался за счет перемещения продолженных путей в конец списка. В нашем случае мы уже не можем использовать этот прием, поэтому программа несколько усложняется. Ключевую роль в нашей программе будет играть отношение
расширить( Путь, Дер, Дер1, ЕстьРеш, Решение)
На Рисунок 11.12 показано, как связаны между собой аргументы отношения расширить. При каждом обращении к расширить переменные Путь и Дер будут уже конкретизированы. Дер - поддерево всего дерева поиска, одновременно оно служит для представления множества путей-кандидатов внутри этого поддерева. Путь - это путь, ведущий из стартовой вершины в корень поддерева Дер. Самая общая идея алгоритма -
Поиск в ширину
11. 3. Поиск в ширину
В противоположность поиску в глубину стратегия поиска в ширину предусматривает переход в первую очередь к вершинам, ближайший к стартовой вершине. В результате процесс поиска имеет тенденцию развиваться более в ширину, чем в глубину, что иллюстрирует Рисунок 11.9.
Поиск в ширину программируется не так легко, как поиск в глубину. Причина состоят в том, что
Замечания относительно поиска в графах оптимальности к сложности
11. 4. Замечания относительно поиска в графах, оптимальности к сложности
Сейчас уместно сделать ряд замечаний относительно программ поиска, разработанных к настоящему моменту: во-первых, о поиске в графах, во-вторых, об оптимальности полученных решений и, в-третьих, о сложности поиска.
Приведенные примеры могли создать ложное впечатление, что наши программы поиска в ширину способны работать только в пространствах состояний, являющихся деревьями, а не графами общего вида. На самом деле, тот факт, что в одной из версий множество путей-кандидатов представлялось деревом, совсем не означает, что и само пространство состояний должно было быть деревом. Когда поиск проводится в графе, граф фактически разворачивается в дерево, причем некоторые пути, возможно, дублируются в разных частях этого дерева (см. Рисунок 11.14).
Наши программы поиска в ширину порождают решающие пути один за другим в порядке увеличения их
Литература
Литература
Поиск в глубину и поиск в ширину - базовые стратегии поиска, они описаны в любом учебнике по искусственному интеллекту, см., например, Nilsson (1971, 1980) или Winston (1984). Р. Ковальский в своей книге Kowalski (1980) показывает, как можно использовать аппарат математической логики для реализации этих принципов.
Kowalski R. (1980). Logic for Problem Solving. North-Holland.
Nilsson N. J. (1971). Problem Solving Methods in Artificial Intelligence. McGraw-Hill.
Nilsson N. J. (1980). Principles of Artificial Intelligence. Tioga; also Springer- Verlag, 1981.
Winston P. H. (1984). Artificial Intelligence (second edition). Addison-Wesley. [Имеется перевод первого издания: Уинстон П. Искусственный интеллект. - М.: Мир, 1980.]
Пространство состояний есть формализм для
Резюме
Пространство состояний есть формализм для представления задач. Пространство состояний - это направленный граф, вершины которого соответствуют проблемным ситуациям, а дуги - возможным ходам. Конкретная задача определяется стартовой вершиной и целевым условием. Решению задачи соответствует путь в графе. Таким образом, решение задачи сводится к поиску пути в графе. Оптимизационные задачи моделируются приписыванием каждой дуге пространства состояний некоторой стоимости. Имеются две основных стратегии поиска в пространстве состояний - поиск в глубину и поиск в ширину. Поиск в глубину программируется наиболее легко, однако подвержен зацикливаниям. Существуют два простых метода предотвращения зацикливания: ограничить глубину поиска и не допускать дублирования вершин. Реализация поиска в ширину более сложна, поскольку требуется сохранять множество кандидатов. Это множество может быть с легкостью представлено списком списков, но более экономное представление - в виде дерева. Поиск в ширину всегда первым обнаруживает самое короткое решение, что не верно в отношении стратегии поиска в глубину. В случае обширных пространств состояний существует опасность комбинаторного взрыва. Обе стратегии плохо приспособлены для борьбы с этой трудностью. В таких случаях необходимо руководствоваться эвристиками. В этой главе были введены следующие понятия:
пространство состояний
стартовая вершина, целевое условие,
решающий путь
стратегия поиска
поиск в глубину, поиск в ширину
эвристический поиск.
Задача перестановки кубиков
Рисунок 11. 1. Задача перестановки кубиков.

Ясно, что альтернативу "поставить С на стол" не имело смысла рассматривать всерьез, так как этот ход никак не влияет на ситуацию.
Как показывает рассмотренный пример, с задачами такого рода связано два типа понятий:
(1) Проблемные ситуации.
(2) Разрешенные ходы или действия, преобразующие одни проблемные ситуации в другие.
Проблемные ситуации вместе с возможными ходами образуют направленный граф, называемый пространством состояний. Пространство состояний для только что рассмотренного примера дано на Рисунок 11.2. Вершины графа соответствуют проблемным ситуациям, дуги - разрешенным переходам из одних состояний в другие. Задача отыскания плана решения задачи эквивалентна задаче построения пути между заданной начальной ситуацией ("стартовой" вершиной) и некоторой указанной заранее конечной ситуацией, называемой также целевой вершиной.
На Рисунок 11.3 показан еще один пример задачи: головоломка "игра в восемь" в ее представление в виде задачи поиска пути. В головоломке используется восемь перемещаемых фишек, пронумерованных цифрами от 1 до 8. Фишки располагаются в девяти ячейках, образующих матрицу 3 на 3. Одна из ячеек
Игра в восемь" и ее представление в форме графа
Рисунок 11. 3. "Игра в восемь" и ее представление в форме графа.

нять козу от волка и капусту от козы. С описанной парадигмой согласуются также многие задачи, имеющие практическое значение. Среди них - задача о коммивояжере, которая может служить моделью для многих практических оптимизационных задач. В задаче дается карта с n городами в указываются расстояния, которые надо преодолеть по дорогам при переезде из города в город. Необходимо найти маршрут, начинающийся в некотором городе, проходящий через все города и заканчивающиеся в том же городе. Ни один город, за исключением начального, не разрешается посещать дважды.
Давайте подытожим те понятия, которые мы ввели, рассматривая примеры. Пространство состояний некоторой задачи определяет "правила игры": вершины пространства состояния соответствуют ситуациям, а дуги - разрешенным ходам или действиям, или шагам решения задачи. Конкретная задача определяется пространством состояний стартовой вершиной целевым условием (т.е. условием, к достижению которого следует стремиться); "целевые вершины" - это вершины, удовлетворяющие этим условиям.
Каждому разрешенному ходу или действию можно приписать его стоимость. Например, в задаче манипуляции кубиками стоимости, приписанные тем или иным перемещениям кубиков, будут указывать иам на то, что некоторые кубики перемещать труднее, чем другие. В задаче о коммивояжере ходы соответствуют переездам из города в город. Ясно, что в данном случае стоимость хода - это расстояние между соответствующими городами.
В тех случаях, когда каждый ход имеет стоимость, мы заинтересованы в отыскании решения минимальной стоимости. Стоимость решения - это сумма стоимостей дуг, из которых состоит "решающий путь" - путь из стартовой вершины в целевую. Даже если стоимости не заданы, все равно может возникнуть оптимизационная задача: нас может интересовать кратчайшее решение.
Прежде тем будут рассмотрены некоторые программы, реализующие классический алгоритм поиска в пространстве состоянии, давайте сначала обсудим. как пространство состояний может быть представлено в прологовской программе.
Мы будем представлять пространство состояний при помощи отношения
после( X, Y)
которое истинно тогда, когда в пространстве состояний существует разрешенный ход из вершины Х в вершину Y. Будем говорить, что Y - это преемник вершины X. Если с ходами связаны их стоимости, мы добавим третий аргумент, стоимость хода:
после( X, Y, Ст)
Эти отношения можно задавать в программе явным образом при помощи набора соответствующих фактов. Однако такой принцип оказывается непрактичным и нереальным для тех типичных случаев, когда пространство состояний устроено достаточно сложно. Поэтому отношение следования после обычно определяется неявно, при помощи правил вычисления вершин-преемников некоторой заданной вершины. Другим вопросом, представляющим интерес с самой общей точки зрения, является вопрос о способе представления состояний, т.е. самих вершин. Это представление должно быть компактным, но в то же время оно должно обеспечивать эффективное выполнение необходимых операций, в частности операции вычисления вершин-преемников, а возможно и стоимостей соответствующих ходов.
Рассмотрим в качестве примера задачу манипулирования кубиками, проиллюстрированную на Рисунок 11.1. Мы будем рассматривать более общий случай, когда имеется произвольное число кубиков, из которых составлены столбики, - один или несколько. Число столбиков мы ограничим некоторым максимальным числом, чтобы задача была интереснее. Такое ограничение, кроме того, является вполне реальным, поскольку рабочее пространство, которым располагает робот, манипулирующий - кубиками, ограничено.
Проблемную ситуацию можно представить как список столбиков. Каждый столбик в свою очередь представляется списком кубиков, из которых он составлен. Кубики упорядочены в списке таким образом, что самый верхний кубик находится в голове списка. "Пустые" столбики изображаются как пустые списки. Таким образом, исходную ситуацию Рисунок 11.1 можно записать как терм
[ [с, а, b], [ ], [ ] ]
Целевая ситуация - это любая конфигурация кубиков, содержащая, столбик, составленный из всех имеющихся кубиков в указанном порядке. Таких ситуаций три:
[ [a, b, c], [ ], [ ] ]
[ [ ], [а, b, с], [ ] ]
[ [ ], [ ], [a, b, c] ]
Отношение следования можно запрограммировать, исходя из следующего правила: ситуация Сит2 есть преемник ситуации Сит1, если в Сит1 имеется два столбика Столб1 и Столб2, такие, что верхний кубик из Столб1 можно поставить сверху на Столб2 и получить тем самым Сит2. Поскольку все ситуации - это списки столбиков, правило транслируется на Пролог так:
после( Столбы, [Столб1, [Верх1 | Столб2], Остальные]) :-
% Переставить Верх1 на Столб2
удалить( [Верх1 | Столб1], Столб1, Столб1),
% Найти первый столбик
удалить( Столб2, Столбы1, Остальные).
% Найти второй столбик
удалить( X, [X | L], L).
удалить( X, [Y | L], [Y | L1] ) :-
удалить( L, X, L1).
В нашем примере целевое условие имеет вид:
цель( Ситуация) :-
принадлежит [а,b,с], Ситуация)
Алгоритм поиска мы запрограммируем как отношение
решить( Старт, Решение)
где Старт - стартовая вершина пространства состояний, а Решение - путь, ведущий из вершины Старт в любую целевую вершину. Для нашего конкретного примера обращение к пролог-системе имеет вид:
?- решить( [ [с, а, b], [ ], [ ] ], Решение).
В результате успешного поиска переменная Решение конкретизируется и превращается в список конфигураций кубиков. Этот список представляет собой план преобразования исходного состояния в состояние, в котором все три кубика поставлены друг на друга в указанном порядке [а, b, с].
Пример простого пространства
Рисунок 11. 4. Пример простого пространства состояний: а - стартовая
вершина, f и j - целевые вершины. Порядок, в которой происходит
проход по вершинам пространства состояний при поиске в глубину:
а, b, d, h, e, i, j. Найдено решение [a, b, e, j]. После возврата
обнаружено другое решение: [а, с, f].

На Пролог это правило транслируется так:
решить( В, [В] ) :-
цель( В).
решить( В, [В | Реш1] ) :-
после( В, В1 ),
решить( В1, Реш1).
Эта программа и есть реализация поиска в глубину. Мы говорим "в глубину", имея в виду тот порядок, в котором рассматриваются альтернативы в пространстве состояний. Всегда, когда алгоритму поиска в глубину надлежит выбрать из нескольких вершин ту, в которую следует перейти для продолжения поиска, он предпочитает самую "глубокую" из них. Самая глубокая вершина - это вершина, расположенная дальше других от стартовой вершины. На Рисунок 11.4 мы видим на примере, в каком порядке алгоритм проходит по вершинам. Этот порядок в точности соответствует результату трассировки процесса вычислений в пролог-системе при ответе на вопрос
?- решить( а, Реш).
Поиск в глубину наиболее адекватен рекурсивному стилю программирования, принятому в Прологе. Причина этого состоит в том, что, обрабатывая цели, пролог-система сама просматривает альтернативы именно в глубину.
Поиск в глубину прост, его легко программировать и он в некоторых случаях хорошо работает. Программа для решения задачи о восьми ферзях (см. гл. 4) фактически была примером поиска в глубину. Для того, чтобы можно было применить к этой задаче описанную выше процедуру решить, необходимо сформулировать задачу в терминах пространства состояний. Это можно сделать так: вершины пространства состояний - позиции, в которых поставлено 0 или более ферзей на нескольких последовательно расположенных горизонтальных линиях доски; вершина-преемник данной вершины может быть получена из нее после того, как в соответствующей позиции на следующую горизонтальную линию доски будет поставлен еще один ферзь, причем таким образом, чтобы ни один из уже поставленных ферзей не оказался под боем; стартовая вершина - пустая доска (представляется пустым списком); целевая вершина - любая позиция с восемью ферзями (правило получения вершины-преемника гарантирует, что ферзи не бьют друг друга).
Позицию на доске будем представлять как список Y-координат поставленных ферзей. Получаем программу:
после( Ферзи, [Ферзь | Ферзи] ) :-
принадлежит( Ферзь, [1, 2, 3, 4, 5, 6, 7, 8] ),
% Поместить ферзя на любую вертикальную линию
небьет( Ферзь, Ферзи).
цель( [ _, _, _, _, _, _, _, _ ] )
% Позиция с восемью ферзями
Отношение небьет означает, что Ферзь не может поразить ни одного ферзя из списка Ферзи. Эту процедуру можно легко запрограммировать так же, как это сделано в гл. 4. Ответ на вопрос
?- решить( [ ], Решение)
будет выглядеть как список позиций с постепенно увеличивающимся количеством поставленных ферзей. Список завершается "безопасной" конфигурацией из восьми ферзей. Механизм возвратов позволит получить и другие решения задачи.
Поиск в глубину часто работает хорошо, как в рассмотренном примере, однако наша простая процедура решить может попасть в затруднительное положение, причем многими способами. Случится ли это или нет - зависит от структуры пространства состояний. Для того, чтобы затруднить работу процедуры решить в примере Рисунок 11.4, достаточно внести в задачу совсем небольшое изменение: добавить дугу, ведущую из h в d, чтобы получился цикл (Рисунок 11.5). В этом случае поиск будет выглядеть так: начиная с вершины а, спускаемся вплоть до h, придерживаясь самой левой ветви графа. На этот раз, в отличие от Рисунок 11.4, у вершины h будет преемник d. Поэтому произойдет не возврат из h, а переход к d. Затем мы найдем преемника вершины d, т.е. вершину h, и т.д., в результате программа зациклится между h и d.
Начинаясь в а поиск вглубину заканчивается бесконечным циклом между d и h a b d h d h d
Рисунок 11. 5. Начинаясь в а, поиск вглубину заканчивается
бесконечным циклом между d и h: a, b, d, h, d, h, d ... .

