Игры двух лиц с полной информацией
15. 1. Игры двух лиц с полной информацией
Игры, которые мы собираемся обсуждать в данной главе, относятся к классу так называемых игр двух лиц с полной информацией. Примерами таких игр могут служить шахматы, шашки и т.п. В игре участвуют два игрока, которые ходят по очереди, причем оба они обладают полной информацией о текущей игровой ситуации (это определение исключает большинство карточных игр). Игра считается оконченной, если достигнута позиция, являющаяся согласно правилам игры "терминальной" (конечной), например матовая позиция в шахматах. Правилами игры также устанавливается, каков исход игры в этой терминальной позиции.
Для игр такого рода возможно представление в виде дерева игры (или игрового дерева). Вершины этого дерева соответствуют ситуациям, а дуги ходам. Начальная ситуация игры - это корневая вершина; листьями дерева представлены терминальные позиции.
В большинстве игр этого типа возможны следующие исходы: выигрыш, проигрыш и ничья. Мы будем рассматривать здесь игры, имеющие только два возможных исхода - выигрыш и проигрыш. Игры, в которых возможна ничья, можно упрощенно считать играми с двумя исходами - выигрыш и не-выигрыш. Двух участников игры мы будем называть "игроком" и "противником". "Игрок" может выиграть в некоторой нетерминальной позиции с ходом игрока ("позиции игрока"), если в ней существует какой-нибудь разрешенный ход, приводящий к выигрышу. С другой стороны, некоторая нетерминальная позиция с ходом противника ("позиция противника") является выигранной для игрока, если все разрешенные ходы из этой позиции ведут к позициям, в которых возможен выигрыш. Эти правила находятся в полном соответствии с представлением задач в форме И / ИЛИ-дерева, которое мы обсуждали в гл. 13.Между понятиями, относящимися к И / ИЛИ-деревьям, и понятиями, используемыми в играх, можно установить взаимное соответствие следующим образом:
позиции игры вершины, задачи
терминальные позиции целевые вершины,
выигрыша тривиально решаемые задачи
терминальные позиции задачи, не имеющие решения
проигрыша
выигранные позиции задачи, имеющие решение
позиции игрока ИЛИ-вершины
позиции противника И-вершины
Очевидно, что аналогичным образом понятия, относящиеся к поиску в И / ИЛИ-деревьях, можно переосмыслить в терминах поиска в игровых деревьях.
Ниже приводится простая программа, которая определяет, является ли некоторая позиция игрока выигранной.
выигр( Поз) :-
терм_выигр( Поз).
% Терминальная выигранная позиция
выигр( Поз) :-
not терм_проигр( Поз),
ход( Поз, Поз1),
% Разрешенный ход в Поз1
not ( ход( Поз1, Поз2),
not выигр( Поз2) ).
% Ни один из ходов противника не ведет к не-выигрышу
Здесь правила игры встроены в предикат ход( Поз, Поз1), который порождает все разрешенные ходы, а также в предикаты терм_выигр( Поз) и терм_проигр( Поз), которые распознают терминальные позиции, являющиеся, согласно правилам игры, выигранными или проигранными. В последнем из правил программы, содержащем двойное отрицание (not), говорится: не существует хода противника, ведущего к не выигранной позиции. Другими словами: все ходы противника приводят к позициям, выигранным с точки зрения игрока.
Минимаксный принцип
15. 2. Минимаксный принцип
Для игр, представляющих интерес, полный просмотр игрового дерева невозможен, поэтому были разработаны другие методы, предусматривающие просмотр только части дерева игры. Среди этих методов существует страндартный метод поиска, используемый в игровых (особенно в шахматных) программах и основанный на минимаксном принципе. Дерево игры просматривается только вплоть до некоторой глубины (обычно на несколько ходов), а затем для всех концевых вершин дерева поиска вычисляются оценки при помощи некоторой оценочной функции. Идея состоит в том, чтобы, получив оценки этих терминальных поисковых вершин, не продвигаться дальше и получить тем самым экономию времени. Далее, оценки терминальных позиций распространяются вверх по дереву поиска в соответствии с минимаксным принципом. В результате все вершины дерева поиска получают свои оценки. И наконец, игровая программа, участвующая в некоторой реальной игре, делает свой ход - ход, ведущий из исходной (корневой) позиции в наиболее перспективного (с точки зрения оценки) ее преемника.
Обратите внимание на то, что мы здесь делаем определенное различие между "деревом игры" и "деревом поиска". Дерево поиска - это только часть дерева игры (его верхняя часть), т. е. та его часть, которая была явным образом порождена в процессе поиска. Таким образом, терминальные поисковые позиции совсем не обязательно должны совпадать с терминальными позициями самой игры.
Очень многое зависит от оценочной функции, которая для большинства игр, представляющих интерес, является приближенной эвристической оценкой шансов на выигрыш одного из участников игры. Чем выше оценка, тем больше у него шансов выиграть и чем ниже оценка, тем больше шансов на выигрыш у его противника. Поскольку один из участников игры всегда стремится к высоким оценкам, а другой - к низким, мы дадим им имена МАКС и МИН соответственно. МАКС всегда выбирает ход с максимальной оценкой; в противоположность ему МИН всегда выбирает ход с минимальной оценкой. Пользуясь этим принципом (минимаксным принципом) и зная значения оценок для всех вершин "подножья" дерева поиска, можно определить оценки всех остальных вершин дерева. На Рисунок 15.2 показано, как это делается. На этом рисунке видно, что уровни позиций с ходом МАКС'а чередуются с уровнями позиций с ходом МИН'а. Оценки вершин нижнего уровня определяются при помощи оценочной функции. Оценки всех внутренних вершин можно определить, двигаясь снизу вверх от уровня к уровню, пока мы не достигнем корневой вершины. В результате, как видно из Рисунок 15.2, оценка корня оказывается равной 4, и, соответственно, лучшим ходом МАКС'а из позиции а - a-b. Лучший ответ МИН'а на этот ход - b-d, и т.д. Эту последовательность ходов называют также основным вариантом. Основной вариант показывает, какова "минимаксно-оптимальная" игра для обоих участников. Обратите внимание на то, что оценки всех позиций, входящих в основной вариант, совпадают.
Альфабета алгоритм эффективная реализация минимаксного принципа
15. 3. Альфа-бета алгоритм: эффективная реализация минимаксного принципа
Программа, показанная на Рисунок 15.3, производит просмотр в глубину дерева поиска, систематически обходя все содержащиеся в нем позиции вплоть до терминальных; она вычисляет статические оценки всех терминальных позиций. Как правило, для того, чтобы получить правильную минимаксную оценку корневой вершины, совсем не обязательно проделывать эту работу полностью. Поэтому алгоритм поиска можно сделать более экономным. Его можно усовершенствовать, используя следующую идею. Предположим, что у нас есть два варианта хода. Как только мы узнали, что один из них явно хуже другого, мы можем принять правильное решение, не выясняя, на сколько в точности он хуже. Давайте используем этот принцип для сокращения дерева поиска Рисунок 15.2. Процесс поиска протекает следующим образом:
(1) Начинаем с позиции а.
(2) Переходим к b.
(3) Переходим к d.
(4) Берем максимальную из оценок преемников позиции d, получаем V( d) = 4.
(5) Возвращаемся к b и переходим к е.
(6) Рассматриваем первого преемника позиции е с оценкой 5. В этот момент МАКС (который как раз и должен ходить в позиции е) обнаруживает, что ему гарантирована в позиции е оценка не меньшая, чем 5, независимо от оценок других (возможно, более предпочтительных) вариантов хода. Этого вполне достаточно для того, чтобы МИН, даже не зная точной оценки позиции е, понял, что для него в позиции b ход в е хуже, чем ход в d.
На основании приведенного выше рассуждения мы можем пренебречь вторым преемником позиции е и приписать е приближенную оценку 5. Приближенный характер этой оценки не окажет никакого влияния на оценку позиции b, а следовательно, и позиции а.
На этой идее основан знаменитый альфа-бета алгоритм, предназначенный для эффективной реализации минимаксного принципа. На Рисунок 15.4 показан результат работы альфа-бета алгоритма, примененного к нашему дереву Рисунок 15.2. Из Рисунок 15.4 видно, что некоторые из рабочих оценок стали приближенными. Однако этих приближенных оценок оказалось достаточно для того, чтобы определить точную оценку корневой позиции. Сложность поиска уменьшилась до пяти обращений к оценочной функции по сравнению с восемью обращениями (в первоначальном дереве поиска Рисунок 15.2).
Как уже говорилось раньше, ключевая идея альфа-бета отсечения состоит в том, чтобы найти ход не обязательно лучший, но "достаточно хороший" для того, чтобы принять правильное решение. Эту идею можно формализовать, введя два граничных значения, обычно обозначаемых через Альфа и Бета, между которыми должна заключаться рабочая оценка позиции. Смысл этих граничных значений таков: Альфа -это самое маленькое значение оценки, которое к настоящему моменту уже гарантировано для игрока МАКС; Бета - это самое большое значение оценки, на которое МАКС пока еще может надеяться. Разумеется, с точки зрения МИН'а, Бета является самым худшим значением оценки, которое для него уже гарантировано. Таким образом, действительное значение оценки (т. е. то, которое нужно найти) всегда лежит между Альфа и Бета. Если же стало известно, что оценка некоторой позиции лежит вне интервала Альфа-Бета, то этого достаточно для того, чтобы сделать вывод: данная позиция не входит в основной вариант. При этом точное значение оценки такой позиции знать не обязательно, его надо знать только тогда, когда оценка лежит между Альфа и Бета. "Достаточно хорошую" рабочую оценку V( Р, Альфа, Бета) позиции Р по отношению к Альфа и Бета можно определить формально как любое значение, удовлетворяющее следующим ограничениям:
V( P, Альфа, Бета) <= Альфа если V( P) <= Альфа
V( P, Альфа, Бета) = V( P) если Альфа < V( P) < Бета
V( P, Альфа, Бета) >= Бета если V( P) >= Бета
Минимаксные игровые программы усовершенствования и ограничения
15. 4. Минимаксные игровые программы: усовершенствования и ограничения
Минимаксный принцип и альфа-бета алгоритм лежат в основе многих удачных игровых программ, чаще всего шахматных. Общая схема подобной программы такова: произвести альфа-бета поиск из текущей позиции вплоть до некоторого предела по глубине (диктуемого временными ограничениями турнирных правил). Для оценки терминальных поисковых позиций использовать подобранную специально для данной игры оценочную функцию. Затем выполнить на игровой доске наилучший ход, найденный альфа-бета алгоритмом, принять ответный ход противника и запустить тот же цикл с начала.
Таким образом, две основных составляющих игровой программы - это альфа-бета алгоритм и эвристическая оценочная функция. Для того, чтобы создать действительно хорошую программу для такой сложной игры, как шахматы, необходимо внести в эту базовую схему много различных усовершенствований. Ниже приводится краткое описание некоторых из стандартных приемов.
Многое зависит от оценочной функции. Если бы мы располагали абсолютно точной оценочной функцией, мы могли бы ограничить поиск рассмотрением только непосредственных преемников текущей позиции, фактически исключив перебор. Но для таких игр, как шахматы, любая оценочная функция, имеющая практически приемлемую вычислительную сложность, по необходимости будет всего лишь эвристической оценкой. Такая оценка базируется на "статических" свойствах позиции (например, на количестве фигур) и в одних позициях работает надежнее, чем в других. Допустим, например, что мы имеем именно такую оценочную функцию, основанную на соотношении материала, и представим себе позицию, в которой у белых лишний конь. Ясно, что оценка будет в пользу белых. Здесь все в порядке, если позиция "спокойная" и черные не располагают какой-либо сильной угрозой. Но, с другой стороны, если на следующем ходу черные могут взять белого ферзя, то такая оценка может привести к фатальному просмотру из-за своей неспособности к динамическому восприятию позиции. Очевидно, что в спокойных позициях мы можем доверять такой статической оценке в большей степени, чем в активных позициях, когда с каждой из сторон имеются непосредственные угрозы взятия фигур. Поэтому статическую оценку следует использовать только для спокойных позиций. Что же касается активных позиций, то здесь существует такой стандартный прием: следует продолжить поиск из активной позиции за пределы ограничения по глубине и продолжать его до тех пор, пока не встретится спокойная позиция. В частности, таким образом производится просчет разменов фигур в шахматах.
