Минимаксный принцип
Для игр, представляющих интерес, полный просмотр игрового дерева невозможен, поэтому были разработаны другие методы, предусматривающие просмотр только части дерева игры. Среди этих методов существует страндартный метод поиска, используемый в игровых (особенно в шахматных) программах и основанный на минимаксном принципе. Дерево игры просматривается только вплоть до некоторой глубины (обычно на несколько ходов), а затем для всех концевых вершин дерева поиска вычисляются оценки при помощи некоторой оценочной функции. Идея состоит в том, чтобы, получив оценки этих терминальных поисковых вершин, не продвигаться дальше и получить тем самым экономию времени. Далее, оценки терминальных позиций распространяются вверх по дереву поиска в соответствии с минимаксным принципом. В результате все вершины дерева поиска получают свои оценки. И наконец, игровая программа, участвующая в некоторой реальной игре, делает свой ход - ход, ведущий из исходной (корневой) позиции в наиболее перспективного (с точки зрения оценки) ее преемника.
Обратите внимание на то, что мы здесь делаем определенное различие между "деревом игры" и "деревом поиска". Дерево поиска - это только часть дерева игры (его верхняя часть), т. е. та его часть, которая была явным образом порождена в процессе поиска. Таким образом, терминальные поисковые позиции совсем не обязательно должны совпадать с терминальными позициями самой игры.
Очень многое зависит от оценочной функции, которая для большинства игр, представляющих интерес, является приближенной эвристической оценкой шансов на выигрыш одного из участников игры. Чем выше оценка, тем больше у него шансов выиграть и чем ниже оценка, тем больше шансов на выигрыш у его противника. Поскольку один из участников игры всегда стремится к высоким оценкам, а другой - к низким, мы дадим им имена МАКС и МИН соответственно. МАКС всегда выбирает ход с максимальной оценкой; в противоположность ему МИН всегда выбирает ход с минимальной оценкой. Пользуясь этим принципом (минимаксным
принципом) и зная значения оценок для всех вершин "подножья" дерева поиска, можно определить оценки всех остальных вершин дерева.
На рис. 15. 2 показано, как это делается. На этом рисунке видно, что уровни позиций с ходом МАКС'а чередуются с уровнями позиций с ходом МИН'а. Оценки вершин нижнего уровня определяются при помощи оценочной функции. Оценки всех внутренних вершин можно определить, двигаясь снизу вверх от уровня к уровню, пока мы не достигнем корневой вершины. В результате, как видно из рис. 15.2, оценка корня оказывается равной 4, и, соответственно, лучшим ходом МАКС'а из позиции а - a-b. Лучший ответ МИН'а на этот ход - b-d, и т.д. Эту последовательность ходов называют также основным вариантом. Основной вариант показывает, какова "минимаксно-оптимальная" игра для обоих участников. Обратите внимание на то, что оценки всех позиций, входящих в основной вариант, совпадают.

Рис. 15. 2. Статические (нижний уровень) и минимаксные рабочие
оценки вершин дерева поиска. Выделенные ходы образуют основной
вариант, т. е. минимаксно-оптимальную игру с обеих сторон.
Мы различаем два вида оценок: оценки вершин нижнего уровня и оценки внутренних вершин (рабочие оценки). Первые из них называются также "статическими", так как они вычисляются при помощи "статической" оценочной функции, в противоположность рабочим оценкам, получаемым "динамически" при распространении статических оценок вверх по дереву.
Правила распространения оценок можно сформулировать следующим образом. Будем обозначать статическую оценку позиции Р через v( P), а ее рабочую оценку - через V( Р). Пусть Р1, ..., Рn - разрешенные преемники позиции Р. Тогда соотношения между статическими и рабочими оценками можно записать так:
V( Р) = v( P)
если Р - терминальная позиция дерева поиска (n=0)
V( Р) = max V( Рi )
i
если P - позиция с ходом МАКС'а
V( Р) = min V( Рi )
i
если Р - позиция с ходом МИН'а
line(); % Минимаксная процедура: минимакс( Поз, ЛучшПоз, Оц)
% Поз - позиция, Оц - ее минимаксная оценка;
% лучший ход из Поз ведет в позицию ЛучшПоз
минимакс( Поз, ЛучшПоз, Оц) :-
ходы( Поз, СписПоз), !,
% СписПоз - список разрешенных ходов
лучш( СписПоз, ЛучшПоз, Оц);
стат_оц( Поз, Оц). % Поз не имеет преемников
лучш( [Поз], Поз, Оц) :-
минимакс( Поз, _, Оц), !.
лучш( [Поз1 | СписПоз], ЛучшПоз, ЛучшОц) :-
минимакс( Поз1, _, Оц1),
лучш( СписПоз, Поз2, Оц2),
выбор( Поз1, Оц1, Поз2, Оц2, ЛучшПоз, ЛучшОц).
выбор( Поз0, Оц0, Поз1, Оц1, Поз0, Оц0) :-
ход_мина( Поз0), Оц > Оц1, !;
ход_макса( Поз0), Оц < Оц1, !.
выбор( Поз0, Оц0, Поз1, Оц1, Поз1, Оц1).
line(); Рис. 15. 3. Упрощенная реализация минимаксного принципа.
Программа на Прологе, вычисляющая минимаксную рабочую оценку для некоторой заданной позиции, показана на рис. 15.3. Основное отношение этой программы -
минимакс( Поз, ЛучшПоз, Оц)
где Оц - минимаксная оценка позиции Поз, а ЛучшПоз - наилучшая позиция-преемник позиции Поз (лучший ход, позволяющий достигнуть оценки Оц). Отношение
ходы( Поз, СписПоз)
задает разрешенные ходы игры: СписПоз - это список разрешенных позиций-преемников позиции Поз. Предполагается, что цель ходы имеет неуспех, если Поз является терминальной поисковой позицией (листом дерева поиска). Отношение
лучш( СписПоз, ЛучшПоз, ЛучшОц)
выбирает из списка позиций-кандидатов СписПоз "наилучшую" позицию ЛучшПоз. ЛучшОц - оценка позиции ЛучшПоз, а следовательно, и позиции Поз. Под "наилучшей" оценкой мы понимаем либо максимальную, либо минимальную оценку, в зависимости от того, с чьей стороны ожидается ход.
Назад | Содержание | Вперёд
Модель Prospector'а
Достоверность событий моделируется с помощью действительных чисел, заключенных в интервале между 0 и 1. Для простоты изложения мы будем называть их "вероятностями", хотя более точный термин "субъективная уверенность". Отношения между событиями можно представить графически в форме "сети вывода". На рис. 14.14 показан пример сети вывода. События изображаются прямоугольниками, а отношения между ними - стрелками. Овалами изображены комбинации событий (И, ИЛИ, НЕ).
Мы будем считать, что отношения между событиями (стрелки) являются своего рода "мягкими импликациями". Пусть имеются два события E и H, и пусть информация о том, что имело место событие Е, оказывает влияние на нашу уверенность в том, что произошло событие H. Если это влияние является "категорической импликацией", то можно просто написать
если Е то H
В случае же "мягкой импликации" это отношение может быть менее определенным, так что ему можно приписать некоторую "силу", с которой оно действует:
если E то H с силой S
Та сила, с которой достоверность Е влияет на уверенность в H, моделируется в системе Prospector при помощи двух параметров:
N = "коэффициент необходимости"
S = "коэффициент достаточности"

Рис. 14. 14. Сеть вывода системы AL/X (заимствовано
из Reiter (1980) ).
Числа, приписанные прямоугольникам, - априорные
вероятности событий; числами на стрелках задается
"сила" отношений между событиями.
В сети вывода это изображается так:
E ------------> H
(N, S)
Два события, участвующие в отношении, часто называют "фактом" и "гипотезой" соответственно. Допустим, что мы проверяем гипотезу H. Тогда мы будем искать такой факт Е, который мог бы подтвердить либо опровергнуть эту гипотезу. S говорит нам, в какой степени достаточно факта Е для подтверждения гипотезы H; N - насколько необходим факт Е для подтверждения гипотезы Н. Если факт Е имел место, то чем больше S, тем больше уверенности в H. С другой стороны, если не верно, что имел место факт Е, то чем больше N, тем менее вероятно, что гипотеза H верна. В случае, когда степень достоверности Е находится где-то между полной достоверностью и невозможностью, степень достоверности H определяется при помощи интерполяции между двумя крайними случаями. Крайние случаи таковы:
(1) известно, что факта Е не было
(2) известно, что факт Е имел место
(3) ничего не известно относительно Е
Для каждого события H сети вывода существует априорная вероятность р0(Н) (безусловная) вероятность события H в состоянии, когда неизвестно ни одного положительного или отрицательного факта. Если становится известным какой-нибудь факт E, то вероятность H меняет свое значение с р0(Н) на р(Н | Е). Величина изменения зависит от "силы" стрелки, ведущей из E в H. Итак, мы начинаем проверку гипотез, принимая их априорные вероятности. В дальнейшем происходит накопление информации о фактах, что находит свое отражение в изменении вероятностей событий сети. Эти изменения распространяются по сети от события к событию в соответствии со связями между событиями.