Очевидное усовершенствование нашей программы поиска в глубину - добавление к ней механизма обнаружения циклов. Ни одну из вершин, уже содержащихся в пути, построенном из стартовой вершины в текущую вершину, не следует вторично рассматривать в качестве возможной альтернативы продолжения поиска. Это правило можно сформулировать в виде отношения
вглубину( Путь, Верш, Решение)
Как видно из Рисунок 11.6, Верш - это состояние, из которого необходимо найти путь до цели; Путь - путь (список вершин) между стартовой вершиной и Верш; Решение - Путь, продолженный до целевой вершины.
Отношение вглубину( Путь В Решение)
Рисунок 11. 6. Отношение вглубину( Путь, В, Решение).

Для облегчения программирования вершины в списках, представляющих пути, будут расставляться в обратном порядке. Аргумент Путь нужен для того,
(1) чтобы не рассматривать тех преемников вершины Верш, которые уже встречались раньше (обнаружение циклов);
(2) чтобы облегчить построение решающего пути Решение. Соответствующая программа поиска в глубину показана на Рисунок 11.7.
line(); решить( Верш, Решение) :-
вглубину( [ ], Верш, Решение).
вглубину( Путь, Верш, [Верш | Путь] ) :-
цель( Верш).
вглубину( Путь, Верш, Реш) :-
после( Верш, Верш1),
not принадлежит( Верш1, Путь),
% Цикл ?
вглубину( [Верш | Путь], Верш1, Реш).
Программа поиска в глубину без зацикливания
Рисунок 11. 7. Программа поиска в глубину без зацикливания.
Теперь наметим один вариант этой программы. Аргументы Путь и Верш процедуры вглубину можно объединить в один список [Верш | Путь]. Тогда, вместо вершины-кандидата Верш, претендующей на то, что она находится на пути, ведущем к цели, мы будем иметь путь-кандидат П = [Верш | Путь], который претендует на то, что его можно продолжить вплоть до целевой вершины. Программирование соответствующего предиката
вглубину( П, Решение)
оставим читателю в качестве упражнения.
Наша процедура поиска в глубину, снабженная механизмом обнаружения циклов, будет успешно находить решающие пути в пространствах состояний, подобных показанному на Рисунок 11.5. Существуют, однако, такие пространства состоянии, в которых наша процедура не дойдет до цели. Дело в том, что многие пространства состояний бесконечны. В таком пространстве алгоритм поиска в глубину может "потерять" цель, двигаясь вдоль бесконечной ветви графа. Программа будет бесконечно долго обследовать эту бесконечную область пространства, так и не приблизившись к цели. Пространство состояний задачи о восьми ферзях, определенное так, как это сделано в настоящем разделе, на первый взгляд содержит ловушку именно такого рода. Но оказывается, что оно все-таки конечно, поскольку Y-координаты выбираются из ограниченного множества, и поэтому на доску можно поставить "безопасным образом" не более восьми ферзей.
line(); вглубину2( Верш, [Верш], _ ) :-
цель( Верш).
вглубину2( Верш, [Верш | Реш], МаксГлуб) :-
МаксГлуб > 0,
после( Верш, Верш1),
Maкс1 is МаксГлуб - 1,
вглубину2( Верш1, Реш, Maкс1).
Программа поиска в глубину с ограничением по глубине
Рисунок 11. 8. Программа поиска в глубину с ограничением по глубине.
Для того, чтобы предотвратить бесцельное блуждание по бесконечным ветвям, мы можем добавить в базовую процедуру поиска в глубину еще одно усовершенствование, а именно, ввести ограничение на глубину поиска. Процедура поиска в глубину будет тогда иметь следующие аргументы:
вглубину2( Верш, Решение, МаксГлуб)
Не разрешается вести поиск на глубине большей, чем МаксГлуб. Программная реализация этого ограничения сводится к уменьшению на единицу величины предела глубины при каждом рекурсивном обращений к вглубину2 и к проверке, что этот предел не стал отрицательным. В результате получаем программу, показанную на Рисунок 11.8.
Простое пространство
Рисунок 11. 9. Простое пространство состояний: а - стартовая вершина,
f и j - целевые вершины. Применение стратегии поиска в ширину
дает следующий порядок прохода по вершинам: а, b, c, d, e, f. Более
короткое решение [a, c, f] найдено раньше, чем более длинное
[а, b, e, j]

нам приходится сохранять все множество альтернативных вершин-кандидатов, а не только одну вершину, как при поиске в глубину. Более того, если мы желаем получить при помощи процесса поиска решающий путь, то одного множества вершин недостаточно. Поэтому мы будем хранить не множество вершин-кандидатов, а множество путей-кандидатов. Таким образом, цель
вширину( Пути, Решения)
истинна только тогда, когда существует путь из множества кандидатов Пути, который может быть продолжен вплоть до целевой вершины. Этот продолженный путь и есть Решение.
Реализации поиска в ширину
Рисунок 11. 10. Реализации поиска в ширину.
путей-кандидатов. Само множество будет списком путей, а каждый путь - списком вершин, перечисленных в обратном порядке, т. е. головой списка будет самая последняя из порожденных вершин, а последним элементом списка будет стартовая вершина. Поиск начинается с одноэлементного множества кандидатов
[ [СтартВерш] ]
Общие принципы поиска в ширину таковы:
Для того, чтобы выполнить поиск в ширину при заданном множестве путей-кандидатов, нужно: если голова первого пути - это целевая вершина, то взять этот путь в качестве решения, иначе удалить первый путь из множества кандидатов и породить множество всех возможных продолжений этого пути на один шаг; множество продолжений добавить в конец множества кандидатов, а затем выполнить поиск в ширину с полученным новым множеством.
В случае примера Рисунок 11.9 этот процесс будет развиваться следующим образом:
line(); решить( Старт, Решение) :-
вширь( [ [Старт] | Z ]-Z, Решение).
вширь( [ [Верш | Путь] | _ ]-_, [Верш | Путь] ) :-
цель( Верш).
вширь( [ [В | Путь] | Пути]-Z, Решение ) :-
bagof( [B1, В | Путь ],
( после( В, В1),
not принадлежит( В1, [В | Путь]) ),
Нов ),
конк( Нов, ZZ, Z), !,
вширь( Пути-ZZ, Решение);
Пути \== Z, % Множество кандидатов не пусто
вширь( Пути-Z, Решение).
Программа поиска
Рисунок 11. 11. Программа поиска в ширину более эффективная, чем
программа Рисунок 11.10. Усовершенствование основано на разностном
представлении списка путей-кандидатов.
(1) Начинаем с начального множества кандидатов:
[ [а] ]
(2) Порождаем продолжения пути [а]:
[ [b, а], [с, а] ]
(Обратите внимание, что пути записаны в обратном порядке.)
(3) Удаляем первый путь из множества кандидатов и порождаем его продолжения:
[ [d, b, a], [e, b, а] ]
Добавляем список продолжений в конец списка кандидатов:
[ [с, а], [d, b, a], [e, b, а] ]
(4) Удаляем [с, а], а затем добавляем все его продолжения в конец множества кандидатов. Получаем:
[ [d, b, a], [e, b, а], [f, c, a], [g, c, a] ]
Далее, после того, как пути [d, b, a] и [e, b, а] будут продолжены, измененный список кандидатов примет вид
[[f, c, a], [g, c, a], [h, d, b, a], [i, e, b, a], [j, e, b, a]]
В этот момент обнаруживается путь [f, c, a], содержащий целевую вершину f. Этот путь выдается в качестве решения.
Программа, порождающая этот процесс, показана на Рисунок 11.10. В этой программе все продолжения пути на один шаг генерируются встроенной процедурой bagof. Кроме того, делается проверка, предотвращающая порождение циклических путей. Обратите внимание на то, что в случае, когда путь продолжить невозможно, и цель bagof терпит неудачу, обеспечивается альтернативный запуск процедуры вширину. Процедуры принадлежит и конк реализуют отношения принадлежности списку и конкатенации списков соответственно.
Недостатком этой программы является неэффективность операции конк. Положение можно исправить, применив разностное представление списков (см. гл. 8). Тогда множество путей-кандидатов будет представлено парой списков Пути и Z, записанной в виде
Пути-Z
При введении этого представления в программу Рисунок 11.10 ее можно постепенно преобразовать в программу, показанную на Рисунок 11.11. Оставим это преобразование читателю в качестве упражнения.
Отношение paсширить(
Рисунок 11. 12. Отношение paсширить( Путь, Дер, Дер1, ЕстьРеш, Решение):
s - стартовая вершина, g - целевая вершина. Решение - это Путь,
продолженный вплоть до g. Дер1 - результат расширения дерева
Дер на один уровень вниз.

получить поддерево Дер1 как результат расширения Дер на один уровень. Но в случае, когда в процессе расширения поддерева Дер встретится целевая вершина, процедура расширить должна сформировать соответствующий решающий путь.
Итак, процедура расширить будет порождать два типа результатов. На конкретный вид результата будет указывать значение переменной ЕстьРеш:
(1) ЕстьРеш = да
Решение
= решающий путь, т. е. Путь, продолженный до целевой вершины.
Дер1
= неконкретизировано.
Разумеется, такой тип результата получится только в том случае, когда Дер будет содержать целевую вершину. Добавим также, что эта целевая вершина обязана быть листом поддерева Дер.
(2) ЕстьРеш = нет
Дер1
= результат расширения поддерева Дер на один уровень вниз от своего "подножья". Дер1
не содержит ни одной "тупиковой" ветви из Дер, т. е. такой ветви, что она либо не может быть продолжена из-за отсутствия преемников, либо любое ее продолжение приводит к циклу.
Решение
= неконкретизировано.
Если в дереве Дер нет ни одной целевой вершины и, кроме того, оно не может быть расширено, то процедура расширить терпит неудачу.
Процедура верхнего уровня для поиска в ширину
вширину( Дер, Решение)
отыскивает Решение либо среди множества кандидатов Дер, либо в его расширении. На Рисунок 11.3 показано, как выглядит программа целиком. В этой программе имеется вспомогательная процедура расширитьвсе. Она расширяет все деревья из некоторого списка, и затем, выбросив все "тупиковые" деревья", собирает все полученные расширенные деревья в один новый список. Используя механизм возвратов, она также порождает все решения, обнаруженные в деревьях из списка. Имеется одна дополнительная деталь: по крайней мере одно из деревьев должно "вырасти". Если это не так, то процедуре расширитьвсе не удается получить ни одного расширенного дерева - все деревья из списка оказываются "тупиковыми".
line();% ПОИСК В ШИРИНУ
% Множество кандидатов представлено деревом
решить( Старт, Решение) :-
вширину( л( Старт), Решение).
вширину( Дер, Решение) :-
расширить( [ ], Дер, Дер1, ЕстьРеш, Решение),
( ЕстьРеш = да;
ЕстьРеш = нет, вширину( Дер1, Решение) ).
расширить( П, Л( В), _, да, [В | П] ) :-
цель( В).
расширить( П, Л( В), д( В, Пд), нет, _ ) :-
bagof( л( B1),
( после( В, B1), not принадлежит( В1, П)), Пд).
расширить( П, д( В, Пд), д( В, Пд1), ЕстьРеш, Реш) :-
расширитьвсе( [В | П], Пд, [ ], Пд1, ЕстьРеш, Реш).
расширитьвсе( _, [ ], [Д | ДД], [Д | ДД], нет, _ ).
% По крайней мере одно дерево должно вырасти
расширитьвсе( П, [Д | ДД], ДД1, Пд1, ЕстьРеш, Реш) :-
расширить ( П, Д, Д1, ЕстьРеш1, Реш),
( ЕстьРеш 1= да, ЕстьРеш = да;
ЕстьРеш1 = нет, !,
расширитьвсе( П, ДД, [Д1 | ДД1], Пд1, ЕстьРеш, Реш));
расширитьвсе( П, ДД, ДД1, Пд1, ЕстьРеш, Реш ).
Реализация поиска
Рисунок 11. 13. Реализация поиска в ширину с использованием
древовидного представления множества путей-кандидатов.
Мы разработали эту более сложную реализацию поиска в ширину не только для того, чтобы получать программу более экономичную по сравнению с предыдущей версией, но также и потому, что такое решение задачи может послужить хорошим стартом для перехода к усложненным программам поиска, управляемым эвристиками, таким как программа поиска с предпочтением из гл. 12.
а) Пространство
Рисунок 11. 14. (а) Пространство состояний; а - стартовая вершина.
(b) Дерево всех возможных ациклических путей, ведущих из а,
порожденное программой поиска в ширину.