Еще одно усовершенствование - эвристическое отсечение (ветвей). Целью его является достижение большей предельной глубины поиска за счет отбрасывания менее перспективных продолжений. Этот метод позволяет отсекать ветви в дополнение к тем, которые отсекаются самим альфа-бета алгоритмом. В связи с этим возникает риск пропустить какое-нибудь хорошее продолжение и неправильно вычислить минимаксную оценку.
Существует еще один прием, называемый последовательным углублением. Программа многократно выполняет альфа-бета поиск сначала до некоторой небольшой глубины, а затем, увеличивая предел по глубине при каждой итерации. Процесс завершается, когда истекает время, отведенное для вычисления очередного хода. Выполняется наилучший ход, найденный при наибольшей глубине, достигнутой программой. Этот метод имеет следующие преимущества: он облегчает контроль времени: в момент, когда время истекает, всегда имеется некоторый ход - лучший из всех, найденных к настоящему моменту; минимаксные оценки, вычисленные во время предыдущей итерации, можно использовать для предварительного упорядочивания позиций в следующей итерации, что помогает альфа-бета алгоритму следовать стратегии "самые сильные ходы - первыми".
Метод последовательного углубления влечет за собой некоторые накладные расходы (из-за повторного поиска в верхней части игрового дерева), но они незначительны по сравнению c суммарными затратами.
Для наших программ, основанных на описанной выше схеме, существует проблема, известная как "эффект горизонта". Представьте себе шахматную позицию, в которой программе грозит неминуемая потеря коня, однако эту потерю можно отложить, пожертвовав какую-либо менее ценную фигуру, скажем пешку. Эта немедленная жертва сможет отодвинуть потерю коня за пределы доступной глубины поиска (за "горизонт" программы). Не видя грозящей опасности, программа отдаст предпочтение продолжению с жертвой пешки, чтобы избежать быстрой гибели своего коня. В действительности программа потеряет обе фигуры - и пешку (без необходимости), и коня. Эффект горизонта можно несколько смягчить за счет углубления поиска вплоть до спокойных позиций.
Существует, однако, более фундаментальное ограничение на возможности минимаксных игровых программ, проистекающее из той ограниченной формы представления знаний, которая в них используется. Это становится особенно заметным при сравнении лучших шахматных программ с шахматными мастерами (людьми). Хорошая программа просматривает миллионы (и даже больше) позиций, прежде чем принимает решение об очередном ходе. Психологические опыты показали, что шахматные мастера, как правило, просматривают десятки (максимум, несколько сотен) позиций. Несмотря на эту явно меньшую производительность, мастера-шахматисты обыгрывают программы без особых усилий. Преимущество их состоит в их знаниях, значительно превосходящих знания шахматных программ. Игры между машинами и сильными шахматистами показали, что огромное превосходство в вычислительной мощности не способно скомпенсировать недостаток знаний.
Знания в минимаксных игровых программах имеют следующие три основные формы: оценочная функция эвристики для отсечения ветвей эвристики для распознавания спокойных позиций
Оценочная функция сводит все разнообразные аспекты игровой ситуации к одному числу, и это упрощение может нанести вред. В противоположность этому хороший игрок обладает пониманием позиции, охватывающим многие "измерения". Вот пример из области шахмат: оценочная функция оценивает позицию как равную и выдает значение 0. Оценка той же позиции, данная мастером-шахматистом, может быть значительно более информативной, а также может указывать на дальнейший ход игры, например: у белых лишняя пешка, но черные имеют неплохие атакующие возможности, что компенсирует материальный перевес, следовательно, шансы равны.
Минимаксные шахматные программы часто хорошо проявляют себя в острой тактической борьбе, когда решающее значение имеет точный просчет форсированных вариантов. Их слабости обнаруживаются в спокойных позициях, так как они не способны к долговременному планированию, преобладающему при медленной, стратегической игре. Из-за отсутствия плана создается внешнее впечатление, что программа все время перескакивает с одной идеи" на другую. Особенно это заметно в эндшпилях.
В оставшейся части главы мы рассмотрим еще один подход к программированию игр, основанный на внесении в программу знаний о типовых ситуациях при помощи так называемых "советов".
Цели и ограничения на ходы
15. 5. 1. Цели и ограничения на ходы
Основное понятие Языка Советов - "элементарный совет". Элементарный совет содержит указание о том, что следует делать (или пытаться делать) в некоторой типовой ситуации. Совет выражается в терминах тех целей, которые необходимо достичь, и тех средств, которые следует применять для этого. Мы называем участников игры "игроком" и "противником"; совет всегда относится к "игроку". Каждый элементарный совет имеет следующие четыре составные части: главная цель: цель, к которой нужно стремиться; цель-поддержка: цель, которая должна постоянно удовлетворяться в процессе достижения главной цели; ограничения на ходы игрока: предикат, определяющий некоторое подмножество ходов из всех разрешенных ходов игрока (ходы, представляющие интерес с точки зрения достижения указанных целей). ограничения на ходы противника: предикат, выбирающий ходы, которые должен рассмотреть противник (ходы, препятствующие достижению указанных целей).
Рассмотрим, например, шахматный эндшпиль "король и пешка против короля". Здесь применима следующая очевидная идея: провести пешку в ферзи, продвигая ее вперед. В форме совета это выражается так: главная цель: провести пешку; цель-поддержка: не потерять пешку; ходы игрока: продвигать пешку; ходы противника: приближаться королем к пешке.
Выполнимость совета
15. 5. 2. Выполнимость совета
Мы говорим, что элементарный совет выполним в данной позиции, если игрок может форсированным образом достигнуть главной цели, указанной в совете, при условии, что:
(1) ни разу не нарушается цель-поддержка;
(2) все ходы игрока удовлетворяют наложенным на них ограничениям;
(3) противнику разрешено делать только те ходы, которые предусмотрены соответствующими ограничениями.
С выполнимостью элементарного совета связано понятие форсированного дерева. Форсированное дерево задает детальную стратегию, которая гарантирует достижение главной цели при выполнении всех ограничений, содержащихся в элементарном совете. Таким образом, форсированное дерево указывает, как именно должен ходить игрок при любых ответах противника. Более точно, форсированное дерево Т для заданной позиции Р и элементарного совета А есть такое поддерево дерева игры, что корень дерева Т - позиция Р; все позиции из Т удовлетворяют цели-поддержке; все терминальные позиции из Т удовлетворяют главной цели (что, однако, неверно ни для одной внутренней вершины); для каждой внутренней позиции игрока в дереве Т указан только один ход, причем он удовлетворяет ограничениям на ходы игрока; из каждой внутренней позиции противника исходят все ходы противника (удовлетворяющие соответствующим ограничениям).
Каждый элементарный совет можно рассматривать как описание некоторой небольшой специальной игры, имеющей следующие правила. Участникам игры разрешено ходить в пределах ограничений, наложенных на их ходы; позиция, не удовлетворяющая цели-поддержке, считается выигрышем "противника". Нетерминальная позиция считается выигранной с точки зрения игрока, если данный элементарный совет в ней выполним. Таким образом, для того, чтобы выиграть в зтой игре, игрок должен следовать стратегии, задаваемой форсированным деревом.
Правила и таблицы советов
15. 5. 3. Правила и таблицы советов
В Языках Советов отдельные элементарные советы объединяются в полную схему представления знаний, имеющую следующую иерархическую структуру. Элементарный совет является частью "если-то"-правила. Набор "если-то"-правил образует таблицу советов. Множество таблиц советов имеет структуру иерархической сети. Каждая таблица советов выполняет роль эксперта в своей узкой области и работает с какой-нибудь специфической подзадачей. Примером такого специализированного эксперта может служить таблица советов, содержащая знания о том, как поставить мат королем и ладьей. Эта таблица вызывается в том случае, когда в процессе игры возникает соответствующее окончание.
Мы рассмотрим здесь упрощенную версию Языка Советов, допускающую только одну таблицу советов. Будем называть эту версию Язык Советов 0 или, для краткости, AL0 (Advice Language 0). Ниже описывается структура языка AL0, синтаксически специально приспособленная для удобной реализации на Прологе.
Программа на AL0 называется таблицей советов. Таблица советов представляет из себя упорядоченное множество "если-то"-правил. Каждое правило имеет вид:
ИмяПравила: если Условие то СписокСоветов
Условие - это логическое выражение, состоящее из имен предикатов, соединенных между собой логическими связками и, или, не. СписокСоветов - список имен элементарных советов. Приведем пример правила под названием "правило_края" из окончания "король и ладья против короля":
правило_края:
если король_противника_на_краю и короли_рядом
то [мат_2, потеснить, приблизиться,
сохранить_простр, отделить].
В этом правиле говорится: если в текущей позиции король противника находится на краю доски, а король игрока расположен близко к королю противника (точнее, расстояние между королями меньше четырех клеток), то попытаться выполнить в указанном порядке предпочтения следующие советы: "мат_2", "потеснить", "приблизиться", "сохранить_простр", "отделить". Элементарные советы расположены в порядке убывания их "притязаний" на успех: сначала попытаться поставить мат в два хода, если не получится - "потеснить" короля противника в угол и т.д. Обратите внимание на то, что при соответствующем определении операторов наше правило станет синтаксически корректным предложением Пролога.
Для представления элементарных советов в виде прологовских предложений предназначен еще один формат:
совет( ИмяСовета,
ГлавнаяЦель:
ЦельПоддержка:
ХодыИгрока:
ХодыПротивника).
Цели представляются как выражения, состоящие из имен предикатов и логических связок и, или, не. Ограничения на ходы сторон - это тоже выражения, состоящие из имен предикатов и связок и и затем: связка и имеет обычный логический смысл, а затем задает порядок. Например, ограничение, имеющее вид
Огр1 затем Огр2
означает: сначала рассмотреть ходы, удовлетворяющие ограничению Oгp1, а затем - ходы, удовлетворяющие Огр2.
Например, элементарный совет, относящийся к мату в два хода в окончании "король и ладья против короля", записанный в такой синтаксической форме, имеет вид:
совет( мат_2,
мат:
не потеря_ладьи:
(глубина = 0) и разреш затем
(глубина = 2) и ход_шах :
(глубина = 1) и разреш ).
Здесь главная цель - мат, цель-поддержка не потеря_ладьи. Ограничение на ходы игрока означает: на глубине 0 (т. е. в текущей позиции) попробовать любой разрешенный ход и затем на глубине 2 (следующий ход игрока) пробовать только ходы с шахом. Глубина измеряется в полуходах. Ограничение на ходы противника: любой разрешенный ход на глубине 1.
В процессе игры таблица советов используется многократно вплоть до окончания игры, при этом выполняется следующий основной цикл: построить форсированное дерево, затем играть в соответствии с этим деревом, пока не произойдет выход из него; построить другое форсированное дерево и т.д. Форсированное дерево строится каждый раз таким образом: берется текущая позиция Поз и просматриваются одно за другим все правила таблицы советов; для каждого правила сопоставляется Поз с предварительным условием этого правила и просмотр прекращается, когда будет обнаружено правило, для которого Поз удовлетворяет предварительному условию. В этом случае надо рассмотреть список советов найденного правила: обработать элементарные советы один за другим, пока не будет построено форсированное дерево, представляющее собой детальную стратегию игры в этой позиции.
Следует обратить внимание на существенность того порядка, в котором перечисляются правила в таблице советов. Правило, которое реально используется, - это первое из тех правил, предварительные уловия которых согласуются с текущей позицией. Для любой возможной позиции должно существовать по крайней мере одно такое правило. Из него берется список советов, и первый из выполнимых советов списка используется в игре.
Таким образом, таблица советов это программа в высшей степени непроцедурного характера. Интерпретатор языка AL0 принимает на входе некоторую позицию, а затем, "исполняя" таблицу советов, строит форсированное дерево, определяющее стратегию игры в этой позиции.
Знания о типовых ситуациях и механизм "советов"
15. 5. Знания о типовых ситуациях и механизм "советов"
В этом разделе рассматривается метод представления знаний о конкретной игре с использованием семейства Языков Советов. Языки Советов (Advice Languages) дают возможность пользователю декларативным способом описывать, какие идеи следует использовать в тех или иных типовых ситуациях. Идеи формулируются в терминах целей и средств, необходимых для их достижения. Интерпретатор Языка Советов определяет при помощи перебора, какая идея "работает" в данной ситуации.