Например, рассмотрим рис. 14.14 и предположим, что получена информация о срабатывании индикатора открытия выпускного клапана. Эта информация повлияет на нашу уверенность в том, что выпускной клапан открылся, что, в свою очередь, повлияет на уверенность в том, что сместилась установка порогового давления.
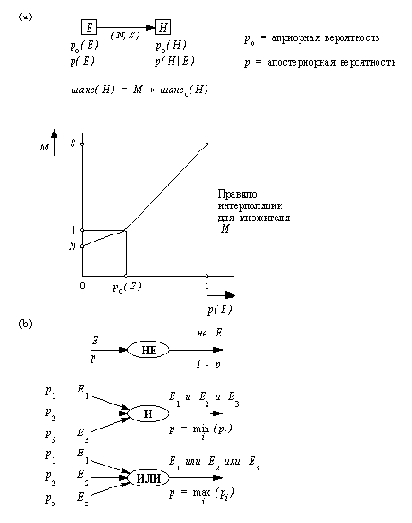
Рис. 14. 15. Правила распространения вероятностей по сети,
принятые в системах Prospector и AL/X: (а) "мягкая импликация"
с силой (N, S); (b) логические комбинации отношений.
На рис. 14.15 показан один из способов реализации этого эффекта распространения информации по сети. Часть вычислений производится не над вероятностями, а над шансами. Это удобно, хотя в принципе и не обязательно. Между шансами и вероятностями имеет место простое соотношение:
шанс = вер / ( 1 - вер)
вер = шанс / ( 1 + шанс)
Пусть между E и H существует отношение "мягкой импликации", тогда, в соответствии с рис. 14.15,
шанс (Н | Е) = М * шанс (H)
где множитель М определяется априорной и апостериорной вероятностями с учетом силы ( N, S) связи между E и H. Предполагается, что правила Prospector'a (рис. 14.15) для вычисления вероятностей логических комбинаций событий (использующие min и max) правильно моделируют поведение человека при оценке субъективной уверенности в таких составных событиях.
Моделирование недетерминированного автомата
Данное упражнение показывает, как абстрактную математическую конструкцию можно представить на Прологе. Кроме того, программа, которая получится, окажется значительно более гибкой, чем предполагалось вначале.
Недетерминированный конечный автомат - это абстрактная машина, которая читает символы из входной цепочки и решает, допустить или отвергнуть эту цепочку. Автомат имеет несколько состояний и всегда находится в одном из них. Он может изменить состояние, перейдя из одного состояния в другое. Внутреннюю структуру такого автомата можно представить графом переходов, как показано на рис. 4.3. В этом примере S1, S2, S3 и S4 - состояния автомата. Стартовав из начального состояния (в нашем примере это S1 ), автомат переходит из состояния в состояние по мере чтения входной цепочки. Переход зависит от текущего входного символа, как указывают метки на дугах графа переходов.

Рис. 4. 3. Пример недетерминированного конечного автомата.
Переход выполняется всякий раз при чтении входного символа. Заметим, что переходы могут быть недетерминированными. На рис. 4.3 видно, что если автомат находится в состоянии S1, и текущий входной символ равен а, то переход может осуществиться как в S1, так и в S2. Некоторые дуги помечены меткой пусто, обозначающей "пустой символ". Эти дуги соответствуют "спонтанным переходам" автомата. Такой переход называется спонтанным, потому что он выполняется без чтения входной цепочки. Наблюдатель, рассматривающий автомат как черный ящик, не сможет обнаружить, что произошел какой-либо переход.
Состояние S3 обведено двойной линией, это означает, что S3 - конечное состояние. Про автомат говорят, что он допускает входную цепочку, если в графе переходов существует путь, такой, что:
(1) он начинается в начальном состоянии,
(2) он оканчивается в конечном состоянии, и
(3) метки дуг, образующих этот путь, соответствуют полной входной цепочке.
спонтанный( S3, S1).
Представим входные цепочки в виде списков Пролога. Цепочка ааb будет представлена как [а, а, b]. Модель автомата, получив его описание, будет обрабатывать заданную входную цепочку, и решать, допускать ее или нет. По определению, недетерминированный автомат допускает заданную цепочку, если (начав из начального состояния) после ее прочтения он способен оказаться в конечном состоянии. Модель программируется в виде бинарного отношения допускается, которое определяет принятие цепочки из данного состояния. Так
допускается( Состояние, Цепочка)
истинно, если автомат, начав из состояния Состояние как из начального, допускает цепочку Цепочка. Отношение допускается можно определить при помощи трех предложений. Они соответствуют следующим трем случаям:
(1) Пустая цепочка [ ] допускается из состояния S, если S - конечное состояние.
(2) Непустая цепочка допускается из состояния S, если после чтения первого ее символа автомат может перейти в состояние S1, и оставшаяся часть цепочки допускается из S1. Этот случай иллюстрируется на рис. 4.4(а).
(3) Цепочка допускается из состояния S, если автомат может сделать спонтанный переход из S в S1, а затем допустить (всю) входную цепочку из S1. Такой случай иллюстрируется на рис. 4.4(b).
Эти правила можно перевести на Пролог следующим образом:
допускается( S, [ ]) :-
% Допуск пустой цепочки
конечное( S).
допускается( S, [X | Остальные]) :-
% Допуск чтением первого символа
переход( S, X, S1),
допускается( S1, Остальные).
допускается( S, Цепочка) :-
% Допуск выполнением спонтанного перехода
спонтанный( S, S1),
допускается( S1, Цепочка).
Спросить о том, допускается ли цепочка аааb, можно так:
?- допускается( S1, [a, a, a, b]).
yes (да)
Как мы уже видели, программы на Прологе часто оказываются способными решать более общие задачи, чем те, для которых они первоначально предназначались. В нашем случае мы можем спросить модель также о том, в каком состоянии должен находиться автомат в начале работы, чтобы он допустил цепочку аb:
?- допускается( S, [a, b]).
S = s1;
S = s3
Как ни странно, мы можем спросить также "Каковы все цепочки длины 3, допустимые из состояния s1?"
?- допускается( s1, [XI, Х2, X3]).
X1 = а
Х2 = а
Х3 = b;
X1 = b
Х2 = а
Х3 = b;
nо (нет)
Если мы предпочитаем, чтобы допустимые цепочки выдавались в виде списков, тогда наш вопрос следует сформулировать так:
?- Цепочка = [ _, _, _ ], допускается( s1, Цепочка).
Цепочка = [а, а, b];
Цепочка = [b, а, b];
nо (нет)
Можно проделать и еще некоторые эксперименты, например спросить: "Из какого состояния автомат допустит цепочку длиной 7?"
Эксперименты могут включать в себя переделки структуры автомата, вносящие изменения в отношения конечное, переход и спонтанный. В автомате, изображенном на рис. 4.3, отсутствуют циклические "спонтанные пути" (пути, состоящие только из спонтанных переходов). Если на рис. 4.3 добавить новый переход
спонтанный( s1, s3)
то получится "спонтанный цикл". Теперь наша модель может столкнуться с неприятностями. Например, вопрос
?- допускается( s1, [а]).
приведет к тому, что модель будет бесконечно переходить в состояние s1, все время надеясь отыскать какой-либо путь в конечное состояние.
Некоторые операции над списками
Списки можно применять для представления множеств, хотя и существует некоторое различие между этими понятиями: порядок элементов множества не существенен, в то время как для списка этот порядок имеет значение; кроме того, один н тот же объект может встретиться в списке несколько раз. Однако наиболее часто используемые операции над списками аналогичны операциям над множествами. Среди них проверка, является ли некоторый объект элементом списка, что соответствует проверке объекта на принадлежность множеству; конкатенация (сцепление) двух списков, что соответствует объединению множеств; добавление нового объекта в список или удаление некоторого объекта из него.