длин - самые короткие решения идут первыми. Это является важным обстоятельством, если нам необходима оптимальность (в отношении длины решения). Стратегия поиска в ширину гарантирует получение кратчайшего решения первым. Разумеется, это неверно для поиска в глубину.
Наши программы, однако, не учитывают стоимости, приписанные дугам в пространстве состояний. Если критерием оптимальности является минимум стоимости решающего пути (а не его длина), то в этом случае поиска в ширину недостаточно. Поиск с предпочтением из гл. 12 будет направлен на оптимизацию стоимости.
Еще одна типичная проблема, связанная с задачей поиска, - это проблема комбинаторной сложности. Для нетривиальных предметных областей число альтернатив столь велико, что проблема сложности часто принимает критический характер. Легко понять, почему это происходит: если каждая вершина имеет b преемников, то число путей длины l, ведущих из стартовой вершины, равно bl ( в предположении, что циклов нет). Таким образом, вместе с увеличением длин путей наблюдается экспоненциальный рост объема множества путей-кандидатов, что приводит к ситуации, называемой комбинаторным взрывом. Стратегии поиска в глубину и ширину недостаточно "умны" для борьбы с такой степенью комбинаторной сложности: отсутствие селективности приводит к тому, что все пути рассматриваются как одинаково перспективные.
По-видимому, более изощренные процедуры поиска должны использовать какую-либо информацию, отражающую специфику данной задачи, с тем чтобы на каждой стадии поиска принимать решения о наиболее перспективных путях поиска. В результате процесс будет продвигаться к целевой вершине, обходя бесполезные пути. Информация, относящаяся к конкретной решаемой задаче и используемая для управления поиском, называется эвристикой. Про алгоритмы, использующие эвристики, говорят, что они руководствуются эвристиками: они выполняют эвристический поиск. Один из таких методов изложен в следующей главе.
как продолжение пути ПутьКандидат. Оба
Упражнения
11. 1. Напишите процедуру поиска в глубину (с обнаружением циклов)
вглубину1( ПутьКандидат, Решение)
отыскивающую решающий путь Решение как продолжение пути ПутьКандидат. Оба пути представляйте списками вершин, расположенных в обратном порядке так, что целевая вершина окажется в голове списка Решение.
Посмотреть ответ
11. 2. Напишите процедуру поиска в глубину, сочетающую в себе обнаружение циклов с ограничением глубины, используя Рисунок 11.7 и 11.8.
11. 3. Проведите эксперимент по применению программы поиска в глубину к задаче планирования в "мире кубиков" (Рисунок 11.1).
11. 4. Напишите процедуру
отобр( Ситуация)
для отображения состояния задачи "перестановки кубиков". Пусть Ситуация - это список столбиков, а столбик, в свою очередь, - список кубиков. Цель
отобр( [ [a], [e, d], [с, b] ] )
должна отпечатать соответствующую ситуацию, например так:
е с
a d b
================
используя разностное представление для списка
Упражнения
11. 5. Перепишите программу поиска в ширину Рисунок 11.10, используя разностное представление для списка путей-кандидатов и покажите, что в результате получится программа, приведенная на Рисунок 11.11. Зачем в программу Рисунок 11.11 включена цель
Пути \== Z
Проверьте, что случится при поиске в пространстве состояний Рисунок 11.9, если эту цель опустить. Различие в выполнении программы, возникнет только при попытке найти новые решения в ситуации, когда не осталось больше ни одного решения.
11. 6. Как программы настоящего раздела можно использовать для поиска, начинающегося от стартового множества вершин, вместо одной стартовой вершины?
Посмотреть ответ
11. 7. Как программы этой главы можно использовать для поиска в обратном направлении, т.е. от целевой вершины к стартовой вершине (или к одной из стартовых вершин, если их несколько). Указание: переопределите отношение после. В каких ситуациях обратный поиск будет иметь преимущества перед прямым поиском?
11. 8. Иногда выгодно сделать поиск двунаправленным, т. е. продвигаться одновременно с двух сторон от стартовой и целевой вершин. Поиск заканчивается, когда оба пути "встречаются". Определите пространство поиска (отношение после) и целевое отношение для заданного графа таким образом, чтобы наши процедуры поиска в действительности выполняли двунаправленный поиск.
11. 9. Проведите эксперименты с различными методами поиска применительно к задаче планирования в "мире кубиков".
Поиск с предпочтением
12. 1. Поиск с предпочтением
Программу поиска с предпочтением можно получить как результат усовершенствования программы поиска в ширину (Рисунок 11.13). Подобно поиску в ширину, поиск с предпочтением начинается со стартовой вершины и использует множество путей-кандидатов. В то время, как поиск в ширину всегда выбирает для продолжения самый короткий путь (т.е. переходит в вершины наименьшей глубины), поиск с предпочтением вносит в этот принцип следующее усовершенствование: для каждого кандидата вычисляется оценка и для продолжения выбирается кандидат с наилучшей оценкой.
Поиск c предпочтением применительно к головоломке "игра в восемь"
12. 2. Поиск c предпочтением применительно к головоломке "игра в восемь"
Если мы хотим применить программу поиска с предпочтением, показанную на Рисунок 12.3, к какой-нибудь задаче, мы должны добавить к нашей программе отношения, отражающие специфику этой конкретной задачи. Эти отношения определяют саму задачу ("правила игры"), а также вносят в алгоритм эвристическую информацию о методе ее решения. Эвристическая информация задается в форме эвристической функции.
line();/* Процедуры, отражающие специфику головоломки
"игра в восемь".
Текущая ситуация представлена списком положений фишек;
первый элемент списка соответствует пустой клетке.
Пример:
| 3 2 1 |
| 1 2 3 8 4 7 6 5 |
[2/2, 1/3, 2/3, 3/3, 3/2, 3/1, 2/1, 1/1, 1/2]
"Пусто" можно перемещать в любую соседнюю клетку,
т.е. "Пусто" меняется местами со своим соседом.
*/
после( [Пусто | Спис], [Фшк | Спис1], 1) :-
% Стоимости всех дуг равны 1
перест( Пусто, Фшк, Спис, Спис1).
% Переставив Пусто и Фшк, получаем СПИС1
перест( П, Ф, [Ф | С], [П | С] ) :-
расст( П, Ф, 1).
перест( П, Ф, [Ф1 | С], [Ф1 | С1] ) :-
перест( П, Ф, С, С1).
расст( X/Y, X1/Y1, Р) :-
% Манхеттеновское расстояние между клетками
расст1( X, X1, Рх),
расст1( Y, Y1, Ру),
Р is Рх + Py.
расст1( А, В, Р) :-
Р is А-В, Р >= 0, ! ;
Р is B-A.
% Эвристическая оценка h равна сумме расстояний фишек
% от их "целевых" клеток плюс "степень упорядоченности",
% умноженная на 3
h( [ Пусто | Спис], H) :-
цель( [Пусто1 | Цспис] ),
сумрасст( Спис, ЦСпис, Р),
упоряд( Спис, Уп),
Н is Р + 3*Уп.
сумрасст( [ ], [ ], 0).
сумрасст( [Ф | С], [Ф1 | С1], Р) :-
расст( Ф, Ф1, Р1),
сумрасст( С, Cl, P2),
Р is P1 + Р2.
упоряд( [Первый | С], Уп) :-
упоряд( [Первый | С], Первый, Уп).
упоряд( [Ф1, Ф2 | С], Первый, Уп) :-
очки( Ф1, Ф2, Уп1),
упоряд( [Ф2 | С], Первый, Уп2),
Уп is Уп1 + Уп2.
упоряд( [Последний], Первый, Уп) :-
очки( Последний, Первый, Уп).
очки( 2/2, _, 1) :- !. % Фишка в центре - 1 очко
очки( 1/3, 2/3, 0) :- !.
% Правильная последовательность - 0 очков
очки( 2/3, 3/3, 0) :- !.
очки( 3/3, 3/2, 0) :- !.
очки( 3/2, 3/1, 0) :- !.
очки( 3/1, 2/1, 0) :- !.
очки( 2/1, 1/1, 0) :- !.
очки( 1/1, 1/2, 0) :- !.
очки( 1/2, 1/3, 0) :- !.
очки( _, _, 2). % Неправильная последовательность
цель( [2/2, 1/3, 2/3, 3/3, 3/2, 3/1, 2/1, 1/1, 1/2] ).
% Стартовые позиции для трех головоломок
старт1( [2/2, 1/3, 3/2, 2/3, 3/3, 3/1, 2/1, 1/1, 1/2] ).
% Требуется для решения 4 шага
старт2( [2/1, 1/2, 1/3, 3/3, 3/2, 3/1, 2/2, 1/1, 2/3] ).
% 5 шагов
старт3( [2/2, 2/3, 1/3, 3/1, 1/2, 2/1, 3/3, 1/1, 3/2] ).
% 18 шагов
% Отображение решающего пути в виде списка позиций на доске
показреш( [ ]).
показреш( [ Поз | Спис] :-
показреш( Спис),
nl, write( '---'),
показпоз( Поз).
% Отображение позиции на доске
показпоз( [S0, S1, S2, S3, S4, S5, S6, S7, S8] ) :-
принадлежит Y, [3, 2, 1] ), % Порядок Y-координат
nl, принадлежит X, [1, 2, 3] ),
% Порядок Х-координат
принадлежит( Фшк-X/Y,
[' '-S0, 1-S1, 2-S2, 3-S3, 4-S4, 5-S5, 6-S6, 7-S7, 8-S8]),
write( Фшк),
fail.
%Возврат с переходом к следующей клетке
показпоз( _ ).
line();Применение поиска с предпочтением к планированию выполнения задач
12. 3. Применение поиска с предпочтением к планированию выполнения задач
Рассмотрим следующую задачу планирования. Дана совокупность задач t1, t2, ..., имеющих времена выполнения соответственно T1, Т2, ... . Все эти задачи нужно решить на m идентичных процессорах. Каждая задача может быть решена на любом процессоре, но в каждый данный момент каждый процессор решает только одну из задач. Между задачами существует отношение предшествования, определяющее, какие задачи (если таковые есть) должны быть завершены, прежде чем данная задача может быть запущена. Необходимо распределить задачи между процессорами без нарушения отношения предшествования, причем таким образом, чтобы вся совокупность задач была решена за минимальное время. Время, когда последняя задача в соответствии с выработанным планом завершает свое решение, называется временем окончания плана. Мы хотим минимизировать время окончания по всем возможным планам.
На Рисунок 12.8 показан пример задачи планирования, а также приведено два корректных плана, один из которых оптимален. Из примера видно, что оптимальный план обладает одним интересным свойством, а именно в нем может предусматриваться "время простоя" процессоров. В оптимальном плане Рисунок 12.8 процессор 1, выполнив задачу t, ждет в течение двух квантов времени, несмотря на то, что он мог бы начать выполнение задачи t.
Один из способов построить план можно грубо сформулировать так. Начинаем с пустого плана (с незаполненными временными промежутками для каждого процессора) и постепенно включаем в него задачи
Литература
Литература
Программа поиска с предпочтением, представленная в настоящей главе, - это один из многих вариантов похожих друг на друга программ, из которых А*-алгоритм наиболее популярен. Общее описание А*-алгоритма можно найти в книгах Nillson (1971, 1980) или Winston (1984). Теорема о допустимости впервые доказана авторами статьи Hart, Nilsson, and Raphael (1968). Превосходное и строгое изложение многих разновидностей алгоритмов поиска с предпочтением и связанных с ними математических результатов дано в книге Pearl (1984). В статье Doran and Michie (1966) впервые изложен поиск с предпочтением, управляемый оценкой расстояния до цели.
Головоломка "игра в восемь" использовалась многими исследователями в области искусственного интеллекта в качестве тестовой задачи при изучении эвристических принципов (см., например, Doran and Michie (1966), Michie and Ross (1970) и Gaschnig (1979) ).
Задача планирования, рассмотренная в настоящей главе, также как и многие ее разновидности, возникает во многих прикладных областях в ситуации, когда необходимо спланировать обслуживание запросов на ресурсы. Один из примеров - операционные системы вычислительных машин. Задача планирования со ссылкой на это конкретное приложение изложена в книге Coffman and Denning (1973).
Найти хорошую эвристику - дело важное и трудное, поэтому изучение эвристик - одна из центральных тем в искусственном интеллекте. Существуют, однако, некоторые границы, за которые невозможно выйти, двигаясь в направлении улучшения качества эвристик. Казалось бы, все, что необходимо для эффективного решения комбинаторной задачи - это найти мощную эвристику. Однако есть задачи (в том числе многие задачи планирования), для которых не существует универсальной эвристики, обеспечивающей во всех случаях как эффективность, так и допустимость. Многие теоретические результаты, имеющие отношение к этому ограничению, собраны в работе Garey and Johnson (1979).
Coffman E.G. and Denning P.J. (1973). Operating Systems Theory. Prentice-Hall.
Doran J. and Michie D. (1966). Experiments with the graph traverser program. Proc. Royal Socieiy of London 294(A): 235-259.
Garey M. R. and Johnson D. S. (1979). Computers and Intractability. W. H. Freeman. [Имеется перевод: Гэри M., Джонсон Д. С- Вычислительные машины и труднорешаемые задачи.- M.: Мир, 1982.]
Gaschnig J. (1979). Performance measurement and analysis of certain search algorithms. Carnegie-Mellon University: Computer Science Department-Technical Report CMU-CS-79-124 (Ph. D. Thesis).
Hart P.E., Nilsson N.J. and Raphael B. (1968). A formal basis for the heuristic determination of minimum cost paths. IEEE Transactions on Systems Sciences and Cybernetics SSC-4(2):100-107
Michie D. and Ross R. (1970). Experiments with the adaptive graph traverser. Machine Intelligence 5: 301-308.
Nilsson N.J. (1971). Problem - Solving Methods in Artificial Intelligence. McGraw-Hill. [Имеется перевод: Нильсон H. Искусственный интеллект. Методы поиска решений. - M: Мир, 1973.]
Nilsson N. J. (1980). Principles of Artificial Intelligence. Tioga; also Springer-Verlag.
Pearl J. (1984). Heuristics: Intelligent Search Strategies for Computer Problem Solving. Addison-Wesley.
Winston P. H. (1984). Artificial Intelligence (second edition). Addison-Wesley. [Имеется перевод первого издания: Уинстон П. Искусственный интеллект. - M.: Мир, 1980.]
Проект
Проект

Вообще говоря, задачи планирования характеризуются значительной комбинаторной сложностью. Наша простая эвристическая функция не обеспечивает высокой эффективности управления поиском. Предложите другие эвристические функции и проведите с ними эксперименты.
line();/* Отношения для задачи планирования.
Вершины пространства состояний - частичные планы,
записываемые как
[ Задача1/Т1, Задача2/Т2, ...]*
[ Задача1/К1, Задача2/К2, ...]* ВремяОкончания
В первом списке указываются ждущие задачи и продолжительности их выполнения; во втором - текущие решаемые задачи и их времена окончания, упорядоченные так, чтобы выполнялись неравенства K1<=K2, K2<=K3, ... . Время окончания плана - самое последнее по времени время окончания задачи.
*/
после( Задачи1*[ _ /К | Акт1]*Кон1, Задачи2*Акт2*Кон2,Ст):-
удалить( Задача/Т, Задачи1, Задачи2),
% Взять ждущую задачу
not( принадлежит( Здч1/_, Задачи2),
раньше( ЗДЧ, Задача) ),
% Проверить предшествование
not( принадлежит( Здч1/К1, Акт1), К1<К2,
раньше( К1, Задача) ), % Активные задачи
Время is К + Т,
% Время окончания работающей задачи
встав( ЗадачаВремя, Акт1, Акт2, Кон1, Кон2),
Ст is Кон2 - Кон1.
после( Задачи*[ _ /К | Акт1]*Кон, Задачи2*Акт2*Кон, 0):-
вставпростой( К, Акт1, Акт2).
% Оставить процессор бездействующим
раньше( Задача1, Задача2) :-
% В соответствии с предшествованием
предш( Задача1, Задача2).
% Задача1 раньше, чем Задача2
раньше( Здч1, Здч2) :-
предш( Здч, Здч2),
раньше( Здч1, Здч).
встав( Здч/А, [Здч1/В | Спис], [Здч/А, Здч1/В | Спис], К, К):-
% Список задач упорядочен
А =< В, !.
встав( Здч/А, [Здч1/В | Спнс], [Здч1/В | Спис1], К1, К2) :-
встав( Здч/А, Спис, Спис1, Kl, К2).
встав( Здч/А, [ ], [Здч/А], _, А).
вставпростой( А, [Здч/В | Спис], [простой/В, Здч/В | Спис]):-
% Оставить процессор бездействующим
А < В, !
% До ближайшего времени окончания
вставпростой( А, [Здч/В | Спис], [Здч/В | Спис1]) :-
вставпростой( А, Спис, Спис1 ).
удалить( А, [А | Спис], Спис ).
% Удалить элемент из списка
удалить( А, [В | Спис], [В | Спис1] ):-
удалить( А, Спис, Спис1 ).
цель( [ ] *_*_ ). % Целевое состояние: нет ждущих задач
% Эвристическая оценка частичного плана основана на
% оптимистической оценке последнего времени окончания
% этого частичного плана,
% дополненного всеми остальными ждущими задачами.
h( Задачи * Процессоры * Кон, Н) :-
сумвремя( Задачи, СумВремя),
% Суммарная продолжительность
% ждущих задач
всепроц( Процессоры, КонВремя, N),
% КонВремя - сумма времен окончания
% для процессоров, N - их количество
ОбщКон is ( СумВремя + КонВремя)/N,
( ОбщКон > Кон, !, H is ОбщКон - Кон; Н = 0).
сумвремя( [ ], 0).
сумвремя( [ _ /Т | Задачи], Вр) :-
сумвремя( Задачи, Вр1),
Вр is Bp1 + Т.
всепроц( [ ], 0, 0).
всепроц( [ _ /T | СписПроц], КонВр, N) :-
всепроц( СписПроц, КонВр1, N1),
N is N1 + 1,
КонВр is КонВр1 + Т.
% Граф предшествования задач
предш( t1, t4). предш( t1, t5). предш( t2, t4).
предш( t2, t5). предш( t3, t5). предш( t3, t6).
предш( t3, t7).
% Стартовая вершина
старт( [t1/4, t2/2, t3/2, t4/20, t5/20, t6/11, t7/11] *
[простой/0, простой/0, простой/0] * 0 ).
Для оценки степени удаленности некоторой
Резюме
Для оценки степени удаленности некоторой вершины пространства состояний от ближайшей целевой вершины можно использовать эвристическую информацию. В этой главе были рассмотрены численные эвристические оценки. Эвристический принцип поиска с предпочтением направляет процесс поиска таким образом, что для продолжения поиска всегда выбирается вершина, наиболее перспективная с точки зрения эвристической оценки. В этой главе был запрограммирован алгоритм поиска, основанный на указанном принципе и известный в литературе как А*-алгоритм. Для того, чтобы решить конкретную задачу при помощи А*-алгоритма, необходимо определить пространство состояний и эвристическую функцию. Для сложных задач наиболее трудным моментом является подбор хорошей эвристической функции. Теорема о допустимости помогает установить, всегда ли А*-алгоритм, использующий некоторую конкретную эвристическую функцию, находит оптимальное решение.
Построение эвристической
Рисунок 12. 1. Построение эвристической оценки f(n) стоимости
самого дешевого пути из s в t, проходящего через n: f(n) = g(n) + h(n).