15. 6. 1. Миниатюрный интерпретатор языка AL0
Реализация на Прологе миниатюрного, не зависящего от конкретной игры интерпретатора языка AL0 показана на Рисунок 15.6. Эта программа осуществляет также взаимодействие с пользователем во время игры. Центральная задача этой программы - использовать знания, записанные в таблице советов, то есть интерпретировать программу на языке советов AL0 с целью построения форсированных деревьев и их "исполнения" в процессе игры. Базовый алгоритм порождения форсированных деревьев аналогичен поиску с предпочтением в И / ИЛИ-графах гл. 13, при этом форсированное дерево соответствует решающему И / ИЛИ-дереву. Этот алгоритм также напоминает алгоритм построения решающего дерева ответа на вопрос пользователя, применявшийся в оболочке экспертной системы (гл. 14).
Программа на Рисунок 15.6 составлена в предположении, что она играет белыми, а ее противник - черными. Программа запускается процедурой
line(); % Миниатюрный интерпретатор языка AL0
%
% Эта программа играет, начиная с заданной позиции,
% используя знания, записанные на языке AL0
:- ор( 200, xfy, :).
:- ор( 220, xfy, ..).
:- ор( 185, fx, если).
:- ор( 190, xfx, то).
:- ор( 180, xfy, или).
:- ор( 160, xfy, и).
:- ор( 140, fx, не).
игра( Поз) :- % Играть, начиная с Поз
игра( Поз, nil).
% Начать с пустого форсированного дерева
игра( Поз, ФорсДер) :-
отобр( Поз),
( конец_игры( Поз), % Конец игры?
write( 'Конец игры'), nl, !;
сделать_ход( Поз, ФорсДер, Поз1, ФорсДер1), !,
игра( Поз1, ФорсДер1) ).
% Игрок ходит в соответствии с форсированным деревом
сделать_ход( Поз, Ход .. ФДер1, Поз1, ФДер1) :-
чей_ход( Поз, б), % Программа играет белыми
разрход( Поз, Ход, Поз1),
показать_ход( Ход).
% Прием хода противника
сделать_ход( Поз, ФДер, Поз1, ФДер1) :-
чей_ход( Поз, ч),
write( 'Ваш ход:'),
read( Ход),
( разрход( Поз, Ход, Поз1),
поддер( ФДер, Ход, ФДер1), !;
% Вниз по форс. дереву
write( 'Неразрешенный ход'), nl,
сделать_ход( Поз, ФДер, Поз1, ФДер1) ).
% Если текущее форсированное дерево пусто, построить новое
сделать_ход( Поз, nil, Поз1, ФДер1) :-
чей_ход( Поз, б),
восст_глуб( Поз, Поз0),
% Поз0 = Поз с глубиной 0
стратегия( Поз0, ФДер), !,
% Новое форсированное дерево
сделать_ход( Поз0, ФДер, Поз1, ФДер1).
% Выбрать форсированное поддерево, соответствующее Ход' у
поддер( ФДеревья, Ход, Фдер) :-
принадлежит( Ход . . Фдер, ФДеревья), !.
поддер( _, _, nil).
стратегия( Поз, ФорсДер) :-
% Найти форс. дерево для Поз
Прав : если Условие то СписСов,
% Обращение к таблице советов
удовл( Условие, Поз, _ ), !,
% Сопоставить Поз с предварительным условием
принадлежит( ИмяСовета, СписСов),
% По очереди попробовать элем. советы
nl, write( 'Пробую'), write( ИмяСовета),
выполн_совет( ИмяСовета, Поз, ФорсДер), !.
выполн_совет( ИмяСовета, Поз, Фдер) :-
совет( ИмяСовета, Совет),
% Найти элементарный совет
выполн( Совет, Поз, Поз, ФДер).
% "выполн" требует две позиции для сравнивающих предикатов
выполн( Совет, Поз, КорнПоз, ФДер) :-
поддержка( Совет, ЦП),
удовл( ЦП, Поз, КорнПоз),
% Сопоставить Поз с целью-поддержкой
выполн1( Совет, Поз, КорнПоз, ФДер).
выполн1( Совет, Поз, КорнПоз, nil) :-
главцель( Совет, ГлЦ),
удовл( ГлЦ, Поз, КорнПоз), !.
% Главная цель удовлетворяется
выполн1( Совет, Поз, КорнПоз, Ход .. ФДеревья) :-
чей_ход( Поз, б), !, % Программа играет белыми
ходы_игрока( Совет, ХодыИгрока),
% Ограничения на ходы игрока
ход( ХодыИгрока, Поз, Ход, Поз1),
% Ход, удовлетворяющий ограничению
выполн( Совет, Поз1, КорнПоз, ФДеревья).
выполн1( Совет, Поз, КорнПоз, ФДеревья) :-
чей_ход( Поз, ч), !, % Противник играет черными
ходы_противника( Совет, ХодыПр),
bagof ( Ход . . Поз1, ход( ХодыПр, Поз, Ход, Поз1), ХПспис),
выполн_все( Совет, ХПспис, КорнПоз, ФДеревья).
% Совет выполним во всех преемниках Поз
выполн_все( _, [ ], _, [ ]).
выполн_все( Совет, [Ход . . Поз | ХПспис], КорнПоз,
[Ход . . ФД | ФДД] ) :-
выполн( Совет, Поз, КорнПоз, ФД),
выполн_все( Совет, ХПспис, КорнПоз, ФДД).
% Интерпретация главной цели и цели-поддержки:
% цель - это И / ИЛИ / НЕ комбинация. имен предикатов
удовл( Цель1 и Цель2, Поз, КорнПоз) :- !,
удовл( Цель1, Поз, КорнПоз),
удовл( Цель2, Поз, КорнПоз).
удовл( Цель1 или Цель2, Поз, КорнПоз) :- !,
( удовл( Цель1, Поз, КорнПоз);
удовл( Цель2, Поз, КорнПоз) ).
удовл( не Цель, Поз, КорнПоз) :- !,
not удовл( Цель, Поз, КорнПоз ).
удовл( Пред, Поз, КорнПоз) :-
( Усл =.. [Пред, Поз];
% Большинство предикатов не зависит от КорнПоз
Усл =.. [Пред, Поз, КорнПоз] ),
call( Усл).
% Интерпретация ограничений на ходы
ход( Ходы1 и Ходы2, Поз, Ход, Поз1) :- !,
ход( Ходы1, Поз, Ход, Поз1),
ход( Ходы2, Поз, Ход, Поз1).
ход( Ходы1 затем Ходы2, Поз, Ход, Поз1) :- !,
( ход( Ходы1, Поз, Ход, Поз1);
ход( Ходы2, Поз, Ход, Поз1) ).
% Доступ к компонентам элементарного совета
главцель( ГлЦ : _, ГлЦ).
поддержка( ГлЦ : ЦП : _, ЦП).
ходы_игрока( ГлЦ : ЦП : ХодыИгрока : _, Ходы Игрока).
ходы_противника( ГлЦ : ЦП: ХодыИгр : ХодыПр :_,
ХодыПр).
принадлежит( X, [X | Спис]).
принадлежит( X, [Y | Спис]) :-
принадлежит( X, Спис).
line();
Программа на языке советов для эндшпиля "король и ладья против короля"
15. 6. 2. Программа на языке советов для эндшпиля
"король и ладья против короля"
Общий принцип достижения выигрыша королем и ладьей против единственной фигуры противника, короля, состоит в том, чтобы заставить короля отступить к краю доски или, при необходимости, загнать его в угол, а затем поставить мат в несколько ходов. В детальном изложении эта стратегия выглядит так:
line();Повторять циклически, пока не будет поставлен мат (постоянно проверяя, что не возникла патовая позиция и что нет нападения на незащищенную ладью):
(1) Найти способ поставить королю противника мат в два хода.
(2) Если не удалось, то найти способ уменьшить ту область доски, в которой
король противника "заперт" под воздействием ладьи.
(3) Если и это не удалось, то найти способ приблизить своего короля к королю
противника.
(4) Если ни один из элементарных советов 1, 2, или 3 не выполним, то найти
способ сохранить все имеющиеся к настоящему моменту "достижения" в
смысле (2) и (3) (т. е. сделать выжидающий ход).
(5) Если ни одна из целей 1, 2, 3 или 4 не достижима, то найти способ получить
позицию, в которой ладья занимает вертикальную или горизонтальную
линию, отделяющую одного короля от другого.
Описанные выше принципы реализованы во всех деталях в таблице советов на языке AL0, показанной на Рисунок 15.7. Эта таблица может работать под управлением интерпретатора Рисунок 15.6.
Программа на языке AL0 для игры в шахматном эндшпиле
15. 6. Программа на языке AL0 для игры в шахматном эндшпиле
При реализации какой-либо игровой программы на языке AL0 ее можно для удобства разбить на три модуля:
(1) интерпретатор языка AL0,
(2) таблица советов на языке AL0,
(3) библиотека предикатов, используемых в таблице советов (в том числе
предикаты, задающие правила игры).
Эта структура соответствует обычной структуре системы, основанной на знаниях: Интерпретатор AL0 выполняет функцию машины логического вывода. Таблица советов вместе с библиотекой предикатов образует базу знаний.
Иллюстрирует смысл некоторых из
Рисунок 15.8 иллюстрирует смысл некоторых из предикатов, использованных в таблице советов, а также показывает, как эта таблица работает.
В таблице используются следующие предикаты:
Предикаты целей
мат мат королю противника
пат пат королю противника
потеря_ладьи король противника может взять ладью
ладья_под_боем
король противника может напасть на ладью прежде, чем наш
король сможет ее защитить
уменьш_простр
уменьшилось "жизненное пространство" короля противника,
ограничиваемое ладьей
раздел
ладья занимает вертикальную или горизонтальную линию,
разделяющую королей
ближе_к_клетке наш король приблизился к "критической клетке" (см. Рисунок 15.9),
т.е. манхеттеновское расстояние до нее уменьшилось
l_конфиг "L-конфигурация" (Рисунок 15.9)
простр_больше_2 "жизненное пространство" короля противника занимает
больше двух клеток
Предикаты, ограничивающие ходы
глубина = N
ход на глубине N дерева поиска
разреш
любой разрешенный ход
ход_шах
ход, объявляющий шах
ход_ладьей
ход ладьей
нет_хода
ни один ход не подходит
сначала_диаг
ход королем, преимущественно по диагонали
% Окончание "король и ладья против короля" на языке AL0
% Правила
правило_края:
если король_противника_на_краю и короли_рядом
то [мат_2, потеснить, приблизиться,
сохранить_простр, отделить_2, отделить_3].
иначе_правило
если любая_поз
то [ потеснить, приблизиться, сохранить_простр,
отделить_2, отделить_3].
% Элементарные советы
совет( мат_2,
мат :
не потеря_ладьи и король_противника_на_краю:
(глубина = 0) и разреш
затем (глубина = 2) и ход_шах :
(глубина = 1) и разреш ).
совет( потеснить,
уменьш_простр и не ладья_под_боем и
раздел и не пат :
не потеря_ладьи :
(глубина = 0) и ход_ладьей :
нет_хода ).
совет( приблизиться,
ближе _к_клетке и не ладья_под_боем и
(раздел или l_конфиг) и
(простр_больше_2 или не наш_король_на_краю):
не потеря_ладьи :
(глубина = 0) и сначала_диаг :
нет_хода ).
совет( сохранить_простр,
ход_противиика и не ладья_под_боем и раздел
и не_дальше_от_ладьи и
(простр_больше_2 или не наш_король_на_краю):
не потеря_ладьи :
(глубина = 0) и сначала_диаг :
нет_хода ).
совет( отделить_2,
ход_противника и раздел и не ладья_под_боем:
не потеря_ладьи :
(глубина < 3) и разреш :
(глубина < 2) и разреш ).
совет( отделить_3,
ход_противника и раздел и не ладья_под_боем:
не потеря_ладьи :
(глубина < 5) и разреш :
(глубина < 4) и разреш ).
Литература
Литература
Минимаксный принцип, реализованный в форме альфа-бета алгоритма, - это наиболее популярный метод в игровом программировании. Особенно часто он применяется в шахматных программах. Минимаксный принцип был впервые предложен Шенноном (Shannon 1950). Возникновение и становление альфа-бета алгоритма имеет довольно запутанную историю. Несколько исследователей независимо друг от друга открыли либо реализовали этот метод полностью или частично. Эта интересная история описана в статье Knuth and Moore (1978). Там же приводится более компактная формулировка альфа-бета алгоритма, использующая вместо минимаксного принципа принцип "него-макса" ("neg-max" principle), и приводится математический анализ производительности алгоритма. Наиболее полный обзор различных минимаксных алгоритмов вместе с их теоретическим анализом содержится в книге Pearl (1984). Существует еще один интересный вопрос, относящийся к минимаксному принципу. Мы знаем, что статическим оценкам следует доверять только до некоторой степени. Можно ли считать, что рабочие оценки являются более надежными, чем исходные статические оценки, из которых они получены? В книге Pearl (1984) собран ряд математических результатов, имеющих отношение к ответу на этот вопрос. Приведенные в этой книге результаты, касающиеся распространения ошибок по минимаксному дереву, объясняют, в каких случаях и почему минимаксный принцип оказывается полезным.