В оставшейся части раздела мы покажем программы, реализующие эти и некоторые другие операции над списками.
Некоторые правила хорошего стиля
Предложения программы должны быть короткими. Их тела, как правило, должны содержать только несколько целей. Процедуры должны быть короткими, поскольку длинные процедуры трудны для понимания. Тем не менее длинные процедуры вполне допустимы в том случае, когда они имеют регулярную структуру (этот вопрос еще будет обсуждаться в данной главе). Следует применять мнемонические имена процедур и переменных. Они должны отражать смысл отношений и роль объектов данных. Существенное значение имеет расположение текста программы. Для улучшения читабельности программы нужно постоянно применять пробелы, пустые строки и отступы. Предложения, относящиеся к одной процедуре, следует размещать вместе в виде отдельной группы строк; между предложениями нужно вставлять пустую строку (этого не нужно делать, возможно, только в случае перечисления большого количества фактов, касающихся одного отношения); каждую цель можно размещать на отдельной строке. Пролог-программы иной раз напоминают стихи по эстетической привлекательности своих идей и формы. Стилистические соглашения такого рода могут варьироваться от программы к программе, так как они зависят от задачи и от личного вкуса. Важно, однако, чтобы на протяжении одной программы постоянно применялись одни и те же соглашения. Оператор отсечения следует применять с осторожностью. Если легко можно обойтись без него - не пользуйтесь им. Всегда, когда это возможно, предпочтение следует отдавать "зеленым отсечениям" перед "красными". Как говорилось в гл. 5, отсечение называется "зеленым", если его можно убрать, на затрагивая декларативный смысл предложения. Использование "красных отсечений" должно ограничиваться четко определенными конструкциями, такими как оператор not или конструкция выбора между альтернативами. Примером последней может служить
если Условие то Цель1 иначе Цель2
С использованием отсечения эта конструкция переводится на Пролог так:
Условие, !. % Условие выполнено?
Цель1; % Если да, то Цель1
Цель2 % Иначе - Цель2
Из-за того, что оператор not связан с отсечением, он тоже может привести к неожиданностям. Поэтому, применяя его, следует всегда помнить точное прологовское определение этого оператора. Тем не менее, если приходится выбирать между not и отсечением, то лучше использовать not, чем какую-нибудь туманную конструкцию с отсечением. Внесение изменений в программу при помощи assert и retract может сделать поведение программы значительно менее понятным. В частности, одна и та же программа на одни н те же вопросы будет отвечать по-разному в разные моменты времени. В таких случаях, если мы захотим повторно воспроизвести исходное поведение программы, нам придется предварительно убедиться в том, что ее исходное состояние, нарушенное при обращении к assert и retract, полностью восстановлено. Применение точек с запятой может затемнять смысл предложений. Читабельность можно иногда улучшить, разбивая предложения, содержащие точки с запятой, на несколько новых предложений, однако за это, возможно, придется заплатить увеличенном длины программы и потерей в ее эффективности. Для иллюстрации некоторых положений данного раздела рассмотрим отношение
слить( Спис1, Спис2, Спис3)
где Спис1 и Спис2 - упорядоченные списки, а Спис3 -результат их слияния (тоже упорядоченный). Например:
слить( [2, 4, 7], [1, 3, 4, 8], [1, 2, 3, 4, 4, 7, 8] )
Вот стилистически неудачная реализация этого отношения:
слить( Спис1, Спис2, Спис3) :-
Спис1 = [ ], !, Спис3 = Спис2;
% Первый список пуст
Спис2 = [ ], !, Спис3 = Спис1;
% Второй список пуст
Спис1 = [X | Остальные],
Спис2 = [Y | Остальные],
( Х < Y, !,
Z = X, % Z - голова Спис3
слить( Остальные1, Спис2, Остальные3 );
Z = Y,
слить( Спис1, Остальные2, Остальные3 ) ),
Спис3 = [Z | Остальные3].
Вот более предпочтительный вариант, не использующий точек с запятой:
слить( [ ], Спис, Спис).
слить( Спис, [ ], Спис).
слить( [X | Остальные1], [Y | Остальные2], [X | Остальные3] ) :-
Х < Y, !,
слить(Остальные1, [Y | Остальные2], Остальные3).
слить( Спис1, [Y | Остальные2], [Y | Остальные3]): -
слить( Спис1, Остальные2, Остальные3 ).
Некто_имеет_ребенка :- родитель( X, Y)
Однако оно имеет совершенно другой смысл, нежели
некто_имеет_ребенка :- родитель( X, X).
Если анонимная переменная встречается в вопросе, то ее значение не выводится при ответе системы на этот вопрос. Если нас интересуют люди, имеющие детей, но не имена этих детей, мы можем просто спросить:
Объекты данных
На рис. 2.1 приведена классификация объектов данных Пролога. Пролог-система распознает тип объекта по его синтаксической форме в тексте программы. Это возможно благодаря тому, что синтаксис Пролога
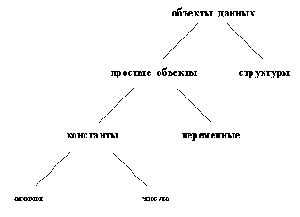
Рис. 2. 1. Обьекты данных Пролога.
предписывает различные формы записи для различных типов объектов данных. В гл. 1 мы уже видели способ, с помощью которого можно отличить атомы от переменных: переменные начинаются с прописной буквы, тогда как атомы - со строчной. Для того, чтобы пролог-система распознала тип объекта, ей не требуется сообщать больше никакой дополнительной информации (такой, например, как объявление типа данных).
Обобщение
Часто бывает полезно обобщить исходную задачу таким образом, чтобы полученная более общая задача допускала рекурсивную формулировку. Исходная задача решается, тогда как частный случай ее более общего варианта. Обобщение отношения обычно требует введения одного или более дополнительных аргументов. Главная проблема состоит в отыскании подходящего обобщения, что может потребовать более тщательного изучения задачи. В качестве примера рассмотрим еще раз задачу о восьми ферзях. Исходная задача состояла в следующем: разместить на доске восемь ферзей так, чтобы обеспечить отсутствие взаимных нападений. Соответствующее отношение назовем
восемьферзей( Поз)
Оно выполняется (истинно), если Поз - представленная тем или иным способом позиция, удовлетворяющая условию задачи. Можно предложить следующую полезную идею: обобщить задачу, перейдя от 8 ферзей к произвольному количеству - N. Количество ферзей станет дополнительным аргументом:
n_ферзей( Поз, N)
Преимущество такого обобщения состоит в том, что отношение n_ферзей допускает непосредственную рекурсивную формулировку:
(1) Граничный случай: N = 0
Разместить 0 ферзей - тривиальная задача.
(2) Общий случай: N > 0
Для "безопасного" размещения N ферзей необходимо:
Как только мы научимся решать более общую задачу, решить исходную уже не составит труда:
восемьферзей( Поз) :- n_ферзей( Поз, 8)
Обработка произвольного файла термов
Типичная последовательность целей для обработки файла F от начала до конца будет выглядеть примерно так:
. . . , see( F), обработкафайла, sеe( user), . . .
Здесь обработкафайла - процедура, которая читает и обрабатывает последовательно каждый терм файла F один за другим до тех пор, пока не встретится конец файла. Приведем типичную схему для процедуры
обработкафайла:
обработкафайла :-
read( Терм),
обработка( Терм).
обработка( end_of_file) :- !.
% Все сделано
обработка( Терм) :-
обраб( Терм),
% Обработать текущий элемент
обработкафайла.
% Обработать оставшуюся часть файла
Здесь обраб( Терм) представляет процедуру обработки отдельного терма.
В качестве примера такой обработки рассмотрим процедуру, которая выдает на терминал каждый терм вместе с его порядковым номером. Назовем эту процедуру показфайла. У нее должен быть дополнительный аргумент для подсчета прочитанных термов:
показфайла( N) :-
read( Терм),
показ( Терм, N).
показ( Терм, N) :- !
write( N), tab( 2), write( Терм),
Nl is N + 1,
показфайла( Nl).