Мы будем в дальнейшем предполагать, что для дуг пространства состояний определена функция стоимости с(n, n') - стоимость перехода из вершины n к вершине-преемнику n'.
Пусть f - это эвристическая оценочная функция, при помощи которой мы получаем для каждой вершины n оценку f( n) "трудности" этой вершины. Тогда наиболее перспективной вершиной-кандидатом следует считать вершину, для которой f принимает минимальное значение. Мы будем использовать здесь функцию f специального вида, приводящую к хорошо известному А*-алгоритму. Функция f( n) будет построена таким образом, чтобы давать оценку стоимости оптимального решающего пути из стартовой вершины s к одной из целевых вершин при условии, что этот путь проходит через вершину n. Давайте предположим, что такой путь существует и что t - это целевая вершина, для которой этот путь минимален. Тогда оценку f( n) можно представить в виде суммы из двух слагаемых (Рисунок 12.1):
f( n) = g( n) + h( n)
Здесь g( n) - оценка оптимального пути из s в n; h( n) - оценка оптимального пути из n в t.
Когда в процессе поиска мы попадаем в вершину n, мы оказываемся в следующей ситуация: путь из s в n уже найден, и его стоимость может быть вычислена как сумма стоимостей составляющих его дуг. Этот путь не обязательно оптимален (возможно, существует более дешевый, еще не найденный путь из s в n), однако стоимость этого пути можно использовать в качестве оценки g(n) минимальной стоимости пути из s в n. Что же касается второго слагаемого h(n), то о нем трудно что-либо сказать, поскольку к этому моменту область пространства состояний, лежащая между n и t, еще не "изучена" программой поиска. Поэтому, как правило, о значении h(n) можно только строить догадки на основании эвристических соображений, т.е. на основании тех знаний о конкретной задаче, которыми обладает алгоритм. Поскольку значение h зависит от предметной области, универсального метода для его вычисления не существует. Конкретные примеры того, как строят эти "эвристические догадки", мы приведем позже. Сейчас же будем считать, что тем или иным способом функция h задана, и сосредоточим свое внимание на деталях нашей программы поиска с предпочтением.
Можно представлять себе поиск с предпочтением следующим образом. Процесс поиска состоит из некоторого числа конкурирующих между собой подпроцессов, каждый из которых занимается своей альтерна-
Поиск кратчайшего
Рисунок 12. 2. Поиск кратчайшего маршрута из s в t. (а) Карта со
связями между городами; связи помечены своими длинами; в
квадратиках указаны расстояния по прямой до цели t.
(b) Порядок, в котором при поиске с предпочтением происходит
обход городов. Эвристические оценки основаны на расстояниях
по прямой. Пунктирной линией показано переключение активности
между альтернативными путями. Эта линия задает тот порядок, в
котором вершины принимаются для продолжения пути, а не тот
порядок, в котором они порождаются.

тивой, т.е. просматривает свое поддерево. У поддеревьев есть свои поддеревья, их просматривают подпроцессы подпроцессов и т.д. В каждый данный момент среди всех конкурирующих процессов активен только один - тот, который занимается наиболее перспективной к настоящему моменту альтернативой, т.е. альтернативой с наименьшим значением f. Остальные процессы спокойно ждут того момента, когда f-оценки изменятся и в результате какая-нибудь другая альтернатива станет наиболее перспективной. Тогда производится переключение активности на эту альтернативу. Механизм активации-дезактивации процессов функционирует следующим образом: процесс, работающий над текущей альтернативой высшего приоритета, получает некоторый "бюджет" и остается активным до тех пор, пока его бюджет не исчерпается. Находясь в активном состоянии, процесс продолжает углублять свое поддерево. Встретив целевую вершину, он выдает соответствующее решение. Величина бюджета, предоставляемого процессу на данный конкретный запуск, определяется эвристической оценкой конкурирующей альтернативы, ближайшей к данной.
На Рисунок 12.2 показан пример поведения конкурирующих процессов. Дана карта, задача состоит в том, чтобы найти кратчайший маршрут из стартового города s в целевой город t. В качестве оценки стоимости остатка маршрута из города Х до цели мы будем использовать расстояние по прямой расст( X, t) от Х до t. Таким образом,
f( Х) = g( X) + h( X) = g( X) + расст( X, t)
Мы можем считать, что в данном примере процесс поиска с предпочтением состоит из двух процессов. Каждый процесс прокладывает свой путь - один из двух альтернативных путей: Процесс 1 проходит через а. Процесс 2 - через е. Вначале Процесс 1 более активен, поскольку значения f вдоль выбранного им пути меньше, чем вдоль второго пути. Когда Процесс 1 достигает города с, а Процесс 2 все еще находится в е, ситуация меняется:
f( с) = g( c) + h( c) = 6 + 4 = 10
f( e) = g( e) + h( e) = 2 + 7 = 9
Поскольку f( e) < f( c), Процесс 2 переходит к f, a Процесс 1 ждет. Однако
f( f) = 7 + 4 = 11
f( c) = 10
f( c) < f( f)
Поэтому Процесс 2 останавливается, а Процессу 1 дается разрешение продолжать движение, но только до d, так как f( d) = 12 > 11. Происходит активация Процесса 2, после чего он, уже не прерываясь, доходит до цели t.
Мы реализуем этот механизм программно при помощи усовершенствования программы поиска в ширину (Рисунок 11.13). Множество путей-кандидатов представим деревом. Дерево будет изображаться в программе в виде терма, имеющего одну из двух форм:
(1) л( В, F/G) - дерево, состоящее из одной вершины (листа); В - вершина пространства состояний, G - g( B) (стоимость уже найденного пути из стартовой вершины в В); F - f( В) = G + h( В).
(2) д( В, F/G, Пд) - дерево с непустыми поддеревьями; В - корень дерева, Пд - список поддеревьев; G - g( B); F - уточненное значение f( В), т.е. значение f для наиболее перспективного преемника вершины В; список Пд упорядочен в порядке возрастания f-оценок поддеревьев.
Уточнение значения f необходимо для того, чтобы дать программе возможность распознавать наиболее перспективное поддерево (т.е. поддерево, содержащее наиболее перспективную концевую вершину) на любом уровне дерева поиска. Эта модификация f-оценок на самом деле приводит к обобщению, расширяющему область определения функции f. Теперь функция f определена не только на вершинах, но и на деревьях. Для одновершинных деревьев (листов) n остается первоначальное определение
f( n) = g( n) + h( n)
Для дерева T с корнем n, имеющем преемников m1, m2, ..., получаем
f( T) = min f( mi
)
i
Программа поиска с предпочтением, составленная в соответствии с приведенными выше общими соображениями, показана на рис 12.3. Ниже даются некоторые дополнительные пояснения.
Так же, как и в случае поиска в ширину (Рисунок 11.13), ключевую роль играет процедура расширить, имеющая на этот раз шесть аргументов:
расширить( Путь, Дер, Предел, Дер1, ЕстьРеш, Решение)
Эта процедура расширяет текущее (под)дерево, пока f-оценка остается равной либо меньшей, чем Предел.
line();% Поиск с предпочтением
эврпоиск( Старт, Решение):-
макс_f( Fмакс).
% Fмакс > любой f-оценки
расширить( [ ], л( Старт, 0/0), Fмакс, _, да, Решение).
расширить( П, л( В, _ ), _, _, да, [В | П] ) :-
цель( В).
расширить( П, л( В, F/G), Предел, Дер1, ЕстьРеш, Реш) :-
F <= Предел,
( bagof( B1/C, ( после( В, В1, С), not принадлежит( В1, П)),
Преемники), !,
преемспис( G, Преемники, ДД),
опт_f( ДД, F1),
расширить( П, д( В, F1/G, ДД), Предел, Дер1,
ЕстьРеш, Реш);
ЕстьРеш = никогда).
% Нет преемников - тупик
расширить( П, д( В, F/G, [Д | ДД]), Предел, Дер1,
ЕстьРеш, Реш):-
F <= Предел,
опт_f( ДД, OF), мин( Предел, OF, Предел1),
расширить( [В | П], Д, Предел1, Д1, ЕстьРеш1, Реш),
продолжить( П, д( В, F/G, [Д1, ДД]), Предел, Дер1,
ЕстьРеш1, ЕстьРеш, Реш).
расширить( _, д( _, _, [ ]), _, _, никогда, _ ) :- !.
% Тупиковое дерево - нет решений
расширить( _, Дер, Предел, Дер, нет, _ ) :-
f( Дер, F), F > Предел.
% Рост остановлен
продолжить( _, _, _, _, да, да, Реш).
продолжить( П, д( В, F/G, [Д1, ДД]), Предел, Дер1,
ЕстьРеш1, ЕстьРеш, Реш):-
( ЕстьРеш1 = нет, встав( Д1, ДД, НДД);
ЕстьРеш1 = никогда, НДД = ДД),
опт_f( НДД, F1),
расширить( П, д( В, F1/G, НДД), Предел, Дер1,
ЕстьРеш, Реш).
преемспис( _, [ ], [ ]).
преемспис( G0, [В/С | ВВ], ДД) :-
G is G0 + С,
h( В, Н),
% Эвристика h(B)
F is G + Н,
преемспис( G0, ВВ, ДД1),
встав( л( В, F/G), ДД1, ДД).
% Вставление дерева Д в список деревьев ДД с сохранением
% упорядоченности по f-оценкам
встав( Д, ДД, [Д | ДД] ) :-
f( Д, F), опт_f( ДД, F1),
F =< F1, !.
встав( Д, [Д1 | ДД], [Д1 | ДД1] ) ) :-
встав( Д, ДД, ДД1).
% Получение f-оценки
f( л( _, F/_ ), F). % f-оценка листа
f( д( _, F/_, _ ) F). % f-оценка дерева
опт_f( [Д | _ ], F) :-
% Наилучшая f-оценка для
f( Д, F).
% списка деревьев
опт_f( [ ], Fмакс) :-
% Нет деревьев:
мaкс_f( Fмакс).
% плохая f-оценка
мин( X, Y, X) :-
Х =< Y, !.
мин( X, Y, Y).
line();Программа поиска с предпочтением
Рисунок 12. 3. Программа поиска с предпочтением.
Аргументы процедуры расширить имеют следующий смысл:
Путь Путь между стартовой вершиной и корнем дерева Дер.
Дер Текущее (под)дерево поиска.
Предел Предельное значение f-оценки, при котором допускается расширение.
Дер1 Дерево Дер, расширенное в пределах ограничения Предел;
f-оценка дерева Дер1 больше, чем Предел
( если только при расширении не была обнаружена целевая вершина).
ЕстьРеш Индикатор, принимающий значения "да", "нет" и "никогда".
Решение Решающий путь, ведущий из стартовой вершины через дерево Дер1
к целевой вершине и имеющий стоимость, не превосходящую ограничение Предел (если такая целевая вершина была обнаружена).
Переменные Путь, Дер, и Предел - это "входные" параметры процедуры расширить в том смысле, что при каждом обращении к расширить они всегда конкретизированы. Процедура расширить порождает результаты трех видов. Какой вид результата получен, можно определить по значению индикатора ЕстьРеш следующим образом:
(1) ЕстьРеш = да.
Решение = решающий путь, найденный при расширении дерева Дер с учетом ограничения Предел.
Дер1 = неконкретизировано.
(2) ЕстьРеш = нет
Дер1 = дерево Дер, расширенное до тех пор, пока его f-оценка не превзойдет Предел (см. Рисунок 12.4).
Решение = неконкретизировано.
(3) ЕстьРеш = никогда.
Дер1 и Решение = неконкретизированы.
В последнем случае Дер является "тупиковой" альтернативой, и соответствующий процесс никогда не будет реактивирован для продолжения просмотра этого дерева. Случай этот возникает тогда, когда f-оценка дерева Дер не превосходит ограничения Предел, однако дерево не может "расти" потому, что ни один его лист не имеет преемников, или же любой преемник порождает цикл.
Некоторые предложения процедуры расширить требуют пояснений. Предложение, относящееся к наиболее сложному случаю, когда Дер имеет поддеревья, т.е.
Дер = д( В, F/G, [Д | ДД ] )
означает следующее. Во-первых, расширению подвергается наиболее перспективное дерево Д. В качестве ограничения этому дереву выдается не Предел, а не-
Отношение расширить
Рисунок 12. 4. Отношение расширить: расширение дерева Дер до тех
пор, пока f-оценка не превзойдет Предел, приводит к дереву Дер1.
которое, возможно, меньшее значение Предел1, зависящее от f-оценок других конкурирующих поддеревьев ДД. Тем самым гарантируется, что "растущее" дерево - это всегда наиболее перспективное дерево, а переключение активности между поддеревьями происходит в соответствии с их f-оценками. После того, как самый перспективный кандидат расширен, вспомогательная процедура продолжить решает, что делать дальше, а это зависит от типа результата, полученного после расширения. Если найдено решение, то оно и выдается, в противном случае процесс расширения деревьев продолжается.
Предложение, относящееся к случаю
Дер = л( В, F/G)
порождает всех преемников вершины В вместе со стоимостями дуг, ведущих в них из В. Процедура преемспис формирует список поддеревьев, соответствующих вершинам-преемникам, а также вычисляет их g- и f-оценки, как показано на Рисунок 12.5. Затем полученное таким образом дерево подвергается расширению с учетом ограничения Предел. Если преемников нет, то переменной ЕстьРеш придается значение "никогда" и в результате лист В покидается навсегда.
Другие отношения:
после( В, В1, С) В1 - преемник вершины В; С - стоимость дуги, ведущей из В в В1.
h( В, Н)
Н - эвристическая оценка стоимости оптимального пути
из вершины В в целевую вершину.
макс_f( Fмакс)
Fмакс - некоторое значение, задаваемое пользователем,
про которое известно, что оно больше любой возможной f-оценки.
В следующих разделах мы покажем на примерах, как можно применить нашу программу поиска с предпочтением к конкретным задачам. А сейчас сделаем несколько заключительных замечаний общего характера относительно этой программы. Мы реализовали один из вариантов эвристического алгоритма, известного в литературе как А*-алгоритм (ссылки на литературу см. в конце главы). А*-алгоритм привлек внимание многих исследователей. Здесь мы приведем один важный результат, полученный в результате математического анализа А*-алгоритма:
Связь между gоценкой
Рисунок 12. 5. Связь между g-оценкой вершины В и f- и g-оценками
ее "детей" в пространстве состояний.