Сборник статей Bramer (1983) охватывает несколько аспектов игрового программирования. Frey (1983) - хороший сборник статей по шахматным программам. Текущие разработки в области машинных шахмат регулярно освещаются в серии Advances in Computer Chess и в журнале ICCA.
Метод Языка Советов, позволяющий использовать знания о типовых ситуациях, был предложен Д. Мики. Дальнейшее развитие этого метода отражено в Bratko and Michi (1980 a, b) и Bratko (1982, 1984, 1985). Программа для игры в эндшпиле "король и ладья против короля", описанная в этой главе, совпадает с точностью до незначительных модификаций с таблицей советов, корректность которой была математически доказана в статье Bratko (1978). Ван Эмден также запрограммировал эту таблицу советов на Прологе (van Emden 1982).
Среди других интересных экспериментов в области машинных шахмат, преследующих цель повысить эффективность знаний (а не перебора), следует отметить Berliner (1977), Pitrat (1977) и Wilkins (1980).
Advances in Computer Chess Series (M.R.B. Clarke, ed). Edinburgh University Press (Vols. 1-2), Pergamon Press (Vol. 3).
Berliner M. A. (1977); A representation and some mechanisms for a problem solving chess program. In: Advances in Computer Chess 1 (M.R.B. Clarke, ed). Edinburgh University Press.
Bramer M. A; (1983, ed). Computer Game Playing: Theory and Practice. Ellis Horwood and John Wiley.
Bratko I. (1978) Proving correctness of strategies in the AL1 assertional language. Information Processing Letters 7: 223-230.
Bratko I. (1982). Knowledge-based problem solving in AL3. In: Machine Intelligence 10 (J. Hayes, D. Michie, J. H. Pao, eds.). Ellis Horwood (an abbreviated version also appears in Bramer 1983).
Bratko I. (1984). Advise and planning in chess end-games. In: Artificial and Human Intelligence (S. Amarel, A. Elithorn, R. Banerji, eds.). North-Holland.
Bratko I. (1985). Symbolic derivation of chess patterns. In: Progress Artificial Intelligence (L. Steels, J. A. Campbell, eds.). Ellis Horwood and John Wiley.
Bratko I. and Michie D. (1980a). A representation of pattern-knowledge in chess end-games. In: Advances in Computer Chess 2 (M.R.B. Clarke, ed). Edinburgh University Press.
Bratko I. and Michie D. (1980b). An advice program for a complex chess programming task. Computer Journal 23: 353-359.
Frey P. W. (1983, ed.). Chess Skill in Man and Machine (second edition). Springer-Verlag.
Knuth D. E. and Moore R. W. (1975). An analysis of alpha-beta pruning. Artificial Intelligence 6: 93-326.
Pearl J. (1984). Heuristics: Intelligent Search Strategies for Computer Problem Solving. Addison-Wesley.
Pitrat J. (1977). A chess combination program which uses plans Artificial Intelligence 8: 275-321.
Shannon C.E. (1950). Programming a computer for playing chess. Philosophical Magazine 41: 256-275. [В сб. Шеннон К. Работы по теории информации и кибернетике. - М.: ИЛ., 1963.]
van Emden M. (1982). Chess end-game advice: a case study in computer utilisation of knowledge. In: Machine Intelligence 10 (J. Hayes, D. Michie, J.H. Pao, eds). Ellis Hordwood.
Wilkins D.E. (1980). Using patterns and plans in chess. Artificial Intelligence 14: 165-203.
Проект
Проект
Напишите программу для какой-нибудь простой игры (такой, как ним), использующую упрощенный алгоритм войска в И / ИЛИ-дереве.
Проект
Рассмотрите какую-нибудь игру двух лиц (например, какой-нибудь нетривиальный вариант крестиков-ноликов). Напишите отношения, задающие правила этой игры (разрешенные ходы и терминальные позиции). Предложите статическую оценочную функцию, пригодную для использования в игровой программе, основанной на альфа-бета алгоритме.
Проект
Рассмотрите какой-нибудь другой простой эндшпиль, например "король и пешка против короля", и напишите для него программу на языке AL0 (вместе с определениями соответствующих предикатов).
line();% Библиотека предикатов для окончания
% "король и ладья против короля"
% Позиция представлена стуктурой:
% ЧейХод..Бх : Бу..Лх : Лу..Чх : Чу..Глуб
% ЧейХод - с чьей стороны ход в этой позиции ('б' или 'ч')
% Бх, Бу - координаты белого короля
% Лх, Лу - координаты белой ладьи
% Чх, Чу - координаты черного короля
% Глуб - глубина, на которой находится эта позиция в дереве
% поиска
% Отношения выбора элементов позиции
чей_ход( ЧейХод.._, ЧейХод).
бк( _..БК.._, БК).
% Белый король
бл( _.._..БЛ.._, БЛ).
% Белая ладья
чк( _.._.._..ЧК.._, ЧК).
% Черный король
глуб( _.._.._.._..Глуб, Глуб).
восст_глуб( ЧХ..Б..Л..Ч..Г, ЧХ..Б..Л..Ч..0).
% Формируется копия позиции, глубина устанавливается в 0
% Некоторые отношения между клетками доски
сосед_чсл( N, N1) :-
% Соседнее число "в пределах доски"
( N1 is N + 1;
N1 is N - 1 ),
внутри( N1).
внутри( N) :-
N > 0, N < 9.
сосед_диаг( X : Y, X1 : Y1) :-
% Соседние клетки по диагонали
сосед_чсл( X, X1 ), сосед_чсл( Y, Y1).
сосед_верт( X : Y, X : Y1) :-
% Соседние клетки по вертикали
сосед_чсл( Y, Y1).
сосед_гор( X : Y, X1 : Y) :-
% Соседние клетки по горизонтали
сосед_чсл( X, X1).
сосед( S, S1) :-
% Соседние клетки (предпочтение - диагонали)
сосед_диаг( S, S1);
сосед_гор( S, S1);
сосед_верт( S, S1).
конец_игры( Поз) :-
мат( Поз).
% Предикаты, ограничивающие ходы
% Специализированное генераторы ходов вида:
% ход( Ограничение, Поз, Ход, Поз1)
ход( глубина < Макс, Поз, Ход, Поз1) :-
глуб( Поз, Г),
Г < Макс, !.
ход( глубина = Г, Поз, Ход, Поз1) :-
глуб( Поз, Г), !.
ход( сначала диаг, б..Б..Л..Ч..Г, Б-Б1,
ч..Б1..Л..Ч..Г1) :-
Г1 is Г + l,
сосед( Б, Б1),
% "сосед" порождает сначала диагональные ходы
not сосед( Б1, Ч),
% Не попасть под шах
Б1 \== Л.
% Не столкнуться с ладьей
ход( ход ладьей, б..Б..Лх : Лу..Ч..Г, Лх : Лу-Л,
ч..Б..Л..Ч..Г1) :-
Г1 is Г + 1,
коорд( I),
% Число между 1 и 8
( Л = Лх : I; Л = I : Лу),
% По горизонтали или по вертикали
Л \== Лх : Лу,
% Обязательно двигаться
not мешает( Лх : Лу, Б, Л).
% Мешает белый король
ход( ход_шах, Поз, Л-Лх : Лу, Поз1) :-
бл( Поз, Л),
чк( Поз, Чх : Чу),
( Лх = Чх; Лу = Чу),
% Ладья и черный король на одной линии
ход( ход_ладьей, Поз, Л-Лх : Лу, Поз1).
ход( разреш, б..П, М, П1) :-
( Огр = сначала_диаг; Огр = ход ладьей),
ход( Огр, б..П, М, П1).
ход( разреш, ч..Б..Л..Ч..Г, Ч-Ч1, б..Б..Л..Ч1..Г1) :-
Г1 is Г + 1,
сосед( Ч, Ч1),
not шах( б..Б..Л..Ч1..Г1).
разрход( Поз, Ход, Поз1) :-
ход( разреш, Поз, Ход, Поз1).
шах( _..Б..Лх : Лу..Чх : Чу.._ ) :-
сосед( Б, Чх : Чу);
% Короли рядом
( Лх = Чх; Лу = Чу),
Лх : Лу \== Чх : Чу,
% Нет взятия ладьи
not мешает( Лх : Лу, Б, Чх : Чу).
мешает( S, S1, S1) :- !.
мешает( X1 : Y, X2 : Y, Х3 : Y) :-
упоряд( X1, Х2, Х3), !.
мешает( X : Y1, X : Y2, X : Y3) :-
упоряд( Y1, Y2, Y3).
упоряд( N1, N2, N3) :-
N1 < N2, N2 < N3;
N3 < N2, N2 < N1.
коорд( 1). коорд( 2). коорд( 3). коорд( 4).
коорд( 5). коорд( 6). коорд( 7). коорд( 8).
% Предикаты целей
любая_поз( Поз).
ход_противника( б.._ ). % Противник ходит белыми
мат( Поз) :-
чей_ход( Поз, ч),
шах( Поз),
not разрход( Поз, _, _ ).
пат( Поз) :-
чей_ход( Поз, ч),
not шах( Поз),
not разрход( Поз, _, _ ).
уменьш_простр( Поз, КорнПоз) :-
простр( Поз, Пр),
простр( КорнПоз, КорнПр),
Пр < КорнПр.
ладья_под_боем( ЧейХод..Б..Л..Ч.._ ) :-
расст( Б, Л, Р1),
расст( Ч, Л, Р2),
( ЧейХод = б, !, Р1 > Р2 + 1;
ЧейХод = ч, !, Р1 > Р2 ).
ближе_к_клетке( Поз, КорнПоз) :-
расст_до_клетки( Поз, Р1),
расст_до_клетки( КорнПоз, Р2),
Р1 < Р2.
расст_до_клетки( Поз, Мрасст) :-
% Манхеттеновское расстояние
бк( Поз, БК), % между БК и критической клеткой
кк( Поз, КК), % Критическая клетка
манх_расст( БК, КК, Мрасст).
раздел( _..Бх : Бу..Лх : Лу.. Чх : Чу.._ ) :-
упоряд( Бх, Лх, Чх), !;
упоряд( Бу, Лу, Чу).
l_конфиг( _..Б..Л..Ч.._ ) :-
% L - конфигурация
манх_расст( Б, Ч, 2),
манх_расст( Л, Ч, 3).
не дальше_от_ладьи( _..Б..Л.._, _..Б1..Л1.._ ) :-
расст( Б, Л, Р),
расст( Б1, Л1, Р1),
Р =< Р1.
простр_больше_2( Поз) :-
простр( Поз, Пр),
Пр > 2.
наш_король_на_краю( _..Х : Y.._ ) :-
% Белый король на краю
( X = 1, !; X = 8, !; Y = 1, !; Y = 8).
король_противника_на_краю( _..Б..Л..Х : Y.._ ) :-
% Черный король на краю
( X = 1, !; X = 8, !; Y = 1, !; Y = 8).
короли_рядом( Поз) :-
% Расстояние между королями < 4
бк( Поз, БК), чк( Поз, ЧК),
расст( БК, ЧК, Р),
Р < 4.
потеря_ладьи( _..Б..Л..Л.._ )- % Ладья взята
потеря_ладьи( ч..Б..Л..Ч.._ ) :-
сосед( Ч, Л), % Черный король напал на ладью
not сосед( Б, Л). % Белый король не защищает ладью
расст( X : Y, X1 : Y1, Р) :-
% Расстояние до короля
абс_разн( X, X1, Рх),
абс_разн( Y, Y1, Ру),
макс( Рх, Ру, Р).
абс_разн( А, В, С) :-
А > В, !, С is A - В;
С is В - А.
макс( А, В, М) :-
А >= В, !, М = А;
М = В.
манх_расст( X : Y, X1 : Y1, Р) :- % Манхеттеновское расстояние
абс_разн( X, X1, Рх),
абс_разн( Y, Y1, Ру),
P is Рх + Ру.