Вот другой пример программы обработки файлов, построенной по подобной схеме. Пусть есть файл с именем файл1, термы которого имеют форму
изделие( НомерИзд, Описание, Цена, ИмяПоставщика)
Каждый терм описывает одну строку каталога изделий. Нужно построить новый файл. содержащий только те изделия, которые выпускаются каким-то конкретным поставщиком. Поскольку поставщик в этом новом файле у всех изделий будет одинаков, его имя нужно записать только один раз в самом начале и убрать из всех остальных термов. Процедура будет называться
создатьфайл( Поставщик)
Например, если исходный каталог хранится в файле файл1, а мы хотим создать специальный каталог в файле файл2, содержащий всю информацию о том, что поставляет Гаррисон, тогда мы применим процедуру создатьфайл
следующим образом:
?- seе( файл1), tеll( файл2), создатьфайл( гаррисон),
see( user), tell( user).
Процедуру создатьфайл можно определить так:
создатьфайл( Поставщик) :-
write( Поставщик), write( '.'), nl,
создатьостальное( Поставщик).
создатьостальное( Поставщик) :-
read( Изделие),
обработать( Изделие, Поставщик).
обработать( end_ot_file) :- !.
обработать( Изделие( Ном, Опис, Цена, Поставщик),
Поставщик) :- !,
write( Изделие( Ном, Опис, Цена) ),
write( '.'), nl,
создатьостальное( Поставщик).
обработать ( _, Поставщик) :-
создатьостальное( Поставщик).
Обратите внимание на то, что обработать
вписывает точки между термами, чтобы впоследствии файл мог быть прочитан процедурой read.
Обработка символов
Символ записывается в текущий выходной поток при помощи цели
put( С)
где С - символ, который нужно вывести, в кодировке ASCII (число от 0 до 127), например, вопрос
?- put( 65), put( 66), put( 67).
породит следующий вывод:
АВС
65 - ASCII-код 'А', 66 - 'В', 67 - 'С'.
Одиночный символ можно считать из текущего входного потока при помощи цели
get0( С)
Она вызывает чтение символа из входного потока, и переменная С конкретизируется ASCII-кодом этого символа. Вариантом предиката get0 является get, который используется для чтения символов, отличных от пробела. Поэтому цель
get( С)
вызовет пропуск всех непечатаемых символов (в частности пробелов) от текущей позиции во входном потоке до первого печатаемого символа. Этот символ затем тоже считывается и С конкретизируется его ASCII-кодом.
В качестве примера использования предикатов, переносящих одиночные символы, давайте рассмотрим процедуру сжатие, выполняющую следующую работу: считывание из входного потока произвольного предложения и вывод его же, но в форматированном виде - все группы идущих подряд пробелов заменены на одиночные пробелы. Для простоты будем считать, что все предложения входного потока, обрабатываемые процедурой сжатие, оканчиваются точками, а слова в них отделены одно от другого одним или несколькими пробелами, и только ими. Тогда следующее предложение будет допустимым:
Робот пытался налить вина из бутылки.
Цель сжатие выведет его в таком виде:
Робот пытался налить вина из бутылки.
Процедура сжатие будет иметь такую же структуру, как и процедуры обработки файлов из предыдущего раздела. Сначала она прочтет первый символ, выведет его, а затем завершит обработку, в зависимости от того, каким был этот символ.
Есть три альтернативы, которые соответствуют следующим случаям: символ является точкой, пробелом или буквой. Взаимное исключение этих трех альтернатив обеспечивается в программе отсечениями:
сжатие :-
get0( С),
put( С).
сделатьостальное( С).
сделатьостальное( 46) :- !.
% 46 -АSСII-код точки, Все сделано
сделатьостальное( 32) :- !,
% 32 - ASCII-код пробела
get( С),
put( С),
сделатьостальное( С).
сделатьостальное( Буква) :-
сжатие.
Общие принципы хорошего программирования
Главный вопрос, касающийся хорошего программирования, - это вопрос о том, что такое хорошая программа. Ответ на этот вопрос не тривиален, поскольку существуют разные критерии качества программ.
Следующие критерии общеприняты: Правильность. Хорошая программа в первую очередь должна быть правильной, т. е. она должна делать именно то, для чего предназначалась. Это требование может показаться тривиальным и самоочевидным. Однако в случае сложных программ правильность достигается не так часто. Распространенной ошибкой при написании программ является пренебрежение этим очевидным критерием, когда большее внимание уделяется другим критериям - таким, как эффективность. Эффективность. Хорошая программа не должна попусту тратить компьютерное время и память. Простота, читабельность. Хорошая, программа должна быть легка для чтения и понимания. Она не должна быть более сложной, чем это необходимо. Следует избегать хитроумных программистских трюков, затемняющих смысл программы. Общая организация программы и расположение ее текста должны облегчать ее понимание. Удобство модификации. Хорошая программа должна быть легко модифицируема и расширяема. Простота и модульная организация программы облегчают внесение в нее изменений. Живучесть. Хорошая программа должна быть живучей. Она не должна сразу "ломаться", если пользователь введет в нее неправильные или непредусмотренные данные. В случае подобных ошибок программа должна сохранять работоспособность и вести себя разумно (сообщать об ошибках). Документированность. Хорошая программа должна быть хорошо документирована. Минимальная документация - листинг с достаточно подробными комментариями.
Степень важности того или иного критерия зависит от конкретной задачи, от обстоятельств написания программы, а также от условий ее эксплуатации. Наивысшим приоритетом пользуется, без сомнения, правильность. Обычно простоте, удобству модификации, живучести и документированности придают во крайней мере не меньший приоритет, чем эффективности.
На начальных шагах работают обычно с более абстрактными, более крупными информационными единицами, детальная структура которых уточняется впоследствии.
Стратегия нисходящей пошаговой детализации имеет следующие преимущества: она позволяет сформулировать грубое решение в терминах, наиболее адекватных решаемой задаче; в терминах таких мощных понятий решение будет сжатым и простым, а потому скорее всего правильным; каждый шаг детализации должен быть достаточно малым, чтобы не представлять больших интеллектуальных трудностей, если это удалось - трансформация решения в новое, более детальное представление скорее всего будет выполнена правильно, а следовательно, таким же правильным окажется и полученное решение следующего шага детализации. В случае Пролога мы можем говорить о пошаговой детализации отношений. Если существо задачи требует мышления в алгоритмических терминах, то мы можем также говорить и о детализации алгоритмов, приняв процедурную точку зрения на Пролог.
Для того, чтобы удачно сформулировать решение на некотором уровне детализации и придумать полезные понятия для следующего, более низкого уровня, нужны идеи. Поэтому программирование - это творческий процесс, что верно в особенности, когда речь идет о начинающих программистах. По мере накопления опыта работа программиста постепенно становится все менее искусством и все более ремеслом. И все же главным остается вопрос: как возникают идеи? Большинство идей приходит из опыта, из тех задач, решения которых уже известны. Если мы не знаем прямого решения задачи, то нам может помочь уже решенная задача, похожая на нашу. Другим источником идей является повседневная жизнь. Например, если необходимо запрограммировать сортировку списка, то можно догадаться, как это сделать, если задать себе вопрос: "А как бы я сам стал действовать, чтобы расположить экзаменационные листы студентов по их фамилиям в алфавитном порядке?"
Общие принципы, изложенные в данном разделе, известны также как составные части "структурного программирования"; они, в основном, применимы и к программированию на Прологе.В следующих разделах мы обсудим их более детально, обращая особое внимание на применение этих принципов программирования к Прологу.
Назад | Содержание | Вперёд
ОБЩИЙ ОБЗОР ЯЗЫКА ПРОЛОГ
В этой главе на примере конкретной программы рассматриваются основные механизмы Пролога. Несмотря на то, что материал излагается в основном неформально, здесь вводятся многие важные понятия.
double_line();Одно замечание по поводу программы-оболочки
В некоторых местах нашей программы-оболочки обнаруживается недостаток той "декларативной ясности", которая так характерна для программ, написанных на Прологе. Причина состоит в том, что нам пришлось предусмотреть в этой программе довольно жесткое управление процессом функционирования оболочки. Ведь, согласно нашему замыслу, экспертная система должна была не только находить ответы на вопросы, но и делать это некоторым разумным с точки зрения пользователя способом. В связи с этим нам пришлось реализовать вполне определенное поведение системы в процессе решения задач, а не просто некоторое отношение ввода-вывода. В результате получилась программа более процедурного характера, чем обычно. Все это может послужить примером ситуации, когда, не имея возможности рассчитывать на собственные процедурные механизмы Пролога, мы вынуждены взять на себя детальное описание процедурного поведения системы.