line();
Алгоритм поиска пути называют допустимым, если он всегда отыскивает оптимальное решение (т.е. путь минимальной стоимости) при условии, что такой путь существует. Наша реализация алгоритма поиска, пользуясь механизмом возвратов, выдает все существующие решения, поэтому, в нашем случае, условием допустимости следует считать оптимальность первого из найденных решений. Обозначим через h*(n) стоимость оптимального пути из произвольной вершины n в целевую вершину. Верна следующая теорема о допустимости А*-алгоритма: А*-алгоритм, использующий эвристическую функцию h, является допустимым, если
h( n) <= h*( n)
для всех вершин n пространства состояний.
line();Этот результат имеет огромное практическое значение. Даже если нам не известно точное значение h*, нам достаточно найти какую-либо нижнюю грань h* и использовать ее в качестве h в А*-алгоритме - оптимальность решения будет гарантирована.
Существует тривиальная нижняя грань, а именно:
h( n) = 0, для всех вершин n пространства состояний.
И при таком значении h допустимость гарантирована. Однако такая оценка не имеет никакой эвристической силы и ничем не помогает поиску. А*-алгоритм при h=0 ведет себя аналогично поиску в ширину. Он, действительно, превращается в поиск в ширину, если, кроме того, положить с(n, n' )=1 для всех дуг (n, n') пространства состояний. Отсутствие эвристической силы оценки приводит к большой комбинаторной сложности алгоритма. Поэтому хотелось бы иметь такую оценку h, которая была бы нижней гранью h* (чтобы обеспечить допустимость) и, кроме того, была бы как можно ближе к h* (чтобы обеспечить эффективность). В идеальном случае, если бы нам была известна сама точная оценка h*, мы бы ее и использовали: А*-алгоритм, пользующийся h*, находит оптимальное решение сразу, без единого возврата.
Процедуры для головоломки
Рисунок 12. 6. Процедуры для головоломки "игра в восемь",
предназначенные для использования программой поиска
с предпочтением Рисунок 12.3.
Существуют три отношения, отражающих специфику конкретной задачи:
после( Верш, Верш1, Ст)
Это отношение истинно, когда в пространстве состояний существует дуга стоимостью Ст между вершинами Верш и Верш1.
цель( Верш)
Это отношение истинно, если Верш - целевая вершина.
h( Верш, Н)
Здесь Н - эвристическая оценка стоимости самого дешевого пути из вершины Верш в целевую вершину.
В данном и следующих разделах мы определим эти отношения для двух примеров предметных областей: для головоломки "игра в восемь" (описанной в разделе 11.1) и планирования прохождения задач в многопроцессорной системе.
Отношения для "игры в восемь" показаны на Рисунок 12.6. Вершина пространства состояний - это некоторая конфигурация из фишек на игровой доске. В программе она задается списком текущих положений фишек. Каждое положение определяется парой координат X/Y. Элементы списка располагаются в следующем порядке:
(1) текущее положение пустой клетки,
(2) текущее положение фишки 1,
(3) текущее положение фишки 2,
...
Целевая ситуация (см. Рисунок 11.3) определяется при помощи предложения
цель( [2/2, 1/3, 2/3, 3/3, 3/2, 3/1, 2/1, 1/1, 1/2] ).
Имеется вспомогательное отношение
расст( K1, K2, Р)
Р - это "манхеттеновское расстояние" между клетками Kl и K2, равное сумме двух расстояний между Kl и K2: расстояния по горизонтали и расстояния по вертикали.
Три стартовых позиции
Рисунок 12. 7. Три стартовых позиции для "игры в восемь": (а) решение требует
4 шага; (b) решение требует 5 шагов; (с) решение требует 18 шагов.

Наша задача - минимизировать длину решения, поэтому мы положим стоимости всех дуг пространства состояний равными 1. В программе Рисунок 12. 6. даны также определения трех начальных позиций (см. Рисунок 12.7).
Эвристическая функция h, запрограммирована как отношение
h( Поз, Н)
Поз - позиция на доске; Н вычисляется как комбинация из двух оценок:
(1) сумрасст - "суммарное расстояние" восьми фишек, находящихся в позиции Поз, от их положений в целевой позиции. Например, для начальной позиции, показанной на Рисунок 12.7(а), сумрасст = 4.
(2) упоряд - степень упорядоченности фишек в текущей позиции по отношению к тому порядку, в котором они должны находиться в целевой позиции. Величина упоряд вычисляется как сумма очков, приписываемых фишкам, согласно следующим правилам: фишка в центральной позиции - 1 очко; фишка не в центральной позиции, и непосредственно за ней следует (по часовой стрелке) та фишка, какая и должна за ней следовать в целевой позиции - 0 очков. то же самое, но за фишкой следует "не та" фишка - 2 очка.
Например, для начальной позиции Рисунок 12.7(а),
упоряд = 6.
Эвристическая оценка Н вычисляется как сумма
Н = сумрасст + 3 * упоряд
Эта эвристическая функция хорошо работает в том смысле, что она весьма эффективно направляет поиск к цели. Например, при решении головоломок Рисунок 12.7(а) и (b) первое решение обнаруживается без единого отклонения от кратчайшего решающего пути. Другими словами, кратчайшие решения обнаруживаются сразу, без возвратов. Даже трудная головоломка Рисунок 12.7 (с) решается почти без возвратов. Но данная эвристическая функция страдает тем недостатком, что она не является допустимой: нет гарантии, что более короткие пути обнаруживаются раньше более длинных. Дело в том, что для функции h условие h <= h* выполнено не для всех вершин пространства состояний. Например, для начальной позиции Рисунок 12.7 (а)
h = 4 + 3 * 6 = 22, h* = 4
С другой стороны, оценка "суммарное расстояние" допустима: для всех позиций
сумрасст <= h*
Доказать это неравенство можно при помощи следующего рассуждения: если мы ослабим условия задачи и разрешим фишкам взбираться друг на друга, то каждая фишка сможет добраться до своего целевого положения по траектории, длина которой в точности равна манхеттеновскому расстоянию между ее начальным и целевым положениями. Таким образом, длина оптимального решения упрощенной задачи будет в точности равна сумрасст. Однако в исходном варианте задачи фишки взаимодействуют друг с другом и мешают друг другу, так что им уже трудно идти по своим кратчайшим траекториям. В результате длина оптимального решения окажется больше либо равной сумрасст.
Планирование прохождения
Рисунок 12. 8. Планирование прохождения задач в многопроцессорной системе для 7 задач и 3 процессоров. Вверху показано предшествование задач и величины продолжительности их решения. Например, задача t5 требует 20 квантов времени, причем ее выполнение может начаться только после того, как будет завершено решение трех других задач t1, t2 и t3. Показано два корректных плана: оптимальный план с временем окончания 24 и субоптимальный - с временем окончания 33. В данной задаче любой оптимальный план должен содержать время простоя.
Coffman/ Denning, Operating Systems Theory, © 1973, p.86. Приведено с разрешения Prentice-Hall, Englewood Cliffs, New Jersey.