простр( Поз, Пр) :-
% Область, в которой "заперт" черный король
бл( Поз, Лх : Лу),
чк( Поз, Чх : Чу),
( Чх < Лх, СторонаХ is Лх - 1;
Чх > Лх, СторонаХ is 8 - Лх ),
( Чу < Лу, СторонаY is Лу - 1;
Чу > Лу, СторонаY is 8 - Лу ),
Пр is СторонаХ * СторонаY, !;
Пр = 64. % Ладья и черный король на одной линии
кк( _..Б..Лх : Лу.. Чх : Чу.._, Кх : Ку) :-
% Критическая клетка
( Чх < Лх, !, Кх is Лх - 1; Кх is Лх + 1),
( Чу < Лу, !, Ку is Лу - 1; Ку is Лу + 1).
% Процедуры для отображения позиций
отобр( Поз) :-
nl,
коорд( Y), nl,
коорд( X),
печ_фиг( X : Y, Поз),
fail.
отобр( Поз) :-
чей_ход( Поз, ЧХ), глуб( Поз, Г),
nl, write( 'ЧейХод='), write( ЧХ),
write( 'Глубина='), write( Г), nl.
печ_фиг( Клетка, Поз):-
бк( Поз, Клетка), !, write( 'Б');
бл( Поз, Клетка), !, write( 'Л');
чк( Поз, Клетка), !, write( 'Ч');
write( '.').
показать_ход( Ход) :-
nl, write( Ход), nl.
Игры двух лиц поддаются формальному
Резюме
Игры двух лиц поддаются формальному представлению в виде И / ИЛИ-графов. Поэтому процедуры поиска в И / ИЛИ-графах применимы для поиска в игровых деревьях. Простой алгоритм поиска в глубину в игровых деревьях легко программируется, но для игр, представляющих интерес, он не эффективен. Более реалистичный подход - минимаксный принцип в сочетании с оценочной функцией и поиском, ограниченным по глубине. Альфа-бета алгоритм является эффективной реализацией минимаксного принципа. Эффективность альфа-бета алгоритма зависит от порядка, в котором просматриваются варианты ходов. Применение альфа-бета алгоритма приводит, в лучшем случае, к уменьшению коэффициента ветвления дерева поиска, соответствующему извлечению из него квадратного корня. В альфа-бета алгоритм можно внести ряд усовершенствований. Среди них: продолжение поиска за пределы ограничения по глубине вплоть до спокойных позиций, последовательное углубление и эвристическое отсечение ветвей. Численная оценка позиций является весьма ограниченной формой представления знаний о конкретной игре. Более богатый по своим возможностям метод представления знаний должен предусматривать внесение в программу знаний о типовых ситуациях. Язык Советов (Advice Language) реализует такой подход. На этом языке знания представляются в терминах целей и средств для их достижения. В даннной главе мы составили следующие программы: программная реализация минимаксного принципа и альфа-бета процедуры, интерпретатор языка AL0 и таблица советов для окончания "король и ладья против короля". Были введены и обсуждены следующие понятия:
игры двух лиц с полной информацией
игровые деревья
оценочная функция, минимаксный принцип
статические оценки, рабочие оценки
альфа-бета алгоритм
последовательное углубление,
эвристическое отсечение,
эвристики для обнаружения спокойных позиций
Языки Советов
цели, ограничения, элементарные советы,
таблица советов
Сложность игровых
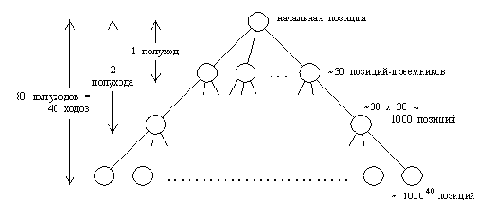
Рисунок 15. 1. Сложность игровых деревьев в шахматах. Оценки основаны
на том, что в каждой шахматной позиции существуют приблизительно
30 разрешенных ходов я что терминальные позиции расположены на
глубине 40 ходов. Один ход равен двум полуходам (по одному
полуходу с каждой стороны).
Так же, как и аналогичная программа поиска в И / ИЛИ-графах, приведенная выше программа использует стратегию в глубину. Кроме того, в ней не исключается возможность зацикливания на одних и тех же позициях. Попытка устранить этот недостаток может привести к осложнениям, поскольку правила некоторых из игр допускают такое повторение позиций. Правда, разрешение повторять позиции часто носит условный характер, например по шахматным правилам после троекратного повторения позиции может быть объявлена ничья.
Программа, которую мы составили, демонстрирует основные принципы программирования игр. Но практически приемлемая реализация таких сложных игр, как шахматы или го, потребовала бы привлечения значительно более мощных методов. Огромная комбинаторная сложность этих игр делает наш наивный переборный алгоритм, просматривающий дерево вплоть до терминальных игровых позиций, абсолютно непригодным. Этот вывод иллюстрирует (на примере шахмат) Рисунок 15.1: пространство поиска имеет астрономические размеры - около 10120 позиций. Можно возразить, что в дереве на Рисунок 15.1 встречаются одинаковые позиции. Однако было показано, что число различных позиций дерева поиска находится далеко за пределами возможностей вычислительных машин обозримого будущего.
Статические (нижний
Рисунок 15. 2. Статические (нижний уровень) и минимаксные рабочие
оценки вершин дерева поиска. Выделенные ходы образуют основной
вариант, т. е. минимаксно-оптимальную игру с обеих сторон.
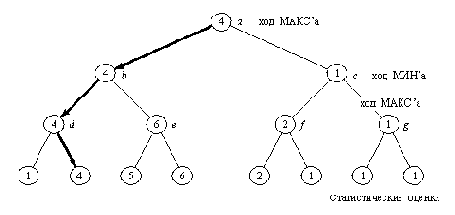
Мы различаем два вида оценок: оценки вершин нижнего уровня и оценки внутренних вершин (рабочие оценки). Первые из них называются также "статическими", так как они вычисляются при помощи "статической" оценочной функции, в противоположность рабочим оценкам, получаемым "динамически" при распространении статических оценок вверх по дереву.
Правила распространения оценок можно сформулировать следующим образом. Будем обозначать статическую оценку позиции Р через v( P), а ее рабочую оценку - через V( Р). Пусть Р1, ..., Рn - разрешенные преемники позиции Р. Тогда соотношения между статическими и рабочими оценками можно записать так:
V( Р) = v( P)
если Р - терминальная позиция дерева поиска (n=0)
V( Р) = max V( Рi
)
i
если P - позиция с ходом МАКС'а
V( Р) = min V( Рi
)
i
если Р - позиция с ходом МИН'а
line();% Минимаксная процедура: минимакс( Поз, ЛучшПоз, Оц)
% Поз - позиция, Оц - ее минимаксная оценка;
% лучший ход из Поз ведет в позицию ЛучшПоз
минимакс( Поз, ЛучшПоз, Оц) :-
ходы( Поз, СписПоз), !,
% СписПоз - список разрешенных ходов
лучш( СписПоз, ЛучшПоз, Оц);
стат_оц( Поз, Оц).
% Поз не имеет преемников
лучш( [Поз], Поз, Оц) :-
минимакс( Поз, _, Оц), !.
лучш( [Поз1 | СписПоз], ЛучшПоз, ЛучшОц) :-
минимакс( Поз1, _, Оц1),
лучш( СписПоз, Поз2, Оц2),
выбор( Поз1, Оц1, Поз2, Оц2, ЛучшПоз, ЛучшОц).
выбор( Поз0, Оц0, Поз1, Оц1, Поз0, Оц0) :-
ход_мина( Поз0), Оц > Оц1, !;
ход_макса( Поз0), Оц < Оц1, !.
выбор( Поз0, Оц0, Поз1, Оц1, Поз1, Оц1).
line();Упрощенная реализация минимаксного принципа
Рисунок 15. 3. Упрощенная реализация минимаксного принципа.
Программа на Прологе, вычисляющая минимаксную рабочую оценку для некоторой заданной позиции, показана на Рисунок 15.3. Основное отношение этой программы -
минимакс( Поз, ЛучшПоз, Оц)
где Оц - минимаксная оценка позиции Поз, а ЛучшПоз - наилучшая позиция-преемник позиции Поз (лучший ход, позволяющий достигнуть оценки Оц). Отношение
ходы( Поз, СписПоз)
задает разрешенные ходы игры: СписПоз - это список разрешенных позиций-преемников позиции Поз. Предполагается, что цель ходы имеет неуспех, если Поз является терминальной поисковой позицией (листом дерева поиска). Отношение
лучш( СписПоз, ЛучшПоз, ЛучшОц)
выбирает из списка позиций-кандидатов СписПоз "наилучшую" позицию ЛучшПоз. ЛучшОц - оценка позиции ЛучшПоз, а следовательно, и позиции Поз. Под "наилучшей" оценкой мы понимаем либо максимальную, либо минимальную оценку, в зависимости от того, с чьей стороны ожидается ход.
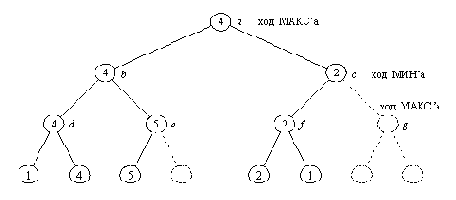
Рисунок 15. 4. Дерево Рисунок 15.2 после применения альфа-бета алгоритма.
Пунктиром показаны ветви, отсеченные альфа-бета алгоритмом
для экономии времени поиска. В результате некоторые из
рабочих оценок стали приближенными (вершины c, е, f;
сравните с Рисунок 15.2). Однако этих приближенных оценок
достаточно для вычисления точной оценки корневой
вершины и построения основного варианта.
Очевидно, что, умея вычислять "достаточно хорошую" оценку, мы всегда можем вычислить точную оценку корневой позиции Р, установив границы интервала следующим образом:
V( Р, -бесконечность, +бесконечность) = V( P)
На Рисунок 15.5 показана реализация альфа-бета алгоритма в виде программы на Прологе. Здесь основное отношение -
альфабета( Поз, Альфа, Бета, ХорПоз, Оц)
где ХорПоз - преемник позиции Поз с "достаточно хорошей" оценкой Оц, удовлетворяющей всем указанным выше ограничениям:
Оц = V( Поз, Альфа, Бета)
Процедура
прибл_лучш( СписПоз, Альфа, Бета, ХорПоз, Оц)
находит достаточно хорошую позицию ХорПоз в списке позиций СписПоз; Оц - приближенная (по отношению к Альфа и Бета) рабочая оценка позиции ХорПоз.
Интервал между Альфа и Бета может сужаться (но не расширяться!) по мере углубления поиска, происходящего при рекурсивных обращениях к альфа-бета процедуре. Отношение
нов_границы( Альфа, Бета, Поз, Оц, НовАльфа, НовБета)
определяет новый интервал (НовАльфа, НовБета). Он всегда уже, чем старый интервал (Альфа, Бета), или равен ему. Таким образом, чем глубже мы оказываемся в дереве поиска, тем сильнее проявляется тенденция к сжатию интервала Альфа-Бета, и в результате оценивание позиций на более глубоких уровнях происходит в условиях более тесных границ. При более узких интервалах допускается большая степень "приблизительности" при вычислении оценок, а следовательно, происходит больше отсечений ветвей дерева. Возникает интересный вопрос: насколько велика экономия, достигаемая альфа-бета алгоритмом по сравнению с программой минимаксного полного перебора Рисунок 15.3?
Эффективность альфа-бета процедуры зависит от порядка, в котором просматриваются позиции. Всегда лучше первыми рассматривать самые сильные ходы с каждой из сторон. Легко показать на примерах, что
line(); % Альфа-бета алгоритм
альфабета( Поз, Альфа, Бета, ХорПоз, Оц) :-
ходы( Поз, СписПоз), !,
прибл_лучш( СписПоз, Альфа, Бета, ХорПоз, Оц);
стат_оц( Поз, Оц).
прибл_лучш( [Поз | СписПоз], Альфа, Бета, ХорПоз, ХорОц) :-
альфабета( Поз, Альфа, Бета, _, Оц),
дост_хор( СписПоз, Альфа, Бета, Поз, Оц, ХорПоз, ХорОц).
дост_хор( [ ], _, _, Поз, Оц, Поз, Оц) :- !.
% Больше нет кандидатов
дост_хор( _, Альфа, Бета, Поз, Оц, Поз, Оц) :-
ход_мина( Поз), Оц > Бета, !;
% Переход через верхнюю границу
ход_макса( Поз), Оц < Альфа, !.