Ограничение перебора
В процессе достижения цели пролог-система осуществляет автоматический перебор вариантов, делая возврат при неуспехе какого-либо из них. Такой перебор - полезный программный механизм, поскольку он освобождает пользователя от необходимости программировать его самому. С другой стороны, ничем не ограниченный перебор может стать источником

Рис. 5. 1. Двухступенчатая функция
неэффективности программы. Поэтому иногда требуется его ограничить или исключить вовсе. Для этого в Прологе предусмотрена конструкция "отсечение".
Давайте сначала рассмотрим простую программу, процесс вычислений, по которой содержит ненужный перебор. Мы выделим те точки этого процесса, где перебор бесполезен и ведет к неэффективности.
Рассмотрим двухступенчатую функцию, изображенную на рис. 5.1. Связь между Х и Y можно определить с помощью следующих трех правил:
Правило 1: если Х < 3, то Y = 0
Правило 2: если 3 <= X и Х < 6, то Y = 2
Правило 3: если 6 <= X, то Y = 4
На Прологе это можно выразите с помощью бинарного отношения
f( X, Y)
так:
f( X, 0) :- X < 3. % Правило 1
f( X, 2) :- 3 =< X, X < 6. % Правило 2
f( X, 4) :- 6 =< X. % Правило 3
В этой программе предполагается, конечно, что к моменту начала вычисления f( X, Y) Х уже конкретизирован каким-либо числом; это необходимо для выполнения операторов сравнения.
Мы проделаем с этой программой два эксперимента. Каждый из них обнаружит в ней свой источник неэффективности, и мы устраним оба этих источника по очереди, применив оператор отсечения.
Опасность бесконечного цикла
Рассмотрим следующее предложение:
р :- р.
В нем говорится: "р истинно, если р истинно". С точки зрения декларативного смысла это совершенно корректно, однако в процедурном смысле оно бесполезно. Более того, для пролог-системы такое предложение может породить серьезную проблему. Рассмотрим вопрос:
?- р.
При использовании вышеприведенного предложения цель р будет заменена на ту же самую цель р; она в свою очередь будет заменена снова на р и т.д. В этом случае система войдет в бесконечный цикл, не замечая, что никакого продвижения в вычислениях не происходит.
Данный пример демонстрирует простой способ ввести пролог-систему в бесконечный цикл. Однако подобное зацикливание могло встретиться и в некоторых наших предыдущих программах, если бы мы изменили порядок предложений, или же порядок целей в них. Будет полезно рассмотреть несколько примеров.
В программе об обезьяне и банане предложения, касающиеся отношения ход, были упорядочены следующим образом: схватить, залезть, подвинуть, перейти (возможно, для полноты следует добавить еще "слезть"). В этих предложениях говорится, что можно схватить, можно залезть и т.д. В соответствии с процедурной семантикой Пролога порядок предложений указывает на то, что обезьяна предпочитает схватывание залезанию, залезание - передвиганию и т.д. Такой порядок предпочтений на самом деле помогает обезьяне решить задачу. Но что могло случиться. если бы этот порядок был другим? Предположим, что предложение с "перейти" оказалось бы первым. Процесс вычисления нашей исходной цели из предыдущего раздела
?- можетзавладеть( состояние( удвери, наполу, уокна, неимеет) ).
протекал бы на этот раз так. Первые четыре списка целей (с соответствующим образом переименованными переменными) остались бы такими же, как и раньше:
(1) можетзавладеть( состояние( удвери, наполу, уокна, неимеет) ).
Применение второго предложения из можетзавладеть ("может2") породило бы
(2) ход( состояние( удвери, наполу, уокна, неимеет), М', S2'),
можетзавладеть( S2')
С помощью хода перейти( уокна, Р2') получилось бы
(3) можетзавладеть( состояние( Р2', наполу, уокна, неимеет) )
Повторное использование предложения "может2" превратило бы список целей в
(4) ход( состояние(Р2', наполу, уокна, неимеет), М'', S2''),
можетзавладеть( S2")
С этого момента начались бы отличия. Первым предложением, голова которого сопоставима с первой целью из этого списка, было бы теперь "перейти" (а не "залезть", как раньше). Конкретизация стала бы следующей:
S2" = состояние( Р2", наполу, уокна, неимеет).
Поэтому список целей стал бы таким:
(5) можетзавладеть( состояние( Р2'', наполу, уокна, неимеет) )
Применение предложения "может2" дало бы
(6) ход( cocтояниe( P2", наполу, yoкнa, неимeeт), M" ', S2'' '),
можетзавладеть( S2" ')
Снова первый было бы попробовано "перейти" и получилось бы
(7) можетзавладеть( состояние( Р2" ', наполу, уокна, неимеет) )
Сравним теперь цели (3), (5) и (7). Они похожи и отличаются лишь одной переменной, которая по очереди имела имена Р', Р'' и P" '. Как мы знаем, успешность цели не зависит от конкретных имен переменных в ней. Это означает, что, начиная со списка целей (3), процесс вычислений никуда не продвинулся. Фактически мы замечаем, что по очереди многократно используются одни и те же два предложения: "может2" и "перейти".
Обезьяна перемещается, даже не пытаясь воспользоваться ящиком. Поскольку продвижения нет, такая ситуация продолжалась бы (теоретически) бесконечно: пролог-система не сумела бы осознать, что работать в этой направлении нет смысла.
Данный пример показывает, как пролог-система может пытаться решить задачу таким способом, при котором решение никогда не будет достигнуто, хотя оно существует. Такая ситуация не является редкостью при программировании на Прологе. Да и при программировании на других языках бесконечные циклы не такая уж редкость. Что действительно необычно при сравнении Пролога с другими языками, так это то, что декларативная семантика пролог-программы может быть правильной, но в то же самое время ее процедурная семантика может быть ошибочной в том смысле, что с помощью такой программы нельзя получить правильный ответ на вопрос. В таких случаях система не способна достичь цели потому, что она пытается добраться до ответа, но выбирает при этом неверный путь.
Теперь уместно спросить: "Не можем ли мы внести какое-либо более существенное изменение в нашу программу, так чтобы полностью исключить опасность зацикливания? Или же нам всегда придется рассчитывать на удачный порядок предложений и целей?" Как оказывается, программы, в особенности большие, были бы чересчур ненадежными, если бы можно было рассчитывать лишь на некоторый удачный порядок. Существует несколько других методов, позволяющих избежать зацикливания и являющихся более общими и надежными, чем сам по себе метод упорядочивания. Такие методы будут систематически использоваться дальше в книге, в особенности в тех главах, в которых пойдет речь о нахождении путей (в графах), о решения интеллектуальных задач и о переборе.
ОПЕРАЦИИ НАД СТРУКТУРАМИ ДАННЫХ
Один из фундаментальных вопросов программирования - это вопрос о представлении сложных объектов (таких как, например, множества), а также вопрос об эффективной реализации операций над подобными объектами. В этой главе мы рассмотрим несколько часто используемых структур данных, принадлежащих к трем большим семействам: спискам, деревьям и графам. Мы изучим способы представления этих структур на Прологе и составим программы, реализующие некоторые операции над ними, в том числе, сортировку списков, работу с множествами как древовидными структурами, запись элементов данных в дерево, поиск данных в дереве, нахождение пути в графе и т.п. Мы подробно разберем несколько примеров, чрезвычайно поучительных с точки зрения программирования на Прологе.
double_line();Операторная запись (нотация)
В математике мы привыкли записывать выражения в таком виде:
2*a + b*с
где + и * - это операторы, а 2, а, b, с - аргументы. В частности, + и * называют инфиксными операторами, поскольку они появляются между своими аргументами. Такие выражения могут быть представлены в виде деревьев, как это сделано на рис. 3.6, и записаны как прологовские термы с + и * в качестве функторов:
+( *( 2, а), *( b, с) )

Рис. 3. 6. Представление выражения 2*а+b*с в виде дерева.
Поскольку мы обычно предпочитаем записывать такие выражения в привычной инфиксной форме операторов, Пролог обеспечивает такое удобство. Поэтому наше выражение, записанное просто как
2*а + b*с
будет воспринято правильно. Однако это лишь внешнее представление объекта, которое будет автоматически преобразовано в обычную форму прологовских термов. Такой терм выводится пользователю снова в своей внешней инфиксной форме.