одну за другой, пока все задачи не будут исчерпаны. Как правило, на каждом шагу мы будем иметь несколько различных возможностей, поскольку окажется, что одновременно несколько задач-кандидатов ждут своего выполнения. Таким образом, для составления плана потребуется перебор. Мы можем сформулировать задачу планирования в терминах пространства состояний следующим образом: состояния - это частично составленные планы; преемник частичного плана получается включением в план еще одной задачи; другая возможность - оставить процессор, только что закончивший свою задачу, в состоянии простоя; стартовая вершина - пустой план; любой план, содержащий все задачи, - целевое состояние; стоимость решения (подлежащая минимизации) -время окончания целевого плана; стоимость перехода от одного частичного плана к другому равна К2 - К1 где К1, К2 - времена окончания этих планов.
Этот грубый сценарий требует некоторых уточнений. Во-первых, мы решим заполнять план в порядке возрастания времен, так что задачи будут включаться в него слева направо. Кроме того, при добавлении каждой задачи следует проверять, выполнены ли ограничения, связанные с отношениями предшествования. Далее, не имеет смысла оставлять процессор бездействующим на неопределенное время, если имеются задачи, ждущие своего запуска. Поэтому мы разрешим процессору простаивать только до того момента, когда какой-нибудь другой процессор завершит выполнение своей задачи. В этот момент мы еще раз вернемся к свободному процессору с тем, чтобы рассмотреть возможность приписывания ему какой-нибудь задачи.
Теперь нам необходимо принять решение относительно представления проблемных ситуаций, т.е. частичных планов. Нам понадобится следующая информация:
(1) список ждущих задач вместе с их временами выполнения;
(2) текущая загрузка процессоров задачами.
Добавим также для удобства программирования
(3) время окончания (частичного) плана, т.е. самое последнее время окончания задачи среди всех задач, приписанных процессорам.
Список ждущих задач вместе с временами их выполнения будем представлять в программе при помощи списка вида
[ Задача1/Т1, Задача2/Т2, ... ]
Текущую загрузку процессоров будем представлять как список решаемых задач, т. е. список пар вида
[ Задача/ВремяОкончания ]
В списке m таких пар, по одной на каждый процессор. Новая задача будет добавляться к плану в момент, когда закончится первая задача из этого списка. В связи с этим мы должны постоянно поддерживать упорядоченность списка загрузки по возрастанию времен окончания. Эти три компоненты частичного плана (ждущие задачи, текущая загрузка и время окончания плана) будут объединены в одно выражение вида
Ждущие * Активные * ВремяОкончания
Кроме этой информации у нас есть ограничения, налагаемые отношениями предшествования, которые в программе будут выражены в форме отношения
предш( ЗадачаX, ЗадачаY)
Рассмотрим теперь эвристическую оценку. Мы будем использовать довольно примитивную эвристическую функцию, которая не сможет обеспечить высокую эффективность управления алгоритмом поиска. Эта функция допустима, так что получение оптимального плана будет гарантировано. Однако следует заметить, что для решения более серьезных задач планирования потребуется более мощная эвристика.
Нашей эвристической функцией будет оптимистическая оценка времени окончания частичного плана с учетом всех ждущих задач. Оптимистическая оценка будет вычисляться в предположении, что два из ограничений, налагаемых на действительно корректный план, ослаблены:
(1) не учитываются отношения предшествования;
(2) делается (не реальное) допущение, что возможно распределенное выполнение задачи одновременно на нескольких процессорах, причем сумма времен выполнения задачи на процессорах равна исходному времени выполнения этой задачи на одном процессоре.
Пусть времена выполнения ждущих задач равны Т1, Т2, ..., а времена окончания задач, выполняемых на процессорах - К1, К2, ... . Тогда оптимистическая оценка времени ОбщКон окончания всех активных к настоящему моменту, а также всех ждущих задач имеет вид:
Отношения для задачи
Рисунок 12. 9. Отношения для задачи планирования. Даны также
определения отношений для конкретной задачи планирования с
Рисунок 12.8: граф предшествования и исходный (пустой) план в
качестве стартовой вершины.
для задачи поиска маршрута Рисунок
Упражнение
12. 1. Определите отношения после, цель и h для задачи поиска маршрута Рисунок 12.2. Посмотрите, как наш алгоритм поиска с предпочтением будет вести себя при решении этой задачи.
Упражнение
12. 2. Введите в программу поиска с предпочтением, приведенную на Рисунок 12.3, подсчет числа вершин, порожденных в процессе поиска. Один из простых способов это сделать - хранить текущее число вершин в виде факта, устанавливаемого при помощи assert. Всегда, когда порождаются новые вершины, уточнять это значение при помощи retract и assert. Проведите эксперименты с различными эвристическими функциями задачи "игра в восемь" с целью оценить их эвристическую силу. Используйте для этого вычисленное количество порожденных вершин.
Представление задач в виде И / ИЛИграфов
13. 1. Представление задач в виде И / ИЛИ-графов
В главах 11 и 12, говоря о решении задач, мы сконцентрировали свое внимание на пространстве состояний как средстве представления этих задач. В соответствии с таким подходом решение задач сводилось к поиску пути в графе пространства состояний. Однако для некоторых категорий задач представление в форме И / ИЛИ-графа является более естественным. Такое представление основано на разбиении задач на подзадачи. Разбиение на подзадачи дает преимущества в том случае, когда подзадачи взаимно независимы, а, следовательно, и решать их можно независимо друг от друга.
Проиллюстрируем это на примере. Рассмотрим задачу отыскания на карте дорог маршрута между двумя заданными городами, как показано на Рисунок 13.1. Не будем пока учитывать длину путей. Разумеется, эту задачу можно сформулировать как поиск пути в про-
И / ИЛИпредставление задачи поиска маршрута
13. 2. 1. И / ИЛИ-представление задачи поиска маршрута
Для задачи отыскания кратчайшего маршрута (Рисунок 13.1) И / ИЛИ-граф вместе с функцией стоимости можно определить следующим образом:
ИЛИ-вершины представляются в форме X-Z, что означает: найти кратчайший путь из X в Z.
И-вершины имеют вид
X-Z через Y
что означает: найти кратчайший путь из X в Z, проходящий через Y.
Вершина X-Z является целевой вершиной (примитивной задачей), если на карте существует непосредственная связь между X и Z.
Стоимость каждой целевой вершины X-Z равна расстоянию, которое необходимо преодолеть по дороге, соединяющей X с Z.
Стоимость всех остальных (нетерминальных) вершин равна 0.
Стоимость решающего графа равна сумме стоимостей всех его вершин (в нашем случае это просто сумма стоимостей всех терминальных вершин). В задаче Рисунок 13.1 стартовая вершина - это а-z. На Рисунок
Задача о ханойской башне
13. 2. 2. Задача о ханойской башне
Задача о ханойской башне (Рисунок 13.6) - это еще один классический пример эффективного применения метода разбиения задачи на подзадачи и построения И / ИЛИ-графа. Для простоты мы рассмотрим упрощенную версию этой задачи, когда в ней участвует только три диска:
Имеется три колышка 1, 2 и 3 и три диска а, b и с (а - наименьший из них, а с - наибольший). Первоначально все диски находятся на колышке 1. Задача состоит в том, чтобы переложить все диски на колышек 3. На каждом шагу можно перекладывать только один диск, причем никогда нельзя помещать больший диск на меньший.
Эту задачу можно рассматривать как задачу достижения следующих трех целей:
(1) Диск а
- на колышек 3.
(2) Диск b
- на колышек 3.
(3) Диск с
- на колышек 3.
Беда в том, что эти цели не независимы. Например, можно сразу переложить диск а на колышек 3, и первая цель будет достигнута. Но тогда две другие цели станут недостижимыми (если только мы не отменим первое наше действие). К счастью, существует такой удобный порядок достижения этих целей, из которого можно легко вывести искомое решение.
Формулировка игровых задач в терминах И / ИЛИграфов
13. 2. 3. Формулировка игровых задач в терминах И / ИЛИ-графов
Такие игры, как шахматы или шашки, естественно рассматривать как задачи, представленные И / ИЛИ-графами. Игры такого рода называются играми двух лиц с полной информацией. Будем считать, что существует только два возможных исхода игры: ВЫИГРЫШ и ПРОИГРЫШ. (Об играх с тремя возможными исходами -ВЫИГРЫШ, ПРОИГРЫШ и НИЧЬЯ, можно также говорить, что они имеют только два исхода: ВЫИГРЫШ и НЕВЫИГРЫШ). Так как участники игры ходят по очереди, мы имеем два вида позиций, в зависимости от того, чей ход. Давайте условимся называть участников игры "игрок" и "противник", тогда мы будем иметь следующие два вида позиций: позиция с ходом игрока ("позиция игрока") и позиция с ходом противника ("позиция противника"). Допустим также, что начальная позиция Р - это позиция игрока. Каждый вариант хода игрока в этой позиции приводит к одной из позиций противника Q1, Q2, Q3, ... (см. Рисунок 13.7). Далее каждый вариант хода противника в позиции Q1 приводит к одной из позиций игрока R11, R12, ... . В И / ИЛИ-дереве, показанном на Рисунок 13.7, вершины соответствуют позициям, а дуги - возможным ходам. Уровни позиций игрока чередуются в дереве с уровнями позиций противника. Для того, чтобы выиграть в позиции Р, нужно найти ход, переводящий Р в выигранную позицию Qi. (при некотором i). Таким образом, игрок выигрывает в позиции Р, если он выигрывает в Q1, или Q2, или Q3, или ... . Следовательно, Р - это ИЛИ-вершина. Для любого i позиция Qi - это позиция противника, поэтому если в этой позиции выигрывает игрок, то он выигрывает и после каждого вариан-
Примеры И/ИЛИпредставления задач
13. 2. Примеры И/ИЛИ-представления задач
Базовые процедуры поиска в И / ИЛИграфах
13. 3. Базовые процедуры поиска в И / ИЛИ-графах
В этом разделе нас будет интересовать какое-нибудь решение задачи независимо от его стоимости, поэтому проигнорируем пока стоимости связей или вершин И / ИЛИ-графа. Простейший способ организовать поиск в И / ИЛИ-графах средствами Пролога - это использовать переборный механизм, заложенный в самой пролог-системе. Оказывается, что это очень просто сделать, потому что процедурный смысл Пролога это и есть не что иное, как поиск в И / ИЛИ-графе. Например, И / ИЛИ-граф Рисунок 13.4 (без учета стоимостей дуг) можно описать при помощи следующих предложений:
а :- b.
% а - ИЛИ-вершина с двумя преемниками
а :- с.
% b и с
b :- d, е.
% b - И-вершина с двумя преемниками d и е
с :- h.
с :- f, g.
f :- h, i.
d. g. h.
% d, g и h - целевые вершины
Для того, чтобы узнать, имеет ли эта задача решение, нужно просто спросить:
?- а.
Получив этот вопрос, пролог-система произведет поиск в глубину в дереве Рисунок 13.4 и после того, как пройдет через все вершины подграфа, соответствующего решающему дереву Рисунок 13.4(b), ответит "да".
Преимущество такого метода программирования И / ИЛИ-поиска состоит в его простоте. Но есть и недостатки: Мы получаем ответ "да" или "нет", но не получаем решающее дерево. Можно было бы восстановить решающее дерево при помощи трассировки программы, но такой способ неудобен, да его и недостаточно, если мы хотим иметь возможность явно обратиться к решающему дереву как к объекту программы. В эту программу трудно вносить добавления, связанные с обработкой стоимостей. Если наш И / ИЛИ-граф - это граф общего вида, содержащий циклы, то пролог-система, следуя стратегии в глубину, может войти в бесконечный рекурсивный цикл.
Попробуем постепенно исправить эти недостатки. Сначала определим нашу собственную процедуру поиска в глубину для И / ИЛИ-графов.
Прежде всего мы должны изменить представление И / ИЛИ-графов. С этой целью введём бинарное отношение, изображаемое инфиксным оператором '--->'. Например, вершина а с двумя ИЛИ-преемниками будет представлена предложением
а ---> или : [b, с].
Оба символа '--->' и ':' - инфиксные операторы, которые можно определить как
:- ор( 600, xfx, --->).
:- ор( 500, xfx, :).
Весь И / ИЛИ-граф Рисунок 13.4 теперь можно задать при помощи множества предложений
а ---> или : [b, с].
b ---> и : [d, e].
с ---> и : [f, g].
е ---> или : [h].
f ---> или : [h, i].
цель( d). цель( g). цель( h).
Процедуру поиска в глубину в И / ИЛИ-графах можно построить, базируясь на следующих принципах:
Для того, чтобы решить задачу вершины В, необходимо придерживаться приведенных ниже правил:
(1) Если В - целевая вершина, то задача решается тривиальным образом.
(2) Если вершина В имеет ИЛИ-преемников, то нужно решить одну из соответствующих задач-преемников (пробовать решать их одну за другой, пока не будет найдена задача, имеющая решение).
(3) Если вершина В имеет И-преемников, то нужно решить все соответствующие задачи (пробовать решать их одну за другой, пока они не будут решены все).
Если применение этих правил не приводит к решению, считать, что задача не может быть решена.
Соответствующая программа выглядит так:
решить( Верш) :-
цель( Верш).
решить( Верш) :-
Верш ---> или : Вершины,
% Верш - ИЛИ-вершина
принадлежит( Верш1, Вершины),
% Выбор преемника Верш1 вершины Верш
решить( Bepш1).
решить( Верш) :-
Верш ---> и : Вершины,
% Верш - И-вершина
решитьвсе( Вершины).
% Решить все задачи-преемники
решитьвсе( [ ]).
решитьвсе( [Верш | Вершины]) :-
решить( Верш),
решитьвсе( Вершины).
Здесь принадлежит - обычное отношение принадлежности к списку.
Эта программа все еще имеет недостатки: она не порождает решающее дерево, и она может зацикливаться, если И / ИЛИ-граф имеет соответствующую структуру (циклы).
Программу нетрудно изменить с тем, чтобы она порождала решающее дерево. Необходимо так подправить отношение решить, чтобы оно имело два аргумента:
решить( Верш, РешДер).
Решающее дерево представим следующим образом. Мы имеем три случая:
(1) Если Верш - целевая вершина, то соответствующее решающее дерево и есть сама эта вершина.
(2) Если Верш - ИЛИ-вершина, то решающее дерево имеет вид
Верш ---> Поддерево
где Поддерево - это решающее дерево для одного из преемников вершины Верш.
(3) Если Верш - И-вершина, то решающее дерево имеет вид
Верш ---> и : Поддеревья
где Поддеревья - список решающих деревьев для всех преемников вершины Верш.
line();% Поиск в глубину для И / ИЛИ-графов
% Процедура решить( Верш, РешДер) находит решающее дерево для
% некоторой вершины в И / ИЛИ-графе
решить( Верш, Верш) :-
% Решающее дерево для целевой
цель( Верш).
% вершины - это сама вершина
решить( Верш, Верш ---> Дер) :-
Верш ---> или : Вершины, % Верш - ИЛИ-вершина
принадлежит( Верш1, Вершины),
% Выбор преемника Верш1 вершины Верш
решить( Bepш1, Дер).
решить( Верш, Верш ---> и : Деревья) :-
Верш ---> и : Вершины,
% Верш - И-вершина
решитьвсе( Вершины, Деревья).
% Решить все задачи-преемники
решитьвсе( [ ], [ ]).
решитьвсе( [Верш | Вершины], [Дер | Деревья]) :-
решить( Верш, Дер),
решитьвсе( Вершины, Деревья).
отобр( Дер) :-
% Отобразить решающее дерево
отобр( Дер, 0), !.
% с отступом 0
отобр( Верш ---> Дер, Н) :-
% Отобразить решающее дерево с отступом Н
write( Верш), write( '--->'),
H1 is H + 7,
отобр( Дер, H1), !.
отобр( и : [Д], Н) :-
% Отобразить И-список решающих деревьев
отобр( Д, Н).
отобр( и : [Д | ДД], Н) :-
% Отобразить И-список решающих деревьев
отобр( Д, Н),
tab( H),
отобр( и : ДД, Н), !.
отобр( Верш, Н) :-
write( Верш), nl.
Эвристические оценки и алгоритм поиска
13. 4. 1. Эвристические оценки и алгоритм поиска
Базовые процедуры поиска предыдущего раздела производят систематический и полный просмотр И / ИЛИ-дерева, не руководствуясь при этом какими-либо эвристиками. Для сложных задач подобные процедуры весьма не эффективны из-за большой комбинаторной сложности пространства поиска. В связи с этим возникает необходимость в эвристическом управлении поиском, направленном на уменьшение комбинаторной сложности за счет исключения бесполезных альтернатив. Управление эвристиками, излагаемое в настоящем разделе, будет основано на численных эвристических оценках "трудности" задач, входящих в состав И / ИЛИ-графа. Программу, которую мы составим, можно рассматривать как обобщение программы поиска с предпочтением в пространстве состояний гл. 12.
Начнем с того, что сформулируем критерий оптимальности, основанный на стоимостях дуг И / ИЛИ-графа. Во-первых, мы расширим наше представление И / ИЛИ-графов, дополнив его стоимостями дуг. Например, И / ИЛИ-граф Рисунок 13.4 можно представить следующими предложениями:
а ---> или : [b/1, с/3].
b ---> и : [d/1, е/1].
с ---> и : [f/2, g/1].
e ---> или : [h/6].
f ---> или : [h/2, i/3].
цель( d). цель( g). цель( h).
Стоимость решающего дерева мы определим как сумму стоимостей его дуг. Цель оптимизации - найти решающее дерево минимальной стоимости. Как и раньше, иллюстрацией служит Рисунок 13.4.
Будет полезным определить стоимость вершины И / ИЛИ-графа как стоимость оптимального решающего дерева для этой вершины. Стоимость вершины, определенная таким образом, соответствует "трудности" соответствующей задачи.
Мы будем предполагать, что стоимости вершин И / ИЛИ-графа можно оценить (не зная соответствующих решающих деревьев) при помощи эвристической функции h. Эти оценки будут использоваться для управления поиском. Наша программа поиска начнет свою работу со стартовой вершины и, распространяя поиск из уже просмотренных вершин на их преемников, будет постепенно наращивать дерево поиска. Этот процесс будет строить дерево даже в том случае, когда сам И / ИЛИ-граф не является деревом; при этом граф будет разворачиваться в дерево за счет дублирования своих отдельных частей.
Для продолжения поиска будет всегда выбираться "наиболее перспективное" решающее дерево-кандидат. Каким же образом используется функция h для оценки степени перспективности решающего дерева-кандидата или, точнее, вершины-кандидата - корня этого дерева?
Программа поиска
13. 4. 2. Программа поиска
Программа, в которой реализованы идеи предыдущего раздела, показана на Рисунок 13.12. Прежде, чем мы перейдем к объяснению отдельных деталей этой программы, давайте рассмотрим тот способ представления дерева поиска, который в ней используется.
Существует несколько случаев, как показано на Рисунок 13.11. Различные формы представления поискового дерева возникают как комбинации следующих возможных вариантов, относящихся к размеру дерева и к его "решающему статусу".
Размер:
(1) дерево состоит из одной вершины (листа)
или
(2) оно имеет корень и (непустые) поддеревья.
Решающий статус:
(1) обнаружено, что дерево соответствует
решению задачи( т. е. является решающим
деревом) или
(2) оно все еще решающее дерево-кандидат.
Основной функтор, используемый для представления дерева, указывает, какая из комбинаций этих воз-
line();Пример отношений определяющих конкретную задачу поиск маршрута
13. 4. 3. Пример отношений, определяющих конкретную задачу: поиск маршрута
Давайте теперь сформулируем задачу нахождения маршрута как задачу поиска в И / ИЛИ-графе, причем сделаем это таким образом, чтобы наша формулировка могла бы быть непосредственно использована процедурой и_или Рисунок 13.12. Мы условимся, что карта дорог будет представлена при помощи отношения
связь( Гор1, Гор2, Р)
означающего, что между городами Гор1 и Гор2 существует непосредственная связь, а соответствующее расстояние равно Р. Далее, мы допустим, что существует отношение
клпункт( Гор1-Гор2, Гор3)
имеющее следующий смысл: для того, чтобы найти маршрут из Гор1 в Гор2, следует рассмотреть пути, проходящие через Гор3 ( Гор3 - это "ключевой пункт" между Гор1 и Гор2). Например, на карте Рисунок 13.1 f и g - это ключевые пункты между а и z:
клпункт( a-z, f). клпункт( a-z, g).
Мы реализуем следующий принцип построения маршрута:
Для того, чтобы найти маршрут между городами X и Z, необходимо:
(1) если между X и Z имеются ключевые пункты Y1, Y2, ..., то найти один из путей:
путь из X в Z через Y1, или
путь из X в Z через Y2, или
...
(2) если между X и Z нет ключевых пунктов, то найти такой соседний с X город Y, что существует маршрут из Y в Z.
Таким образом, мы имеем два вида задач, которые мы будем представлять как
(1) X-Z найти маршрут из X в Z
(2) X-Z через Y найти маршрут из X в Z, проходящий через Y
Здесь 'через' - это инфиксный оператор более высокого приоритета, чем '-', и более низкого, чем '--->'. Теперь можно определить соответствующий И / ИЛИ-граф явным образом при помощи следующего фрагмента программы:
:- ор( 560, xfx, через)
% Правила задачи X-Z, когда между X и Z
% имеются ключевые пункты,
% стоимости всех дуг равны 0
X-Z ---> или : СписокЗадач
:- bagof( ( X-Z через Y)/0, клпункт( X-Z, Y),
СписокЗадач), !.
% Правила для задачи X-Z без ключевых пунктов
X-Z ---> или : СписокЗадач
:- bagof( ( Y-Z)/P, связь( X, Y, Р), СписокЗадач).
% Сведение задачи типа ''через" к подзадачам,
% связанным отношением И
X-Z через Y---> и : [( X-Y)/0, ( Y-Z)/0].
цель( Х-Х) % Тривиальная задача: попасть из X в X
Функцию h можно определить, например, как расстояние, которое нужно преодолеть при воздушном сообщении между городами.
Поиск с предпочтением в И / ИЛИграфах
13. 4. Поиск с предпочтением в И / ИЛИ-графах
Литература
Литература
И / ИЛИ-графы и связанные с ними алгоритмы поиска являются частью классических механизмов искусственного интеллекта для решения задач и реализации машинных игр. Ранним примером прикладной задачи, использующей эти методы, может служить программа символического интегрирования (Slagle 1963). И / ИЛИ-поиск используется в самой пролог-системе. Общее описание И / ИЛИ-графов и алгоритма можно найти в учебниках по искусственному интеллекту (Nilsson 1971; Nilsson 1980). Наша программа поиска с предпочтением - это один из вариантов алгоритма, известного под названием АО* . Формальные свойства АО* -алгоритма (включая его допустимость) изучались несколькими авторами. Подробный обзор полученных результатов можно найти в книге Pearl (1984).
Nilsson N.J. (1971). Problem-Solving Methods in Artificial Intelligence. McGraw-Hill.
Nilsson N.J. (1980). Principles of Artificial Intelligence. Tioga; also Springer-Verlag.
Pearl J. (1984). Heuristics: Intelligent Search Strategies for Computer Problem Solving. Addison-Wesley.
Slagle J.R. (1963). A heuristic program that solves symbolic integration problems in freshman calculus. In: Computers and Thought (E. Feigenbaum, J. Feldman, eds.). McGraw-Hill.
это формальный аппарат для представления
И / ИЛИ-граф - это формальный аппарат для представления задач. Такое представление является наиболее естественным и удобным для задач, которые разбиваются на независимые подзадачи. Примером могут служить игры. Вершины И / ИЛИ-графа бывают двух типов: И- вершины и ИЛИ-вершины. Конкретная задача определяется стартовой вершиной и целевым условием. Решение задачи представляется решающим деревом. Для моделирования оптимизационных задач в И / ИЛИ-граф можно ввести стоимости дуг и вершин. Процесс решения задачи, представленной И / ИЛИ-графом, включает в себя поиск в графе. Стратегия поиска в глубину предусматривает систематический просмотр графа и легко программируется. Однако эта стратегия может привести к неэффективности из-за комбинаторного взрыва. Для оценки трудности задач можно применить эвристики, а для управления поиском - принцип эвристического поиска с предпочтением. Эта стратегия более трудна в реализации. В данной главе были разработаны прологовские программы для поиска в глубину и поиска с предпочтением в И / ИЛИ-графах. Были введены следующие понятия:
И / ИЛИ-графы
И-дуги, ИЛИ-дуги
И-вершины, ИЛИ-вершины
решающий путь, решающее дерево
стоимость дуг и вершин
эвристические оценки в И / ИЛИ-графах
"возвращенные" оценки
поиск в глубину в И / ИЛИ-графах
поиск с предпочтением в И / ИЛИ-графах
Поиск маршрута из
Рисунок 13. 1. Поиск маршрута из а в z на карте дорог. Через реку
можно переправиться в городах f и g. И / ИЛИ-представление этой
задачи показано на Рисунок 13.2.