% Переход через нижнюю границу
дост_хор( СписПоз, Альфа, Бета, Поз, Оц, ХорПоз, ХорОц) :-
нов_границы( Альфа, Бета, Поз, Оц, НовАльфа, НовБета),
% Уточнить границы
прибл_лучш( СписПоз, НовАльфа, НовБета, Поз1, Оц1),
выбор( Поз, Оц, Поз1, Оц1, ХорПоз, ХорОц).
нов_границы( Альфа, Бета, Поз, Оц, Оц, Бета) :-
ход_мина( Поз), Оц > Альфа, !.
% Увеличение нижней границы
нов_границы( Альфа, Бета, Поз, Оц, Альфа, Оц) :-
ход_макса( Поз), Оц < Бета, !.
% Уменьшение верхней границы
нов_границы( Альфа, Бета, _, _, Альфа, Бета).
выбор( Поз, Оц, Поз1, Оц1, Поз, Оц) :-
ход_мина( Поз), Оц > Оц1, !;
ход_макса( Поз), Оц < Оц1, !.
выбор( _, _, Поз1, Оц1, Поз1, Оц1).
line();
Реализация альфабета алгоритма
Рисунок 15. 5. Реализация альфа-бета алгоритма.
возможен настолько неудачный порядок просмотра, что альфа-бета алгоритму придется пройти через все вершины, которые просматривались минимаксным алгоритмом полного перебора. Это означает, что в худшем случае альфа-бета алгоритм не будет иметь никаких преимуществ. Однако, если порядок просмотра окажется удачным, то экономия может быть значительной. Пусть N - число терминальных поисковых позиций, для которых вычислялись статические оценки алгоритмом минимаксного полного перебора. Было доказано, что в лучшем случае, когда самые сильные ходы всегда рассматриваются первыми, альфа-бета алгоритм вычисляет статические оценки только для N позиций.
Этот результат имеет один практический аспект, связанный с проведением турниров игровых программ. Шахматной программе, участвующей в турнире, обычно дается некоторое определенное время для вычисления очередного хода, и доступная программе глубина поиска зависит от этого времени. Альфа-бета алгоритм сможет пройти при поиске вдвое глубже по сравнению с минимаксным полным перебором, а опыт показывает, что применение той же оценочной функции, но на большей глубине приводит к более сильной игре.
Экономию, получаемую за счет применения альфа-бета алгоритма, можно также выразить в терминах более эффективного коэффициента ветвления дерева поиска (т. е. числа ветвей, исходящих из каждой внутренней вершины). Пусть игровое дерево имеет единый коэффициент ветвления, равный b. Благодаря эффекту отсечения альфа-бета алгоритм просматривает только некоторые из существующих ветвей и тем самым уменьшает коэффициент ветвления. В результате коэффициент b превратится в b (в лучшем случае). В шахматных программах, использующих альфа-бета алгоритм, достигается коэффициент ветвления, равный 6, при наличии 30 различных вариантов хода в каждой позиции. Впрочем, на этот результат можно посмотреть и менее оптимистично: несмотря на применение альфа-бета алгоритма, после каждого продвижения вглубь на один полуход число терминальных поисковых вершин увеличивается примерно в 6 раз.
Рисунок 15. 6. Миниатюрный интерпретатор языка AL0.
игра( Поз)
где Поз - выбранная начальная позиция. Если в позиции Поз ходит противник, то программа принимает его ход, в противном случае - "консультируется" с таблицей советов, приложенной к программе, порождает форсированное дерево и делает свой ход в соответствии с этим деревом. Так продолжается до окончания игры, которое обнаруживает предикат конец_игры (например, если поставлен мат).
Форсированное дерево - это дерево ходов, представленное в программе следующей структурой:
Ход . . [ Ответ1 . . Фдер1, Ответ2 . . Фдер2, . . . ]
Здесь ".." - инфиксный оператор; Ход - первый ход "игрока"; Ответ1, Ответ2, ... - возможные ответы противника; Фдер1, Фдер2, ... - форсированные поддеревья для каждого из этих ответов.
Таблица советов на
Рисунок 15. 7. Таблица советов на языке AL0 для окончания "король
и ладья против короля". Таблица состоит из двух правил и шести
элементарных советов.
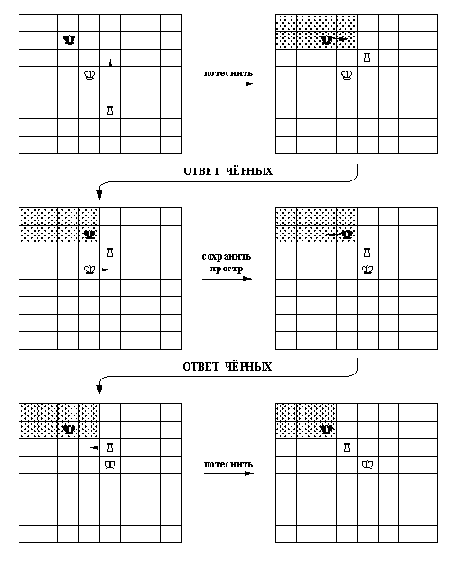
Фрагмент шахматной
Рисунок 15. 8. Фрагмент шахматной партии, полученный с использованием
таблицы советов Рисунок 15.7 и иллюстрирующий применение стратегии
оттеснения короля в угол доски. В этой последовательности ходов
выполнялись элементарные советы: сохранить_ простр (выжидающий
ход, сохраняющий "жизненное пространство" черного короля) и
потеснить (ход, сокращающий "жизненное пространство"). Область,
в которой заключен черный король, выделена штриховкой. После
выполнения последнего совета потеснить эта область сократилась
с восьми до шести клеток.
а) "Критическая
Рисунок 15. 9. (а) "Критическая клетка" отмечена крестиком. Она
используется при маневрировании с целью оттеснить черного
короля. Белый король приближается к "критической клетке",
двигаясь, как указано на рисунке. (б) Три фигуры образуют
конфигурацию, напоминающую букву L.

Аргументами этих предикатов являются либо позиции (в предикатах целей), либо ходы (в предикатах, ограничивающих ходы). Предикаты целей могут иметь один или два аргумента. Первый из аргументов - это всегда текущая вершина поиска; второй аргумент (если он имеется) - корневая вершина дерева поиска. Второй аргумент необходим в так называемых сравнивающих предикатах, которые сравнивают корневую и текущую позиции в том или ином отношении. Например, предикат уменьш_простр проверяет, сократилось ли "жизненное пространство" короля противника (Рисунок 15.8). Эти предикаты вместе с шахматными правилами (применительно к окончанию "король и ладья против короля"), а также процедура для отображения текущего состояния игровой доски ( отобр ( Поз) ) запрограммированы на Рисунок 15.10.
На Рисунок 15.8 показано, как играет наша программа, основанная на механизме советов. При продолжении игры из последней позиции Рисунок 15.8 она могла бы протекать так, как в приведенном ниже варианте (в предположении, что "противник" ходит именно так, как указано). Здесь использована алгебраическая шахматная нотация, в которой вертикальные линии пронумерованы, как 'а', 'b', 'с', .... а горизонтальные - как 1, 2, 3, ... . Например, ход ЧК b7 означает: передвинуть черного короля на клетку. расположенную на пересечении вертикальной линии 'b' с горизонтальной линией 7.
... ЧК b7
БК d5 ЧК с7
БК с5 ЧК b7
БЛ с6 ЧК а7
БЛ b6 ЧК а8
БК b5 ЧК а7
БК с6 ЧК а8
БК с7 ЧК а7
БЛ с6 ЧК а8
БЛ а6 мат
Теперь уместно задать некоторые вопросы. Во-первых, является ли наша программа-советчик корректной в том смысле, что она ставит мат при любом варианте защиты со стороны противника и при любой начальной позиции, в которой на доске король и ладья против короля? В статье Bratko (1978) приведено формальное доказательство того, что таблица советов, практически совпадающая с таблицей Рисунок 15.7, действительно является корректной в указанном смысле.
Другой возможный вопрос: является ли программа оптимальной, то есть верно ли, что она ставит мат за минимальное число ходов? Нетрудно показать на примерах, что игру нашей программы в этом смысле нельзя назвать оптимальной. Известно, что оптимальный вариант в этом окончании (т.е. предполагающий оптимальную игру с обеих сторон) имеет длину не более 16 ходов. Хотя наша таблица советов и далека от этого оптимума, было показано, что число, ходов наверняка не превосходит 50. Это важный результат в связи с тем, что в шахматах существует "правило 50-ти ходов": в эндшпилях типа "король и ладья против короля" противник, имеющий преимущество, должен поставить, мат не более, чем за 50 ходов; иначе может быть объявлена ничья.
Библиотека предикатов для окончания "король и ладья против короля"
Рисунок 15. 10. Библиотека предикатов для окончания "король и ладья против короля".
Основные понятия
16. 1. 1. Основные понятия
Под системами, ориентированными на типовые конфигурации (образцы), мы будем понимать программные системы специальной архитектуры. Для некоторых конкретных типов задач такая архитектура дает преимущества по сравнению с традиционным способом организации. Среди задач, которые естественным образом вписываются в этот вид архитектуры, находятся многие приложения искусственного интеллекта, в том числе экспертные системы. Основное различие между традиционными системами и системами, ориентированными на образцы, заключается в механизме запуска программных модулей. Традиционная архитектура предполагает, что модули системы обращаются друг к другу в соответствии с фиксированной, заранее заданной и явным образом сформулированной схемой. Каждый программный модуль сам принимает решение о том, какой из других модулей следует запустить в данный момент, причем в нем содержится явное обращение к этим модулям. Соответствующая временная структура передач управления от одних модулей к другим оказывается последовательной и детерминированной.
В противоположность этому организация, ориентированная на образцы, не предполагает прямого обращения из одних модулей к другим. Модули запускаются конфигурациями, возникающими в их "информационной среде". Такие программные модули называют модулями, управляемыми типовыми конфигурациями (или образцами). Программа, управляемая образцами, представляет из себя набор модулей. Каждый модуль определяется
(1) образцом, соответствующим предварительному условию запуска, и
(2) тем действием, которое следует выполнить, если информационная среда
согласуется с заданным образцом.
Запуск модулей на выполнение происходит при появлении тех или иных конфигураций в информационной среде системы. Такую информационную среду обычно называют базой данных. Наглядное представление о системе рассматриваемого типа дает Рисунок 16.1.
Следует сделать несколько важных замечаний относительно Рисунок 16.1. Совокупность модулей не имеет иерархической структуры. Отсутствуют явные указания на то, какие модули могут обращаться к каким-либо другим модулям. Модули связаны скорее с базой данных, чем непосредственно друг с другом. В принципе такая структура допускает параллельное выполнение сразу нескольких модулей, поскольку текущее состояние базы данных может прийти в соот-
Прологовские программы как системы управляемые образцами
16. 1. 2. Прологовские программы как системы, управляемые образцами
Программы, написанные на Прологе, можно рассматривать как системы, управляемые образцами. Между пролог-программами и этими системами можно установить соответствие примерно следующим образом: Каждое предложение прологовской программы можно считать отдельным модулем со своим пусковым образцом. Голова предложения соответствует образцу, тело - тому действию, которое выполняет модуль. База данных системы - это текущий список целей, которые пролог-система пытается удовлетворить. Предложение пролог-системы "запускается", если его голова сопоставима с целью, расположенной первой в базе данных. Выполнить действие модуля (т.е. тело предложе ния) - это значит: поместить в базу данных вместо первой из целей весь список целей тела предложения (с соответствующей конкретизацией переменных). Процесс активизации модулей (предложений) не детерминирован в том смысле, что с первой целью базы данных могут удачно сопоставить свою голову сразу несколько предложений, и, вообще говоря, любое из них может быть запущено. В Прологе этот недетерминизм реализован при помощи механизма возвратов.
Пример составления программы
16. 1. 3. Пример составления программы
С системами, управляемыми образцами, связан свой особый стиль программирования, требующий специфического программистского мышления. Мы говорим в этом случае о программировании в терминах образцов.
В качестве иллюстрации, рассмотрим элементарное упражнение по программированию - вычисление наибольшего общего делителя D двух целых чисел А и В. Рассмотрим классический алгоритм Евклида:
line();Для того, чтобы вычислить наибольший общий делитель D чисел А и В, необходимо:
Повторять циклически, пока А и В не совпадут:
если А > В, то заменить А на А - В, иначе заменить В на В - А.