Выражения рассматриваются Прологом просто как дополнительный способ записи, при котором не вводятся какие-либо новые принципы структуризации объектов данных. Если мы напишем а + b, Пролог поймет эту запись, как если бы написали +(а, b). Для того, чтобы Пролог правильно воспринимал выражения типа а + b*с, он должен знать, что * связывает сильнее, чем +. Будем говорить, что + имеет более низкий приоритет, чем *. Поэтому верная интерпретация выражений зависит от приоритетов операторов. Например, выражение а + b*с, в принципе можно понимать и как
+( а, *( b, с) )
и как
*( +( а, b), с)
Общее правило состоит в том, что оператор с самым низким приоритетом расценивается как главный функтор терма.
Если мы хотим, чтобы выражения, содержащие + и *, понимались в соответствии с обычными соглашениями, то + должен иметь более низкий приоритет, чем *. Тогда выражение а + b*с означает то же, что и а + (b*с). Если имеется в виду другая интерпретация, то это надо указать явно с помощью скобок, например ( а+b)*с.
Программист может вводить свои собственные операторы. Так, например, можно определить атомы имеет
и поддерживает в качестве инфиксных операторов, а затем записывать в программе факты вида:
питер имеет информацию.
пол поддерживает стол.
Эти факты в точности эквивалентны следующим:
имеет( питер, информацию).
поддерживает( пол, стол).
Программист определяет новые операторы, вводя в программу особый вид предложений, которые иногда называют директивами. Такие предложения играют роль определений новых операторов. Определение оператора должно появиться в программе раньше, чем любое выражение, использующее этот оператор. Например, оператор имеет можно определить директивой
:- ор( 600, xfx, имеет).
Такая запись сообщит Прологу, что мы хотим использовать "имеет" в качестве оператора с приоритетом 600 и типом 'xfx', обозначающий одну из разновидностей инфиксного оператора. Форма спецификатора 'xfx' указывает на то, что оператор, обозначенный через 'f', располагается между аргументами, обозначенными через 'х'.
Обратите внимание на то, что определения операторов не содержат описания каких-либо операций или действий. В соответствии с принципами языка ни с одним оператором не связывается каких-либо операций над данными
(за исключением особых, редких случаев). Операторы обычно используются так же, как и функторы, только для объединения объектов в структуры и не вызывают действия над данными, хотя само слово "оператор", казалось бы, должно подразумевать какое-то действие.
Имена операторов это атомы, а их приоритеты - точнее, номера их приоритетов - должны находиться в некотором диапазоне, зависящем от реализации. Мы будем считать, что этот диапазон располагается в пределах от 1 до 1200.(Чем выше приоритет, тем меньше его номер. - Прим. перев.)
Существуют три группы типов операторов, обозначаемые спецификаторами, похожими на xfx:
(1) инфиксные операторы трех типов:
xfx xfy yfx
(2) префиксные операторы двух типов:
fx fy
(3) постфиксные операторы двух типов:
хf yf
Спецификаторы выбраны с таким расчетом, чтобы нагляднее отразить структуру выражения, в котором 'f' соответствует оператору, а 'х' и 'у' представляют его аргументы. Расположение 'f' между аргументами указывает на то, что оператор инфиксный. Префиксные и постфиксные спецификаторы содержат только один аргумент, который, соответственно, либо следует за оператором, либо предшествует ему.

Рис. 3. 7. Две интерпретации выражения а-b-с в предположении, что '-' имеет приоритет 500. Если тип '-' есть yfx, то интерпретация 2 неверна, так как приоритет b-с не выше, чем приоритет '-'.
Между 'х' и 'у' есть разница. Для ее объяснения нам потребуется ввести понятие приоритета аргумента. Если аргумент заключен в скобки или не имеет структуры (является простым объектом), тогда его приоритет равен 0; если же он структурный, тогда его приоритет равен приоритету его главного функтора. С помощью 'х' обозначается аргумент, чей приоритет должен быть строго выше приоритета оператора (т. е. его номер строго меньше номера приоритета оператора); с помощью 'у' обозначается аргумент, чей приоритет выше или равен приоритету оператора.
Такие правила помогают избежать неоднозначности при обработке выражений, в которых встречаются операторы с одинаковым приоритетом. Например, выражение
а-b-с
обычно понимается как (а-b)-с , а не как а-(b-с). Чтобы обеспечить такую обычную интерпретацию, оператор '-' следует определять как yfx. На рис. 3.7 показано, каким образом исключается вторая интерпретация.
В качестве еще одного примера рассмотрим оператор not (логическое отрицание "не"). Если not oпределён как fy, тогда выражение
not not р
записано верно; однако, если not определен как fx, оно некорректно, потому что аргументом первого not является структура not p, которая имеет тот же приоритет, что и not. В этом случае выражение следует писать со скобками:
not (not р)
line(); :- ор( 1200, xfx, ':-').
:- ор( 1200, fx, [:-, ?-] ).
:- op( 1100, xfy, ';').
:- ор( 1000, xfy, ',').
:- op( 700, xfx, [=, is, <, >, =<, >=, ==, =\=, \==, =:=]).
:- op( 500, yfx, [+, -] ).
:- op( 500, fx, [+, -, not] ).
:- op( 400, yfx, [*, /, div] ).
:- op( 300, xfx, mod).
line(); Рис. 3. 8. Множество предопределенных операторов.
Для удобства некоторые операторы в пролог-системах определены заранее, чтобы ими можно было пользоваться сразу, без какого-либо определения их в программе. Набор таких операторов и их приоритеты зависят от реализации. Мы будем предполагать, что множество этих "стандартных" операторов ведет себя так, как если бы оно было определено с помощью предложений, приведенных на рис. 3.8. Как видно из того же рисунка, несколько операторов могут быть определены в одном предложении, если только они все имеют одинаковый приоритет и тип. В этом случае имена операторов записываются в виде списка. Использование операторов может значительно повысить наглядность, "читабельность" программы. Для примера предположим, что мы пишем программу для обработки булевских выражений.
В такой программе мы, возможно, захотим записать утверждение одной из теорем де Моргана, которое в математических обозначениях записывается так:
~ (А & В) <===> ~А v ~В
Приведем один из способов записи этого утверждения в виде прологовского предложения:
эквивалентно( not( и( А, В)), или( not( A, not( B))).
Однако хорошим стилем программирования было бы попытаться сохранить по возможности больше сходства между видом записи исходной задачи и видом, используемом в программе ее решения. В нашем примере этого можно достичь почти в полной мере, применив операторы. Подходящее множество операторов для наших целей можно определить так:
:- ор( 800, xfx, <===>).
:- ор( 700, xfy, v).
:- ор( 600, хfу, &).
:- ор( 500, fy, ~).
Теперь правило де Моргана можно записать в виде следующего факта:
~(А & В) <===> ~А v ~В.
В соответствии с нашими определениями операторов этот терм понимается так, как это показано на рис. 3.9.
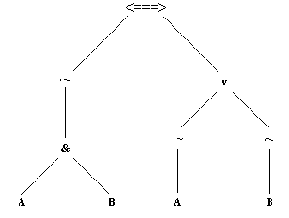
Рис. 3. 9. Интерпретация терма ~(А & В) <===> ~A v ~В
Подытожим: Наглядность программы часто можно улучшить, использовав операторную нотацию. Операторы бывают инфиксные, префиксные и постфиксные. В принципе, с оператором не связываются никакие действия над данными, за исключением особых случаев. Определение оператора не содержит описания каких-либо действий, оно лишь вводит новый способ записи. Операторы, как и функторы, лишь связывают компоненты в единую структуру. Программист может вводить свои собственные операторы. Каждый оператор определяется своим именем, приоритетом и типом. Номер приоритета - это целое число из некоторого диапазона, скажем, между 1 и 1200.Оператор с самым больший номером приоритета соответствует главному функтору выражения, в котором этот оператор встретился. Операторы с меньшими номерами приоритетов связывают свои аргументы сильнее других операторов. Тип оператора зависит от двух условий: (1) его расположения относительно своих аргументов, (2) приоритета его аргументов по сравнению с его собственным. В спецификаторах, таких, как xfy, х обозначает аргумент, чей номер приоритета строго меньше номера приоритета оператора; у - аргумент с номером приоритета, меньшим или равным номеру приоритета оператора.
Основные понятия
Под системами, ориентированными на типовые конфигурации (образцы), мы будем понимать программные системы специальной архитектуры. Для некоторых конкретных типов задач такая архитектура дает преимущества по сравнению с традиционным способом организации. Среди задач, которые естественным образом вписываются в этот вид архитектуры, находятся многие приложения искусственного интеллекта, в том числе экспертные системы. Основное различие между традиционными системами и системами, ориентированными на образцы, заключается в механизме запуска программных модулей. Традиционная архитектура предполагает, что модули системы обращаются друг к другу в соответствии с фиксированной, заранее заданной и явным образом сформулированной схемой. Каждый программный модуль сам принимает решение о том, какой из других модулей следует запустить в данный момент, причем в нем содержится явное обращение к этим модулям. Соответствующая временная структура передач управления от одних модулей к другим оказывается последовательной и детерминированной.