странстве состояний. Соответствующее пространство состояний выглядело бы в точности, как карта Рисунок 13.1: вершины соответствуют городам, дуги - непосредственным связям между городами. Тем не менее давайте построим другое представление, основанное на естественном разбиении этой задачи на подзадачи.
На карте Рисунок 13.1 мы видим также реку. Допустим, что переправиться через нее можно только по двум мостам: один расположен в городе f, другой - в городе g. Очевидно, что искомый маршрут обязательно должен проходить через один из мостов, а значит, он должен пройти либо через f, либо через g. Таким образом, мы имеем две главных альтернативы:
Для того, чтобы найти путь из а в z,
необходимо найти одно из двух:
(1) путь из а в z, проходящий через f, или
(2) путь из а в z, проходящий через g.
И / ИЛИпредставление
Рисунок 13. 2. И / ИЛИ-представление задачи поиска маршрута Рисунок 13.1.
Вершины соответствуют задачам или подзадачам, полукруглые дуги
означают, что все (точнее, обе) подзадачи должны быть решены.

Теперь каждую из этих двух альтернативных задач можно, в свою очередь, разбить следующим образом:
(1) Для того, чтобы найти путь из a в z через
f, необходимо:
1.1 найти путь из а и f и
1.2 найти путь из f в z.
(2) Для того, чтобы найти путь из a в z через
g, необходимо:
2.1 найти путь из а в g и
2.2 найти путь из g в z.
а) Решить Р это
Рисунок 13. 3. (а) Решить Р - это значит решить Р1 или Р2 или ...
(б) Решить Q - это значит решить все: Q1 и Q2 и ... .

Итак, мы имеем две главных альтернативы для решения исходной задачи: (1) путь через f или (2) путь через g. Далее, каждую из этих альтернатив можно разбить на подзадачи (1.1 и 1.2 или 2.1 и 2.2 соответственно). Здесь важно то обстоятельство, что каждую из подзадач в обоих альтернативах можно решать независимо от другой. Полученное разбиение исходной задачи можно изобразить в форме И / ИЛИ-графа (Рисунок 13.2). Обратите внимание на полукруглые дуги, которые указывают на отношение И между соответствующими подзадачами. Граф, показанный на Рисунок 13.2 - это всего лишь верхняя часть всего И / ИЛИ-дерева. Дальнейшее разбиение подзадач можно было бы строить на основе введения дополнительных промежуточных городов.
Какие вершины И / ИЛИ-графа являются целевыми? Целевые вершины - это тривиальные, или "примитивные" задачи. В нашем примере такой подзадачей можно было бы считать подзадачу "найти путь из а в с", поскольку между городами а и с на карте имеется непосредственная связь.
Рассматривая наш пример, мы ввели ряд важных понятий. И / ИЛИ-граф - это направленный граф, вершины которого соответствуют задачам, а дуги - отношениям между задачами. Между дугами также существуют свои отношения. Это отношения И и ИЛИ, в зависимости от того, должны ли мы решить только одну из задач-преемников или же несколко из них (см. Рисунок 13.3). В принципе из вершины могут выходить дуги, находящиеся в отношении И вместе с дугами, находящимися в отношении ИЛИ. Тем не менее, мы будем предполагать, что каждая вершина имеет либо только И-преемников, либо только ИЛИ-преемников; дело в том, что в такую форму можно преобразовать любой И / ИЛИ граф, вводя в него при необходимости вспомогательные ИЛИ-вершины. Вершину, из которой выходят только И-дуги, называют И-вершиной; вершину, из которой выходят только ИЛИ-дуги, - ИЛИ-вершиной.
Когда задача представлялась в форме пространства состояний, ее решением был путь в этом пространстве. Что является решением в случае И / ИЛИ-представления? Решение должно, конечно, включать в себя все подзадачи И-вершины. Следовательно, это уже не путь, а дерево. Такое решающее дерево Т определяется следующим образом: исходная задача Р - это корень дерева Т; если Р является ИЛИ-вершиной, то в Т содержится только один из ее преемников (из И / ИЛИ-графа) вместе со своим собственным решающим деревом; если Р - это И-вершина, то все ее преемники (из И / ИЛИ-графа) вместе со своими решающими деревьями содержатся в Т.
а) Пример И / ИЛИграфа
Рисунок 13. 4. (а) Пример И / ИЛИ-графа: d, g и h - целевые вершины;
a - исходная задача. (b) и (с) Два решающих дерева, стоимости
которых равны 9 и 8 соответственно. Здесь стоимость решающего
дерева определена как сумма стоимостей всех входящих в него дуг.

Иллюстрацией к этому определению может служить Рисунок 13.4. Используя стоимости, мы можем формулировать критерии оптимальности решения. Например, можно определить стоимость решающего графа как сумму стоимостей всех входящих в него дуг. Тогда, поскольку обычно мы заинтересованы в минимизации стоимости, мы отдадим предпочтение решающему графу, изображенному на Рисунок 13.4(с).
Однако мы не обязательно должны измерять степень оптимальности решения, базируясь на стоимостях дуг. Иногда более естественным окажется приписывать стоимость не дугам, а вершинам, или же и тем, и другим одновременно.
Подведем итоги:
И / ИЛИ-представление основано на философии сведения задач к подзадачам.
Вершины И / ИЛИ-графа соответствуют задачам; связи между вершинами - отношениям между задачами.
Вершина, из которой выходят ИЛИ-связи, называется ИЛИ-вершиной. Для того, чтобы решить соответствующую задачу, нужно решить одну из ее задач-преемников.
Вершина, из которой выходят И-связи, называ ется И-вершиной. Для того, чтобы решить соответствующую задачу, нужно решить все ее задачи-преемники.
При заданном И / ИЛИ-графе конкретная задача специфицируется заданием
стартовой вершины и
целевого условия для распознавания
целевых вершин.
Целевые вершины (или "терминальные вершины") соответствуют тривиальным (или "примитивным") задачам.
Решение представляется в виде решающего графа - подграфа всего И / ИЛИ-графа.
Представление задач в форме пространства состояний можно рассматривать как специальный частный случай И / ИЛИ-представления, когда все вершины И / ИЛИ-графа являются ИЛИ-вершинами.
И / ИЛИ-представление имеет преимущество в том случае, когда вершинами, находящимися в отношении И, представлены подзадачи, которые можно решать независимо друг от друга. Критерий независимости можно несколько ослабить, а именно потребовать, чтобы существовал такой порядок решения И-задач, при котором решение более "ранних" подзадач не разрушалось бы при решении более "поздних" под задач.
Дугам или вершинам, или и тем, и другим можно приписать стоимости с целью получить возможность сформулировать критерий оптимальности решения.
Решающее дерево минимальной
Рисунок 13. 5. Решающее дерево минимальной стоимости для задачи
поиска маршрута Рисунок 13.1, сформулированной в терминах И / ИЛИ-
графа.

13.5 показан решающий граф, имеющий стоимость 9. Это дерево соответствует пути [a, b, d, f, i, z], который можно построить, если пройти по всем листьям решающего дерева слева направо.
Задача о ханойской башне
Рисунок 13. 6. Задача о ханойской башне

Порядок этот можно установить при помощи следующего рассуждения: самая трудная цель - это цель 3 (диск с - на колышек 3), потому что на диск с наложено больше всего ограничений. В подобных ситуациях часто срабатывает хорошая идея: пытаться достичь первой самую трудную цель. Этот принцип основан на следующей логике: поскольку другие цели достигнуть легче (на них меньше ограничений), можно надеяться на то, что их достижение возможно без отмены действий на достижение самой трудной цели.
Применительно к нашей задаче это означает, что необходимо придерживаться следующей стратегии:
Первой достигнуть цель "диск с - на колышек 3",
а затем - все остальные.
Но первая цель не может быть достигнута сразу, так как в начальной ситуации диск с двигать нельзя. Следовательно, сначала мы должны подготовить этот ход, и наша стратегия принимает такой вид
(1) Обеспечить возможность перемещения диска с с 1 на 3.
(2) Переложить с с 1 на 3.
(3) Достигнуть остальные цели (а на 3 и b на 3).
Переложить c с 1 на 3 возможно только в том случае, если диск а и b оба надеты на колышек 2. Таким образом наша исходная задача перемещения а, b и с с 1 на 3 сводится к следующим трем подзадачам:
Для того, чтобы переложить a, b и с с 1 на 3, необходимо
(1) переложить а и b с 1 на 2, и
(2) переложить с с 1 на 3, и
(1) переложить а и b с 2 на 3.
Задача 2 тривиальна (она решается за один шаг). Остальные две подзадачи можно решать независимо от задачи 2, так как диски а и b можно двигать, не обращая внимание на положение диска с. Для решения задач 1 и 3 можно применить тот же самый принцип разбиения (на этот раз диск b будет самым "трудным"). В соответствии с этим принципом задача 1 сводится к трем тривиальным подзадачам:
Для того, чтобы переложить а и b с 1 на 2, необходимо:
(1) переложить а с 1 на 3, и
(2) переложить b с 1 на 2, и
(1) переложить а с 3 на 2.
Формулировка игровой
Рисунок 13. 7. Формулировка игровой задачи для игры двух лиц в
форме И / ИЛИ-дерева; участники игры: "игрок" и "противник".

та хода противника. Другими словами, игрок выигрывает в Qi, если он выигрывает во всех позициях Ri1 и Ri2 и ... . Таким образом, все позиции противника - это И-вершины. Целевые вершины - это позиции, выигранные согласно правилам игры, например позиции, в которых король противника получает мат. Позициям проигранным соответствуют задачи, не имеющие решения. Для того, чтобы решить игровую задачу, мы должны построить решающее дерево, гарантирующее победу игрока независимо от ответов противника. Такое дерево задает полную стратегию достижения выигрыша: для каждого возможного продолжения, выбранного противником, в дереве стратегии есть ответный ход, приводящий к победе.
Поиск в глубину для
Рисунок 13. 8. Поиск в глубину для И / ИЛИ-графов. Эта программа может
зацикливаться. Процедура решить находит решающее дерево, а
процедура отобр показывает его пользователю. В процедуре отобр
предполагается, что на вывод вершины тратится только один символ.
Например, при поиске в И / ИЛИ-графе Рисунок 13.4 первое найденное решение задачи, соответствующей самой верхней вершине а, будет иметь следующее представление:
а ---> b ---> и : [d, c ---> h]
Три формы представления решающего дерева соответствуют трем предложениям отношения решить. Поэтому все, что нам нужно сделать для изменения нашей исходной программы решить, - это подправить каждое из этих трех предложений, просто добавив в каждое из них решающее дерево в качестве второго аргумента. Измененная программа показана на Рисунок 13.8. В нее также введена дополнительная процедура отобр для отображения решающих деревьев в текстовой форме. Например, решающее дерево Рисунок 13.4 будет отпечатано процедурой отобр в следующем виде:
а ---> b ---> d
е ---> h
Программа Рисунок 13.8 все еще сохраняет склонность к вхождению в бесконечные циклы. Один из простых способов избежать бесконечных циклов - это следить за текущей глубиной поиска и не давать программе заходить за пределы некоторого ограничения по глубине. Это можно сделать, введя в отношение решить еще один аргумент:
решить( Верш, РешДер, МаксГлуб)
Как и раньше, вершиной Верш представлена решаемая задача, а РешДер - это решение этой задачи, имеющее глубину, не превосходящую МаксГлуб. МаксГлуб -это допустимая глубина поиска в графе. Если МаксГлуб = 0, то двигаться дальше запрещено, если же МаксГлуб > 0, то поиск распространяется на преемников вершины Верш, причем для них устанавливается меньший предел по глубине, равный МаксГлуб -1. Это дополнение легко ввести в программу Рисунок 13.8. Например, второе предложение процедуры решить примет вид:
решить( Верш, Верш ---> Дер, МаксГлуб) :-
МаксГлуб > 0,
Верш ---> или : Вершины,
% Верш - ИЛИ-вершина
принадлежит ( Верш1, Вершины),
% Выбор преемника Верш1 вершины Верш
Глуб1 is МаксГлуб - 1,
% Новый предел по глубине
решить( Bepш1, Дер, Глуб1).
% Решить задачу-преемник с меньшим ограничением
Нашу процедуру поиска в глубину с ограничением можно также использовать для имитации поиска в ширину. Идея состоит в следующем: многократно повторять поиск в глубину каждый раз все с большим значением ограничения до тех пор, пока решение не будет найдено, То есть попробовать решить задачу с ограничением по глубине, равным 0, затем - с ограничением 1, затем - 2 и т.д. Получаем следующую программу:
имитация_в_ширину( Верш, РешДер) :-
проба_в_глубину( Верш, РешДер, 0).
% Проба поиска с возрастающим ограничением, начиная с 0
проба_в_глубину( Верш, РешДер, Глуб) :-
решить( Верш, РешДер, Глуб);
Глуб1 is Глуб + 1,
% Новый предел по глубине
проба_в_глубину( Верш, РешДер, Глуб1).
% Попытка с новым ограничением
Недостатком имитации поиска в ширину является то, что при каждом увеличении предела по глубине программа повторно просматривает верхнюю область пространства поиска.
Получение оценки Н трудности задач И / ИЛИграфа
Рисунок 13. 9. Получение оценки Н трудности задач И / ИЛИ-графа.
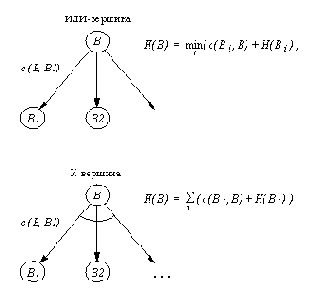
Обозначим через Н( В) оценку трудности вершины В. Для самой верхней вершины текущего дерева поиска H( В) просто совпадает с h( В). С другой стороны, для оценки внутренней вершины дерева поиска нам не обязательно использовать непосредственно значение h, поскольку у нас есть некоторая дополнительная информация об этой вершине: мы знаем ее преемников. Следовательно, как показано на Рисунок 13.9, мы можем приближенно оценить трудность внутренней ИЛИ-вершины как
H( B) = min ( c( B, Bi) + H( Bi) )
i
где с( В, В) - стоимость дуги, ведущей из В в Вi. Взятие минимума в этой формуле оправдано тем обстоятельством, что для того, чтобы решить задачу В, нам нужно решить только одну из ее задач-преемников. Трудность И-вершины В можно приближенно оценить так:
Трассировка процесса
Рисунок 13. 10. Трассировка процесса поиска с предпочтением в
И / ИЛИ-графе ( h = 0) при решении задачи Рисунок 13.4.