После выхода из цикла А и В совпадают; наибольший общий делитель D равен
А (или В).
Тот же самый процесс можно описать при помощи двух модулей, управляемых образцами:
Модуль 1
Условие В базе данных существуют такие два числа X и Y, что X > Y.
Действие Заменить X на разность X - Y.
Модуль 2
Условие В базе данных имеется число X.
Действие Выдать результат X и остановиться.
Очевидно, что всегда, когда условие Модуля 1 удовлетворяется, удовлетворяется также и условие Модуля 2, и мы имеем конфликт. В нашем случае конфликт можно разрешить при помощи простого управляющего правила: всегда отдавать предпочтение Модулю 1. База данных первоначально содержит числа А и В.
Здесь нас ждет приятный сюрприз: оказывается, что наша программа способна решать более общую задачу, а именно, она может вычислять наибольший общий делитель для любого количества чисел. Если в базу данных загрузить несколько целых чисел, то программа выведет их наибольший общий делитель. На Рисунок 16.3 показана возможная последовательность изменений, которые претерпевает база данных прежде, чем будет получен результат. Обратите внимание на то, что предварительные условия модулей могут удовлетворяться одновременно в нескольких местах базы данных.
Архитектура ориентированная на типовые конфигурации
16. 1. Архитектура, ориентированная на типовые конфигурации
Простой интерпретатор программ управляемых образцами
16. 2. Простой интерпретатор программ, управляемых образцами
Для описания модулей, управляемых образцами, мы применим следующую синтаксическую конструкцию:
ЧастьУсловия ---> ЧастьДействия
Часть условия представляет собой список условий:
[ Условие1, Условие2, Условие3, . . .]
где Условие1, Условие2 и т.д. - обычные прологовские цели. Предварительное условие запуска модуля считается выполненным, если все цели, содержащиеся в списке, достигнуты. Часть действия - это список действий:
[ Действие1, Действие2, . . .]
Каждое отдельное действие - это, как и раньше, прологовская цель. Для того, чтобы выполнить список действий, нужно выполнить все действия из списка. Другими словами, все соответствующие цели должны быть удовлетворены. Среди допустимых действий будут действия, соответствующие манипулированию базой данных: добавить, удалить или заменить те или иные объекты базы данных.
На Рисунок 16.4 показано, как выглядит наша программа вычисления наибольшего общего делителя, записанная в соответствии с введенным нами синтаксисом.
line();% Продукционные правила для нахождения наибольшего общего
% делителя (алгоритм Евклида)
:- ор( 300, fx, число).
[ число X, число Y, X > Y ] --->
[ НовХ is X - Y, заменить( число X, число НовХ) ].
[ число X ] ---> [ write( X), стоп ].
% Начальное состояние базы данных
число 25.
число 10.
число 15.
число 30.
Простая программа для автоматического докаэательства теорем
16. 3. Простая программа для автоматического докаэательства теорем
В настоящем разделе мы реализуем простую программу для автоматического доказательства теорем в виде системы, управляемой образцами. Эта программа будет основана на принципе резолюции - популярном методе, обычно используемом в машинном доказательстве теорем. Мы ограничимся случаем пропозициональной логики, поскольку нашей целью будет дать всего лишь простую иллюстрацию используемого принципа. На самом деле, принцип резолюции можно легко обобщить на случай исчисления высказываний первого порядка (с применением логических формул, содержащих переменные). Базовый Пролог можно рассматривать как частный случай системы доказательства теорем, основанной на принципе резолюции.
Задачу доказательства теорем можно сформулировать так: дана формула, необходимо показать, что эта формула является теоремой, т. е. она верна всегда, независимо от интерпретации встречающихся в ней символов. Например, утверждение, записанное в виде формулы
р v ~ р
и означающее "р или не р", верно всегда, независимо от смысла утверждения р.
Мы будем использовать в качестве операторов следующие символы:
~ отрицание, читается как "не"
& конъюнкцию, читается как "и"
v дизъюнкцию, читается как "или"
=> импликацию, читается как "следует"
Согласно правилам предпочтения операторов, оператор "не" связывает утверждения сильнее, чем "и", "или" и "следует".
Метод резолюции предполагает, что мы рассматриваем отрицание исходной формулы и пытаемся показать, что полученная формула противоречива. Если это действительно так, то исходная формула представляет собой тавтологию. Таким образом, основную идею можно сформулировать так: доказательство противоречивости формулы с отрицанием эквивалентно доказательству того, что исходная формула (без отрицания) есть теорема (т. е. верна всегда). Процесс, приводящий к искомому противоречию, состоит из отдельных шагов, на каждом из которых применяется резолюция.
Давайте проиллюстрируем этот принцип на примере. Предположим, что мы хотим доказать, что теоремой является следующая пропозициональная формула:
(а => b) & (b => с) => (а => с)
Смысл этой формулы таков: если из а следует b и из b следует с, то из а следует с.
Прежде чем начать применять процесс резолюции ("резолюционный процесс"), необходимо представить отрицание нашей формулы в наиболее приспособленной для этого форме. Такой формой является конъюнктивная нормальная форма, имеющая вид
(р1 v p2
v ...) & (q1 v q2
v ...)
& (r1 v r2 v ...) & ...
Здесь рi, qi, ri - элементарные утверждения или их отрицания. Конъюнктивная нормальная форма есть конъюнкция членов, называемых дизъюнктами, например (p1 v p2 v ...) - это дизъюнкт.
Любую пропозициональную формулу нетрудно преобразовать в такую форму. В нашем случае это делается следующим образом. У нас есть исходная формула
(а => b) & (b => с) => (а => с)
Ее отрицание имеет вид
~ ( (а => b) & (b => с) => (а => с) )
Для преобразования этой формулы в конъюнктивную нормальную форму можно использовать следующие известные правила:
(1) х => у
эквивалентно ~х v у
(2) ~(x
v y) эквивалентно ~х & ~у
(3) ~(х
& у) эквивалентно ~х v ~у
(4) ~( ~х) эквивалентно х
Применяя правило 1, получаем
~ ( ~ ( (a => b) & (b => с)) v (а => с) )
Далее, правила 2 и 4 дают
(а => b) & (b => с) & ~(а => с)
Трижды применив правило 1, получаем
(~ а v b) & (~b v с) & ~(~а v с)
И наконец, после применения правила 2 получаем искомую конъюнктивную нормальную форму
(~а v b) & (~b v с) & а & ~с
состоящую из четырех дизъюнктов. Теперь можно приступить к резолюционному процессу.
Элементарный шаг резолюции выполняется всегда, когда имеется два дизъюнкта, в одном из которых встретилось элементарное утверждение р, а в другом - ~р. Пусть этими двумя дизъюнктами будут
р v Y и ~р v Z
Шаг резолюции порождает третий дизъюнкт:
Y v Z
Нетрудно показать, что этот дизъюнкт логически следует из тех двух дизъюнктов, из которых он получен. Таким образом, добавив выражение (Y v Z) к нашей исходной формуле, мы не изменим ее истинности. Резолюционный процесс порождает новые дизъюнкты. Появление "пустого дизъюнкта" (обычно записываемого как "nil") сигнализирует о противоречии. Действительно, пустой дизъюнкт nil порождается двумя дизъюнктами вида
x и ~x
которые явно противоречат друг другу.
Заключительные замечания
16. 4. Заключительные замечания
Нашего простого интерпретатора было вполне достаточно для того, чтобы проиллюстрировать некоторые идеи, лежащие в основе программирования в терминах образцов. Применение этого интерпретатора для более сложных приложений потребовало бы его доработки в целом ряде направлений. Ниже приводится несколько критических замечаний, а также ряд конкретных предложений по усовершенствованию алгоритма интерпретации.
Задача разрешения конфликтов была сведена в нашем интерпретаторе к введению заранее заданного фиксированного порядка рассмотрения модулей. Часто возникает необходимость в более гибких механизмах. Для обеспечения более тонкого управления интерпретацией следует подавать все обнаруженные потенциально активные модули на вход специального управляющего модуля, запрограммированного пользователем.
Когда база данных велика, а программа содержит большое количество модулей, процесс сопоставления с образцами становится крайне неэффективным. Неэффективность можно уменьшить, усложнив организацию базы данных. В частности, можно ввести индексирование информации, записанной в базе данных, или разбить эту информацию на отдельные "подбазы данных", или же разбить все множество модулей на отдельные подмножества. Идея разбиения - в каждый момент дать доступ только к некоторому подмножеству базы данных или набора модулей, ограничив тем самым сопоставление образцов только этим подмножеством. Разумеется, в этом случае механизм управления должен усложниться, поскольку он должен будет обеспечить переход от одних подмножеств к другим с целью их активизации либо деактивизации. Для этого можно применить специальные метаправила.
К сожалению, наш интерпретатор запрограммирован таким образом, что он блокирует механизм автоматических возвратов, так как для манипулирования базой данных он использует процедуры assert и retract. Это положение можно исправить, применив другой способ реализации базы данных, не требующий обращения к этим встроенным процедурам. Например, все состоять базы данных можно представить одним прологовским термом, передаваемым в процедуру пуск в качестве аргумента. Простейший способ реализации этой идеи - организовать этот терм в виде списка объектов базы данных. Тогда верхний уровень базы данных примет вид:
пуск( Состояние) :-
Условие ---> Действие,
проверить( Условие, Состояние),
выполнить( Действие, Состояние).
Задача процедуры выполнить - получить новое состояние базы данных и обратиться к процедуре пуск, подав на ее вход это новое состояние.
Литература
Литература
Waterman and Hayes-Roth (1978) - классическая книга по системам, управляемым образцами. В книге Nilsson (1980) можно найти фундаментальные понятия, относящиеся к задаче автоматического доказательства теорем, включая алгоритм преобразования логических формул в конъюнктивную нормальную форму. Прологовская программа для выполнения этого преобразования приведена в Clocksin and Mellish (1981).
Clocksin F. W. and Mellish С S. (1981). Programming in Prolog. Springer- Verlag. [Имеется перевод: Клоксин У., Мелиш К. Программирование на языке Пролог. - М.: Мир, 1987.]
Nilsson N. J. (1980). Principles of Artificial Intelligence. Tioga; Springer-Verlag.
Waterman D. A. and Hayes-Roth F. (1978, eds). Pattern-Directed Inference Systems. Academic Press.
Проект
Проект
Запрограммируйте интерпретатор, который, в соответствии с приведенным выше замечанием, реализует базу данных как аргумент пусковой процедуры и не использует для этого внутренней базы данных пролог-системы (т. е. обходится без assert и retract). Эта новая версия интерпретатора будет допускать автоматические возвраты. Попытайтесь разработать такое представление базы данных, которое облегчало бы сопоставление с образцами.
хорошо приспособлена для решения многих
Резюме
Архитектура, ориентированная на типовые конфигурации (образцы), хорошо приспособлена для решения многих задач искусственного интеллекта. Программа, управляемая образцами, состоит из модулей, запускаемых при возникновении в базе данных тех или иных конфигураций. Прологовские программы можно рассматривать как частный случай систем, управляемых образцами. Параллельная реализация - наиболее естественный способ реализации систем, управляемых образцами. Реализация на последовательной машине требует разрешения конфликтов между модулями, содержащимися в конфликтном множестве. В этой главе был реализован простой интерпретатор для программ, управляемых образцами. Он был затем применен к задаче автоматического доказательства теорем пропозициональной логики. Были рассмотрены следующие понятия:
системы, управляемые образцами
архитектуры, ориентированные на образцы
программирование в терминах образцов
модули, управляемые образцами
конфликтное множество, разрешение конфликтов
принцип резолюции
автоматическое доказательство теорем на
основе принципа резолюции
Система управляемая типовыми конфигурациями ( образцами)
Рисунок 16. 1. Система, управляемая типовыми конфигурациями ( образцами).

ветствие сразу с несколькими предварительными условиями, а следовательно, в принципе могут запуститься несколько модулей одновременно. В связи с этим, подобную организацию можно рассматривать как естественную модель параллельных вычислений, имея в виду, что каждый модуль физически реализован на отдельном процессоре.