В противоположность этому организация, ориентированная на образцы, не предполагает прямого обращения из одних модулей к другим. Модули запускаются конфигурациями, возникающими в их "информационной среде". Такие программные модули называют модулями, управляемыми типовыми конфигурациями (или образцами). Программа, управляемая образцами, представляет из себя набор модулей. Каждый модуль определяется
(1) образцом, соответствующим предварительному условию запуска, и
(2) тем действием, которое следует выполнить, если информационная среда
согласуется с заданным образцом.
Запуск модулей на выполнение происходит при появлении тех или иных конфигураций в информационной среде системы. Такую информационную среду обычно называют базой данных.
Наглядное представление о системе рассматриваемого типа дает рис. 16.1.
Следует сделать несколько важных замечаний относительно рис. 16.1. Совокупность модулей не имеет иерархической структуры. Отсутствуют явные указания на то, какие модули могут обращаться к каким-либо другим модулям. Модули связаны скорее с базой данных, чем непосредственно друг с другом. В принципе такая структура допускает параллельное выполнение сразу нескольких модулей, поскольку текущее состояние базы данных может прийти в соот-
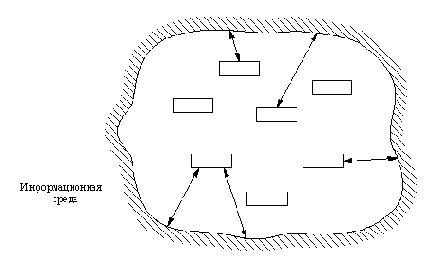
Рис. 16. 1. Система, управляемая типовыми конфигурациями ( образцами).
ветствие сразу с несколькими предварительными условиями, а следовательно, в принципе могут запуститься несколько модулей одновременно. В связи с этим, подобную организацию можно рассматривать как естественную модель параллельных вычислений, имея в виду, что каждый модуль физически реализован на отдельном процессоре.
Архитектура, ориентированная на образцы, обладает рядом достоинств. Одно из ее главных преимуществ состоит в том, что, разрабатывая подобную систему, мы не должны тщательно продумывать и заранее определять все связи между модулями. Следовательно, каждый модуль может быть разработан и реализован относительно автономно. Это придает системе высокую степень модульности, проявляющуюся, например, в том, что удаление из системы какого-либо модуля не обязательно приводит к фатальным последствиям. После удаления модуля система во многих случаях сохранит свою способность к решению задач, измениться может только способ их решения. Аналогичное соображение верно и в случае добавления новых модулей или изменения уже существующих. Заметим, что при введении подобных модификаций в традиционные системы потребовалось бы, как минимум, пересмотреть связи между модулями.
Высокая степень модульности особенно желательна в системах со сложными базами знаний, поскольку очень трудно предсказать заранее все возможные взаимодействия между отдельными фрагментами знаний. Архитектура, ориентированная на образцы, обеспечивает простое решение этой проблемы: каждый фрагмент знаний, представленный в виде "если-то"-правила, можно считать отдельным модулем, запускаемым своим собственным образцом.
Перейдем теперь к более детальной проработке нашей базовой схемы для систем, ориентированных на образцы, и рассмотрим вопросы реализации. Как следует из рис. 16.1, параллельная реализация была бы для нашей системы наиболее естественным решением. Тем не менее предположим, что нам предстоит реализовать ее на традиционном последовательном процессоре. Тогда если в базе знаний окажется сразу несколько "пусковых" конфигураций, относящихся к нескольким модулям, то возникнет конфликтная ситуация: нам придется принять решение о том, какой из этих потенциально активных модулей будет запущен в действительности. Совокупность всех потенциально активных модулей назовем конфликтным множеством. Очевидно, что реализация схемы рис. 16.1 на последовательном процессоре потребует введения в систему дополнительного, управляющего модуля. Задача управляющего модуля - выбрать и активизировать один из модулей конфликтного множества и тем самым разрешить конфликт. Одно из возможных простых правил разрешения конфликта может основываться, например, на предварительном упорядочивании множества модулей системы.
Основной цикл работы системы, ориентированной на образцы, состоит, таким образом, из трех шагов:
(1) Сопоставление с образцами: найти в базе данных все конфигурации, сопоставимые с пусковыми образцами программных модулей. Результат - конфликтное множество.
(2) Разрешение конфликта: выбрать один из модулей, входящих в конфликтное множество.
(3) Выполнение: запустить модуль, выбранный на предыдущем шаге.
Этот принцип реализации показан в виде схемы на рис. 16.2.
ОСНОВНЫЕ СТРАТЕГИИ РЕШЕНИЯ ЗАДАЧ
В данной главе мы сосредоточим свое внимание на одной общей схеме для представления задач, называемой пространством состояний. Пространство состояний - это граф, вершины которого соответствуют ситуациям, встречающимся в задаче ("проблемные ситуации"), а решение задачи сводится к поиску пути в этом графе. Мы изучим на примерах, как формулируются задачи в терминах пространства состояний, а также обсудим общие методы решения задач, представленных в рамках этого формализма. Процесс решения задачи включает в себя поиск в графе, при этом, как правило, возникает проблема, как обрабатывать альтернативные пути поиска. В этой главе будут представлены две основные стратегии перебора альтернатив, а именно поиск в глубину и поиск в ширину.
double_line();ОТ РЕДАКТОРА ПЕРЕВОДА
По существующей традиции предисловие редактора перевода - это своего рода рецензия, в которой обычно излагается история вопроса, а затем дается обзор содержания книги и оценка ее качества (как правило, рекламного характера). В данном случае моя задача несколько упрощается, так как все это читатель, перевернув страницу, найдет в предисловии известного американского ученого, специалиста по искусственному интеллекту П. Уинстона, а затем - в предисловии автора. Мне остается только присоединиться к авторитетному мнению П. Уинстона, что перед нами прекрасно написанный учебник до Прологу, ориентированный на практическое использование в области искусственного интеллекта. Добавлю также, что для советского читателя потребность в такой книге особенно велика, поскольку в нашей стране Пролог пока еще не получил того распространения, которого он заслуживает.
Несколько замечаний относительно особенностей перевода. Кроме обычных терминологических трудностей, как правило возникающих при переводе книг по программированию, переводчикам пришлось преодолевать одну дополнительную сложность. Дело в том, что в Прологе идентификаторы (имена переменных, процедур и атомов) несут на себе значительно большую смысловую нагрузку, чем в традиционных языках программирования. Поэтому программные примеры пришлось излагать на некоей условной русской версии Пролога - в противном случае, для читателей, не владеющих английским языком, эти примеры стали бы значительно менее понятными. Мы оставили без перевода все имена встроенных операторов и процедур, все же остальные имена переводились на русский язык. Следует признать, что в ряде случаев русская версия этих имен оказалась менее эстетически привлекательной, чем исходный английский вариант. Пытаясь наиболее точно передать смысл того или иного имени, переводчик нередко оказывался перед нелегким выбором между громоздким идентификатором (иногда из нескольких слов) и неблагозвучной аббревиатурой. Впрочем, все эти проблемы хорошо известны любому "русскоязычному" программисту.
Главы 1-8 перевел А. И. Лупенко, а предисловия и главы 9-16 - А.М. Степанов. Подготовку оригинала-макета книги на ЭВМ выполнили А.Н. Черных и Н.Г. Черных.
Эту книгу можно рекомендовать как тем читателям, которые впервые приступают к изучению Пролога и искусственного интеллекта, так и программистам, уже имеющим опыт составления пролог-программ.
А. М. Степанов
Назад | Содержание | Вперёд
Отладка
Когда программа не делает того, чего от нее ждут, главной проблемой становится отыскание ошибки (или ошибок). Всегда легче найти ошибку в какой-нибудь части программы (или в отдельном модуле), чем во всей программе. Поэтому следует придерживаться следующего хорошего принципа: проверять сначала более мелкие программные единицы и только после того, как вы убедились, что им можно доверять, начинать проверку большего модуля или всей программы.