прекращается. В результате процесс поиска не успевает "осознать", что h - это тоже целевая вершина и что порождено решающее дерево. Вместо этого происходит переключение активности на конкурирующую альтернативу с. Поскольку в этот момент F( b) = 9, устанавливается верхняя граница для F( c), равная 9. Дерево-кандидат с корнем с наращивается (с учетом установленного ограничения) до тех пор, пока не возникает ситуация, показанная на снимке Е. Теперь процесс поиска обнаруживает, что найдено решающее дерево (включающее в себя целевые вершины h и g), на чем поиск заканчивается. Заметьте, что в качестве результата процесс поиска выдает наиболее дешевое из двух возможных решающих деревьев, а именно решающее дерево Рисунок 13.4(с).
Представление дерева поиска
Рисунок 13. 11. Представление дерева поиска.

можностей имеется в виду. Это может быть одна из следующих комбинаций:
лист решлист дер решдер
Далее, в представление дерева входят все или некоторые из следующих объектов: корневая вершина дерева, F-оценка дерева, стоимость С дуги И / ИЛИ-графа, ведущей в корень дерева, список поддеревьев, отношение (И или ИЛИ) между поддеревьями.
Список поддеревьев всегда упорядочен по возрастанию F-оценок. Поддеревья, являющиеся решающими деревьями, помещаются в конец списка.
Обратимся теперь к программе Рисунок 13.12. Отношение самого высокого уровня - это
и_или( Верш, РешДер)
где Верш - стартовая вершина. Программа строит решающее дерево (если таковое существует), рассчитывая на то, что оно окажется оптимальным решением. Будет ли это решение в действительности самым дешевым, зависит от той функции h, которую использует алгоритм. Существует теорема, в которой говорится о том, как оптимальность решения зависит от h. Эта теорема аналогична теореме о допустимости алгоритма поиска с предпочтением в пространстве состояний (гл. 12). Обозначим через С( В) стоимость оптимального решающего дерева для вершины В. Если для каждой вершины В И / ИЛИ-графа эвристическая оценка h( B) <= C( B), то гарантируется, что процедура и_или найдет оптимальное решение. Если же h не удовлетворяет этому условию, то найденное решение может оказаться субоптимальным. Существует тривиальная эвристическая функция, удовлетворяющая условию оптимальности, а именно h = 0 для всех вершин. Ее недостатком является отсутствие эвристической силы.
Основную роль в программе Рисунок 13.12 играет отношение
расширить( Дер, Предел, Дер1, ЕстьРеш)
Дер и Предел - его "входные" аргументы, а Дер1 и ЕстьРеш - "выходные". Аргументы имеют следующий смысл:
Дер - дерево поиска, подлежащее расширению.
Предел - предельное значени F-оценки, при котором еще разрешено наращивать дерево Дер.
ЕстьРеш - индикатор, значения которого указывают на то, какой из следующих трех случаев имеет место:
(1) ЕстьРеш = да: Дер можно "нарастить" (с учетом ограничения Предел) таким образом, чтобы образовалось решающее дерево Дер1.
(2) ЕстьРеш = нет: дерево Дер можно расширить до состояния Дер1, для которого F-оценка превосходит Предел, но прежде чем F-оценка превзошла Предел, решающее дерево не было обнаружено.
(3) ЕстьРеш = никогда: Дер не содержит решения.
В зависимости от случая Дер1 - это либо решающее дерево, либо Дер, расширенное до момента перехода через Предел; если ЕстьРеш = никогда, то переменная Дер1 неинициализирована.
Процедура
расширспис( Деревья, Предел, Деревья1, ЕстьРеш)
аналогична процедуре расширить. Так же, как и в процедуре расширить, Предел задает ограничение на рост дерева, а ЕстьРеш - это индикатор, указывающий, каков результат расширения ("да", "нет" или "никогда"). Первый аргумент - это, на этот раз, список деревьев (И-список или ИЛИ-список):
Деревья = или:[Д1, Д2, ...] или
Деревья = и : [Д1, Д2, ...]
Процедура расширспис выбирает из списка Деревья наиболее перспективное дерево (исходя из F-оценок). Так как деревья в списке упорядочены, таким деревом является первый элемент списка. Наиболее перспективное дерево подвергается расширению с новым ограничением Предел1. Значение Предел1 зависит от Предел, а также от других деревьев списка. Если Деревья - это ИЛИ-список, то Предел1 устанавливается как наименьшая из двух величин: Предел и F-оценка следующего по "качеству" дерева из списка Деревья. Если Деревья - это И-дерево, то Предел1 устанавливается равным Предел минус сумма F-оценок всех остальных деревьев из списка. Значение переменной Деревья1 зависит от случая, задаваемого индикатором ЕстьРеш. Если ЕстьРеш = нет, то Деревья1 - это то же самое, что и список Деревья, причем наиболее перспективное дерево расширено с учетом ограничения Предел1. Если ЕстьРеш = да, то Деревья1 - это решение для всего списка Деревья (найденное без выхода за границы значения Предел). Если ЕстьРеш = никогда, то переменная Деревья1 неинициализирована.
Процедура продолжить, вызываемая после расширения списка деревьев, решает, что делать дальше, в зависимости от результата срабатывания процедуры расширить. Эта процедура либо строит решающее дерево, либо уточняет дерево поиска и продолжает процесс его наращивания, либо выдает сообщение "никогда" в случае, когда было обнаружено, что список деревьев не содержит решения.
line();/* ПРОГРАММА И / ИЛИ-ПОИСКА С ПРЕДПОЧТЕНИЕМ
Эта программа порождает только одно решение. Гарантируется, что это решение самое дешевое при условии, что используемая эвристическая функция является нижней гранью реальной стоимости решающих деревьев.
Дерево поиска имеет одну из следующих форм:
дер( Верш, F, С, Поддеревья) дерево-кандидат
лист( Верш, F, C) лист дерева поиска
решдер( Верш, F, Поддеревья) решающее дерево
решлист( Верш, F) лист решающего дерева
С - стоимость дуги, ведущей в Верш
F = С + Н, где Н - эвристическая оценка оптимального решающего дерева с корнем Верш
Список Поддеревья упорядочен таким образом, что
(1) решающие поддеревья находятся в конце списка;
(2) остальные поддеревья расположены в порядке возрастания F-оценок
*/
:- ор( 500, xfx, :).
:- ор( 600, xfx, --->).
и_или( Верш, РешДер) :-
расширить( лист( Верш, 0, 0), 9999, РешДер, да).
% Предполагается, что 9999 > любой F-оценки
% Процедура расширить( Дер, Предел, НовДер, ЕстьРеш)
% расширяет Дер в пределах ограничения Предел
% и порождает НовДер с "решающим статусом" ЕстьРеш.
% Случай 1: выход за ограничение
расширить( Дер, Предел, Дер, нет) :-
f( Дер, F), F > Предел, !.
% Выход за ограничение
% В остальных случаях F <= Предел
% Случай 2: встретилась целевая вершина
расширить( лист( Верш, F, С), _, решлист( Верш, F), да) : -
цель( Верш), !.
% Случай 3: порождение преемников листа
расширить( лист( Верш, F,C), Предел, НовДер, ЕстьРеш) :-
расшлист( Верш, С, Дер1), !,
расширить( Дер1, Предел, НовДер, ЕстьРеш);
ЕстьРеш = никогда, !.
% Нет преемников, тупик
% Случай 4: расширить дерево
расширить( дер( Верш, F, С, Поддеревья),
Предел, НовДер, ЕстьРеш) :-
Предел1 is Предел - С,
расширспис( Поддеревья, Предел1, НовПоддер, ЕстьРеш1),
продолжить( ЕстьРеш1, Верш, С, НовПоддер, Предел,
НовДер, ЕстьРеш).
% расширспис( Деревья, Предел, Деревья1, ЕстьРеш)
% расширяет деревья из заданного списка с учетом
% ограничения Предел и выдает новый список Деревья1
% с "решающим статусом" ЕстьРеш.
расширспис( Деревья, Предел, Деревья1, ЕстьРеш) :-
выбор( Деревья, Дер, ОстДер, Предел, Предел1),
расширить( Дер, Предел1, НовДер, ЕстьРеш1),
собрать( ОстДер, НовДер, ЕстьРеш1, Деревья1, ЕстьРеш).
% "продолжить" решает, что делать после расширения
% списка деревьев
продолжить( да, Верш, С, Поддеревья, _,
решдер( Верш, F, Поддеревья), да): -
оценка( Поддеревья, Н), F is С + H, !.
продолжить( никогда, _, _, _, _, _, никогда) :- !.
продолжить( нет, Верш, С, Поддеревья, Предел,
НовДер, ЕстьРеш) :-
оценка( Поддеревья, Н), F is С + Н, !,
расширить( дер( Верш, F, С, Поддеревья), Предел,
НовДер, ЕстьРеш).
% "собрать" соединяет результат расширения дерева со списком деревьев
собрать( или : _, Дер, да, Дер, да):- !. % Есть решение ИЛИ-списка
собрать( или : ДД, Дер, нет, или : НовДД, нет) :-
встав( Дер, ДД, НовДД), !.
% Нет решения ИЛИ-списка
собрать( или : [ ], _, никогда, _, никогда) :- !.
% Больше нет кандидатов
собрать( или:ДД, _, никогда, или:ДД, нет) :- !.
% Есть еще кандидаты
собрать( и : ДД, Дер, да, и : [Дер Э ДД], да ) :-
всереш( ДД), !.
% Есть решение И-списка
собрать( и : _, _, никогда, _, никогда) :- !.
% Нет решения И-списка
собрать( и : ДД, Дер, ДаНет, и : НовДД, нет) :-
встав( Дер, ДД, НовДД), !.
% Пока нет решения И-списка
% "расшлист" формирует дерево из вершины и ее преемников
расшлист( Верш, С, дер( Верш, F, С, Оп : Поддеревья)) :-
Верш---> Оп : Преемники,
оценить( Преемники, Поддеревья),
оценка( Оп : Поддеревья, Н), F is С + Н.
оценить( [ ], [ ]).
оценить( [Верш/С | ВершиныСтоим], Деревья) :-
h( Верш, Н), F is С + Н,
оценить( ВершиныСтоим, Деревья1),
встав( лист( Верш, F, С), Деревья1, Деревья).
% "всереш" проверяет, все ли деревья в списке "решены"
всереш([ ]).
всереш( [Дер | Деревья] ) :-
реш( Дер),
всереш( Деревья).
реш( решдер( _, _, _ ) ).
реш( решлист( _ , _) ).
f( Дер, F) :-
% Извлечь F-оценку дерева
arg( 2, Дер, F), !.
% F - это 2-й аргумент Дер
% встав( Дер, ДД, НовДД) вставляет Дер в список
% деревьев ДД; результат - НовДД
встав( Д, [ ], [Д] ) :- !.
встав( Д, [Д1 | ДД], [Д, Д1 | ДД] ) :-
реш( Д1), !.
встав( Д, [Д1 | ДД], [Д1 | ДД1] ) :-
реш( Д),
встав( Д, ДД, ДД1), !.
встав( Д, [Д1 | ДД], [Д, Д1 | ДД] ) :-
f( Д, F), f( Д1, F1), F=< F1, !.
встав( Д, [Д1 | ДД], [ Д1 | ДД1] ) :-
встав( Д, ДД, ДД1).
% "оценка" находит "возвращенную" F-оценку И / ИЛИ-списка деревьев
оценка( или :[Дер | _ ], F) :-
% Первое дерево ИЛИ-списка - наилучшее
f( Дер, F), !.
оценка( и :[ ], 0) :- !.
оценка( и : [Дер1 | ДД], F) :-
f( Дер1, F1),
оценка( и : ДД, F2),
F is F1 + F2, !.
оценка( Дер, F) :-
f( Дер, F).
% Отношение выбор( Деревья, Лучшее, Остальные, Предел, Предел1):
% Остальные - И / ИЛИ-список Деревья без его "лучшего" дерева
% Лучшее; Предел - ограничение для Списка Деревья, Предел1 -
% ограничение для дерева Лучшее
выбор( Оп : [Дер], Дер, Оп : [ ], Предел, Предел) :- !.
% Только один кандидат
выбор( Оп : [Дер | ДД], Дер, Оп : ДД, Предел, Предел1) :-
оценка( Оп : ДД, F),
( Оп = или, !, мин( Предел, F, Предел1);
Оп = и, Предел1 is Предел - F).
мин( А, В, А) :- А < В, !.
мин( А, В, В).
line();Программа поиска с предпочтением в И / ИЛИграфе
Рисунок 13. 12. Программа поиска с предпочтением в И / ИЛИ-графе.
Еще одна процедура
собрать( ОстДер, НовДер, ЕстьРеш1, НовДеревья, ЕстьРеш)
связывает между собой несколько объектов, с которыми работает расширспис. НовДер - это расширенное дерево, взятое из списка деревьев процедуры расширспис, ОстДер - остальные, не измененные деревья из этого списка, а ЕстьРеш1 указывает на "решающий статус" дерева НовДер. Процедура собрать имеет дело с несколькими случаями в зависимости от значения ЕстьРеш1, а также от того, является ли список деревьев И-списком или ИЛИ-списком. Например, предложение
собрать( или : _, Дер, да, Дер, да).
означает: в случае, когда список деревьев - это ИЛИ-список и при только что проведенном расширении получено решающее дерево, считать, что задача, соответствующая всему списку деревьев, также решена, а ее решающее дерево и есть само дерево Дер. Остальные случаи легко понять из текста процедуры собрать.
Для отображения решающего дерева можно определить процедуру, аналогичную процедуре отобр (Рисунок 13.8). Оставляем это читателю в качестве упражнения.
для отображения решающего дерева, найденного
Упражнение
13. 4. Напишите процедуру
отобр2( РешДер)
для отображения решающего дерева, найденного программой и_или Рисунок 13.12. Формат отображения пусть будет аналогичен тому, что применялся в процедуре отобр (Рисунок 13.8), так что процедуру отобр2 можно получить, внеся в отобр изменения, связанные с другим представлением деревьев. Другая полезная модификация - заменить в отобр цель write( Верш) на процедуру, определяемую пользователем
печверш( Верш, H)
которая выведет Верш в удобной для пользователя форме, а также конкретизирует Н в соответствии с количеством символов, необходимом для представления Верш в этой форме. В дальнейшем Н будет использоваться как величина отступа для поддеревьев.
к нему процедуры поиска настоящего
Упражнения
13. 1. Закончите составление программы поиска в глубину (с ограничением) для И / ИЛИ-графов, намеченную в настоящем разделе.
13. 2. Определите на Прологе И / ИЛИ-пространство для задачи "ханойская башня" и примените к нему процедуры поиска настоящего раздела.
13. 3. Рассмотрите какую-нибудь простую детерминированную игру двух лиц с полной информацией и дайте определение ее И / ИЛИ-представления. Используйте программу поиска в И / ИЛИ-графах для построения выигрывающих стратегий в форме И / ИЛИ-деревьев.