Архитектура, ориентированная на образцы, обладает рядом достоинств. Одно из ее главных преимуществ состоит в том, что, разрабатывая подобную систему, мы не должны тщательно продумывать и заранее определять все связи между модулями. Следовательно, каждый модуль может быть разработан и реализован относительно автономно. Это придает системе высокую степень модульности, проявляющуюся, например, в том, что удаление из системы какого-либо модуля не обязательно приводит к фатальным последствиям. После удаления модуля система во многих случаях сохранит свою способность к решению задач, измениться может только способ их решения. Аналогичное соображение верно и в случае добавления новых модулей или изменения уже существующих. Заметим, что при введении подобных модификаций в традиционные системы потребовалось бы, как минимум, пересмотреть связи между модулями.
Высокая степень модульности особенно желательна в системах со сложными базами знаний, поскольку очень трудно предсказать заранее все возможные взаимодействия между отдельными фрагментами знаний. Архитектура, ориентированная на образцы, обеспечивает простое решение этой проблемы: каждый фрагмент знаний, представленный в виде "если-то"-правила, можно считать отдельным модулем, запускаемым своим собственным образцом.
Перейдем теперь к более детальной проработке нашей базовой схемы для систем, ориентированных на образцы, и рассмотрим вопросы реализации. Как следует из Рисунок 16.1, параллельная реализация была бы для нашей системы наиболее естественным решением. Тем не менее предположим, что нам предстоит реализовать ее на традиционном последовательном процессоре. Тогда если в базе знаний окажется сразу несколько "пусковых" конфигураций, относящихся к нескольким модулям, то возникнет конфликтная ситуация: нам придется принять решение о том, какой из этих потенциально активных модулей будет запущен в действительности. Совокупность всех потенциально активных модулей назовем конфликтным множеством. Очевидно, что реализация схемы Рисунок 16.1 на последовательном процессоре потребует введения в систему дополнительного, управляющего модуля. Задача управляющего модуля - выбрать и активизировать один из модулей конфликтного множества и тем самым разрешить конфликт. Одно из возможных простых правил разрешения конфликта может основываться, например, на предварительном упорядочивании множества модулей системы.
Основной цикл работы системы, ориентированной на образцы, состоит, таким образом, из трех шагов:
(1) Сопоставление с образцами: найти в базе данных все конфигурации, сопоставимые с пусковыми образцами программных модулей. Результат - конфликтное множество.
(2) Разрешение конфликта: выбрать один из модулей, входящих в конфликтное множество.
(3) Выполнение: запустить модуль, выбранный на предыдущем шаге.
Этот принцип реализации показан в виде схемы на Рисунок 16.2.
Основной цикл работы
Рисунок 16. 2. Основной цикл работы системы, управляемой образцами.
В этом примере база данных согласуется с пусковыми образцами
модулей 1, 3 и 4; для выполнения выбран модуль 3.
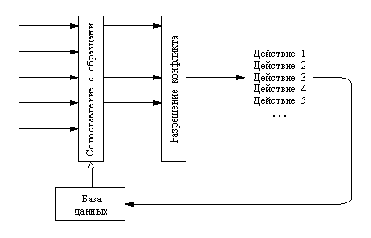
Процесс вычисления
Рисунок 16. 3. Процесс вычисления наибольшего общего делителя
множества чисел. Первоначально база данных содержит числа
25, 10, 15 и 30. Вертикальная стрелка соединяет число с его
"заменителем". Конечное состояние базы данных: 5, 5, 5, 5.

В данной главе мы реализуем интерпретатор простого языка для описания систем, управляемых образцами, и проиллюстрируем на примерах дух программирования в терминах образцов.
Программа управляемая
Рисунок 16. 4. Программа, управляемая образцами, для получения
наибольшего общего делителя множества чисел.
Самый простой способ реализации этого языка - использовать механизмы управления базой данных, встроенные в Пролог. Добавить объект в базу данных или удалить объект из базы данных можно, применяя встроенные процедуры
assert ( Объект) retract( Объект)
Заменить один объект на другой также просто:
заменить( Объект1, Объект2) :-
retract( Объект1), !,
assert( Объект2).
Здесь задача оператора отсечения - не допустить, чтобы оператор retract удалил из базы данных более чем один объект (при возвратах).
line();% Простой интерпретатор для программ, управляемых образцами
% Работа с базой данных производится при помощи процедур
% assert и retract
:- ор( 800, xfx, --->).
пуск :-
Условие ---> Действие,
% правило
проверить( Условие),
% Условие выполнено?
выполнить( Действие).
проверить( [ ]). % Пустое условие
проверить( [Усл | Остальные]) :-
% проверить конъюнкцию
call( Усл),
% условий
проверить( Остальные).
выполнить( [ стоп] ) :- !. % Прекратить выполнение
выполнить( [ ]) :-
% Пустое действие (цикл завершен)
пуск.
% Перейти к следующему циклу
выполнить [Д | Остальные] ) :-
саll( Д),
выполнить( Остальные).
заменить( А, В) :-
% Заменить в базе данных А на В
retract( A), !,
assert( В).
Простой интерпретатор для программ управляемых образцами
Рисунок 16. 5. Простой интерпретатор для программ, управляемых образцами.
Простой интерпретатор для программ, управляемых образцами, показан на Рисунок 16.5. Следует признать, что в интерпретаторе допущены значительные упрощения. Так, например, в него заложено чрезвычайно простое и жесткое правило разрешения конфликтов: всегда запускать первый из потенциально активных модулей (в соответствии с тем порядком, в котором модули записаны в программе). Таким образом, программисту предоставлено единственное средство управления процессом интерпретации - он может указать тот или иной порядок следования модулей. Начальное состояние базы данных задается в виде прологовских предложений, записанных в исходной программе. Запуск программы производится при помощи вопроса
?- пуск.
Доказательство теоремы
Рисунок 16. 6. Доказательство теоремы (а=>b)&(b=>с)=>(a=>с) методом
резолюции. Верхняя строка - отрицание теоремы в конъюнктивной
нормальной форме. Пустой дизъюнкт внизу сигнализирует, что
отрицание теоремы противоречиво.
На Рисунок 16.6 показан процесс применения резолюций, начинающийся с отрицания нашей предполагаемой теоремы и заканчивающийся пустым дизъюнктом.
На Рисунок 16.7 мы видим, как резолюционный процесс можно сформулировать в форме программы, управляемой образцами. Программа работает с дизъюнктами, записанными в базе данных. В терминах образцов принцип резолюции формулируется следующим образом:
если
существуют два таких дизъюнкта С1 и С2, что
P является (дизъюнктивным) подвыражением С1,
а ~Р - подвыражением С2
то
удалить Р из С1 (результат - СА), удалить ~Р
из С2 (результат - СВ) и добавить в базу
данных новый дизъюнкт СА v СВ.
На нашем формальном языке это можно записать так:
[ дизъюнкт( С1), удалить( Р, Cl, CA),
дизъюнкт( С2), удалить( ~Р, С2, СВ) ] --->
[ assert( дизъюнкт( СА v СВ) ) ].
Это правило нуждается в небольшой доработке. Дело в том, что мы не должны допускать повторных взаимодействий между дизъюнктами, так как они порождают новые копии уже существующих формул. Для этого в программе Рисунок 16.7 предусматривается запись в базу данных информации об уже произведенных взаимодействиях в форме утверждений вида
сделано( Cl, C2, Р)
В условных частях правил производится распознавание подобных утверждений и обход соответствующих повторных действий.
Правила, показанные на Рисунок 16.7, предусматривают также обработку специальных случаев, в которых требуется избежать явного представления пустого дизъюнкта. Кроме того, имеются два правила для упрощения дизъюнктов. Одно из них убирает избыточные подвыражения. Например, это правило превращает выражение
a v b v a
в более простое выражение a v b. Другое правило распознает те дизъюнкты, которые всегда истинны, например,
a v b v ~а
и удаляет их из базы данных, поскольку они бесполезны при поиске противоречия.
line();% Продукционные правила для задачи автоматического
% доказательства теорем
% Противоречие
[ дизъюнкт( X), дизъзюнкт( ~Х) ] --->
[ write( 'Обнаружено противоречие'), стоп].
% Удалить тривиально истинный дизъюнкт
[ дизъюнкт( С), внутри( Р, С), внутри( ~Р, С) ] --->
[ retract( С) ].
% Упростить дизъюнкт
[ дизъюнкт( С), удалить( Р, С, С1), внутри( Р, С1) ] --->
[ заменить( дизъюнкт( С), дизъюнкт( С1) ) ].
% Шаг резолюции, специальный случай
[ дизъюнкт( Р), дизъюнкт( С), удалить( ~Р, С, С1),
not сделано( Р, С, Р) ] --->
[ аssеrt( дизъюнкт( С1)), аssert( сделано( Р, С, Р))].
% Шаг резолюции, специальный случай
[ дизъюнкт( ~Р), дизъюнкт( С), удалить( Р, С, С1),
not сделано( ~Р, С, Р) ] --->
[ assert( дизъюнкт( C1)), аssert( сделано( ~Р, С, Р))].
% Шаг резолюции, общий случай
[ дизъюнкт( С1), удалить( Р, С1, СА),
дизъюнкт( С2), удалить( ~Р, С2, СВ),
not сделано( Cl, C2, Р) ] --->
[ assert( дизъюнкт( СА v СВ) ),
assert( сделано( Cl, C2, Р) ) ].
% Последнее правило: тупик
[ ] ---> [ write( 'Нет противоречия'), стоп ].
% удалить( Р, Е, Е1) означает, получить из выражения Е
% выражение Е1, удалив из него подвыражение Р
удалить( X, X v Y, Y).
удалить( X, Y v X, Y).
удалить( X, Y v Z, Y v Z1) :-
удалить( X, Z, Z1).
удалить( X, Y v Z, Y1 v Z) :-
удалить( X, Y, Y1).
% внутри( Р, Е) означает Р есть дизъюнктивное подвыражение
% выражения Е
внутри( X, X).
внутри( X, Y) :-
удалить( X, Y, _ ).
Программа управляемая образцами для автоматического доказательства теорем
Рисунок 16. 7. Программа, управляемая образцами, для
автоматического доказательства теорем.
Остается еще один вопрос: как преобразовать заданную пропозициональную формулу в конъюнктивную нормальную форму? Это несложное преобразование выполняется с помощью программы, показанной на Рисунок 16.8. Процедура
транс( Формула)
транслирует заданную формулу в множество дизъюнктов Cl, C2 и т.д. и записывает их при помощи assert в базу данных в виде утверждений
дизъюнкт( С1).
дизъюнкт( С2).
. . .
Программа, управляемая образцами, для автоматического доказательства теорем запускается при помощи цели пуск. Таким образом, для того чтобы доказать при помощи этой программы некоторую теорему, мы транслируем ее отрицание в конъюнктивную нормальную форму, а затем запускаем резолюционный процесс. В нашем примере это можно сделать так:
line();% Преобразование пропозициональной формулы в множество
% дизъюнктов с записью их в базу данных при помощи assert
:- ор( 100, fy, ~).
% Отрицание
:- ор( 110, xfy, &).
% Конъюнкция
:- ор( 120, xfy, v).
% Дизъюнкция
:- ор( 130, xfy, =>).
% Импликация
транс( F & G) :- !,
% Транслировать конъюнктивную формулу
транс( F),
транс( G).
транс( Формула) :-
тр( Формула, НовФ), !,
% Шаг трансформации
транс( НовФ).
транс( Формула) :-
% Дальнейшая трансформация невозможна
assert( дизъюнкт( Формула) ).
% Правила трансформаций для пропозициональных формул
тр( ~( ~Х), X) :- !. % Двойное отрицание
тр( X => Y, ~Х v Y) :- !. % Устранение импликации
тр( ~( X & Y), ~Х v ~Y) :- !. % Закон де Моргана
тр( ~( X v Y), ~Х & ~Y) :- !. % Закон де Моргана
тр( X & Y v Z, (X v Z) & (Y v Z) ) :- !.
% Распределительный закон
тр( X v Y & Z, (X v Y) & (X v Z) ) :- !.
% Распределительный закон
тр( X v Y, X1 v Y) :-
% Трансформация подвыражения
тр( X, X1), !.
тр( X v Y, X v Y1) :-
% Трансформация подвыражения
тр( Y, Y1), !.
тр( ~Х, ~Х1) :-
% Трансформация подвыражения
тр( X, X1).
Преобразование пропозициональных
Рисунок 16. 8. Преобразование пропозициональных формул в множество
дизъюнктов с записью их в базу данных при помощи assert.
?- транс( ~(( а=>b) & ( b=>c) => ( а=>с)) ), пуск.
Ответ программы "Обнаружено противоречие" будет означать, что исходная формула является теоремой.