Отладка в Прологе облегчается двумя обстоятельствами: во-первых, Пролог - интерактивный язык, поэтому можно непосредственно обратиться к любой части программы, задав пролог-системе соответствующий вопрос; во-вторых, в реализациях Пролога обычно имеются специальные средства отладки. Следствием этих двух обстоятельств является то, что отладка программ на Прологе может производиться, вообще говоря, значительно эффективнее, чем в других языках программирования.
Основным средством отладки является трассировка (tracing). "Трассировать цель" означает: предоставить пользователю информацию, относящуюся к достижению этой цели в процессе ее обработки пролог-системой. Эта информация включает: Входную информацию - имя предиката и значении аргументов в момент активизации цели. Выходную информацию - в случае успеха, значения аргументов, удовлетворяющих цели; в противном случае - сообщение о неуспехе. Информацию о повторном входе, т. е. об активизации той же цели в результате автоматического возврата.
В промежутке между входом и выходом можно получить трассировочную информацию для всех подцелей этой цели. Таким образом, мы можем следить за обработкой нашего вопроса на всем протяжении нисходящего пути от исходной цели к целям самого нижнего уровня, вплоть до отдельных фактов. Такая детальная трассировка может оказаться непрактичной из-за непомерно большого количества трассировочной информации. Поэтому пользователь может применить "селективную" трассировку. Существуют два механизма селекции: первый подавляет выдачу информации о целях, расположенных ниже некоторого уровня; второй трассирует не все предикаты, а только некоторые, указанные пользователем.
Средства отладки приводятся в действие при помощи системно- зависимых встроенных предикатов. Обычно используется следующий стандартный набор таких предикатов:
trace
запускает полную трассировку всех целей, следующих за trace.
notrace
прекращает дальнейшее трассирование.
spy( P) (следи за Р)
устанавливает режим трассировки предиката Р. Обращение к spy применяют, когда хотят получить информацию только об указанном предикате и избежать трассировочной информации от других целей (как выше, так и ниже уровня запуска Р). "Следить" можно сразу за несколькими предикатами.
nospy( Р)
прекращает "слежку" за Р.
Трассировка ниже определенной глубины может быть подавлена во время выполнения программы при помощи специальных команд. Существуют и другие команды отладки, такие как возврат к предыдущей точке процесса вычислений. После такого возврата можно, например, повторить вычисления с большей степенью детализации трассировки.
Отображение деревьев
Так же, как и любые объекты данных в Прологе, двоичное дерево Т может быть непосредственно выведено на печать при помощи встроенной процедуры write. Однако цель
write( Т)
хотя и отпечатает всю информацию, содержащуюся в дереве, но действительная структура дерева никак при этом не будет выражена графически. Довольно утомительная работа - пытаться представить себе структуру дерева, рассматривая прологовский терм, которым она представлена. Поэтому во многих случаях желательно иметь возможность отпечатать дерево в такой форме, которая графически соответствует его структуре.
Существует относительно простой способ это сделать. Уловка состоит в том, чтобы изображать дерево растущим слева направо, а не сверху вниз, как обычно. Дерево нужно повернуть влево таким образом, чтобы корень стал его крайним слева элементом, а листья сдвинулись вправо (рис. 9.16).
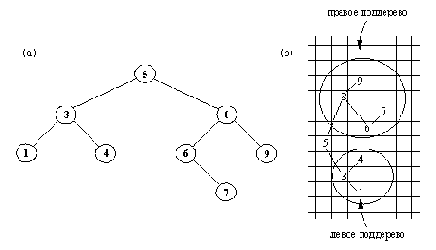
Рис. 9. 16. (а) Обычное изображение дерева. (b) То же дерево,
отпечатанное процедурой отобр (дуги добавлены для ясности).
Давайте определим процедуру
отобр( Т)
так, чтобы она отображала дерево в форме, показанной на рис. 9.16. Принцип работы этой процедуры:
line();Для того, чтобы отобразить непустое дерево Т, необходимо:
(1) отобразить правое поддерево дерева Т с отступом вправо на расстояние Н;
(2) отпечатать корень дерева Т;
(3) отобразить левое поддерево дерева Т с отступом вправо на расстояние Н.
line();Величина отступа Н, которую можно выбирать по желанию, - это дополнительный параметр при отображении деревьев. Введем процедуру
отобр2( Т, Н)
печатающую дерево Т с отступом на Н пробелов от левого края листа. Связь между процедурами отобр и отобр2 такова:
отобр( Т) :- отобр2( Т, 0).
На рис. 9.17 показана программа целиком. В этой программе предусмотрен сдвиг на 2 позиции для каждого уровня дерева. Описанный принцип отображения можно легко приспособить для деревьев других типов.
line(); отобр( Т) :-
отобр2( Т, 0).
отобр2( nil, _ ).
отобр2( дер( L, X, R), Отступ) :-
Отступ2 is Отступ + 2,
отобр2( R, Отступ2),
tab( Отступ), write( X), nl,
отобр( L, Отступ2).
line(); Рис. 9. 17. Отображение двоичного дерева.
Отрицание как неуспех
"Мэри любит всех животных, кроме змей". Как выразить это на Прологе? Одну часть этого утверждения выразить легко: "Мэри любит всякого X, если Х - животное". На Прологе это записывается так:
любит( мэри, X) :- животное ( X).
Но нужно исключить змей. Это можно сделать, использовав другую формулировку:
Если Х - змея, то "Мэри любит X" - не есть
истина,
иначе, если Х - животное, то Мэри любит X.
Сказать на Прологе, что что-то не есть истина, можно при помощи специальной цели fail (неуспех), которая всегда терпит неудачу, заставляя потерпеть неудачу и ту цель, которая является ее родителем. Вышеуказанная формулировка, переведенная на Пролог с использованием fail, выглядит так:
любит( мэри, X) :-
змея( X), !, fail.
любит( Мэри, X) :-
животное ( X).
Здесь первое правило позаботится о змеях: если Х - змея, то отсечение предотвратит перебор (исключая таким образом второе правило из рассмотрения), а fail вызовет неуспех. Эти два предложения можно более компактно записать в виде одного:
любит( мэри, X) :-
змея( X), !, fail;
животное ( X).
Ту же идею можно использовать для определения отношения
различны( X, Y)
которое выполняется, если Х и Y не совпадают. При этом, однако, мы должны быть точными, потому что "различны" можно понимать по-разному: Х и Y не совпадают буквально; Х и Y не сопоставимы; значения арифметических выражений Х и Y не равны.
Давайте считать в данном случае, что Х и Y различны, если они не сопоставимы.
Вот способ выразить это на Прологе:
Если Х и Y сопоставимы, то
цель различны( X, Y) терпит неуспех
иначе цель различны( X, Y) успешна.
Мы снова используем сочетание отсечения и fail:
различны( X, X) :- !, fail.
различны( X, Y).
То же самое можно записать и в виде одного предложения:
различны( X, Y) :-
Х = Y, !, fail;
true.
Здесь true - цель, которая всегда успешна.
Эти примеры показывают, что полезно иметь унарный предикат "not" (не), такой, что
nоt( Цель)
истинна, если Цель не истинна. Определим теперь отношение not следующим образом:
Если Цель
успешна, то not( Цель) неуспешна,
иначе not( Цель)
успешна.
Это определение может быть записано на Прологе так:
not( Р) :-
P, !, fail;
true.
Начиная с этого момента мы будем предполагать, что not - это встроенная прологовская процедура, которая ведет себя так, как это только что было определено. Будем также предполагать, что оператор not определен как префиксный, так что цель
not( змея( X) )
можно записывать и как
not змея( X)
Многие версии Пролога поддерживают такую запись. Если же приходится иметь дело с версией, в которой нет встроенного оператора not, его всегда можно определить самим.
Следует заметить, что not, как он здесь определен с использованием неуспеха, не полностью соответствует отрицанию в математической логике. Эта разница может породить неожиданности в поведении программы, если оператором not пользоваться небрежно. Этот вопрос будет рассмотрен в данной главе позже.
Тем не менее not - полезное средство, и его часто можно с выгодой применять вместо отсечения. Наши два примера можно переписать с not:
любит( мэри, X) :-
животное ( X),
not змея( X).
различны( X, Y) :-
not( Х = Y).
Это, конечно, выглядит лучше, нежели наши прежние формулировки. Вид предложений стал более естественным, и программу стало легче читать.
Нашу программу теннисной классификации из предыдущего раздела можно переписать с использованием not так, чтобы ее вид был ближе к исходным определениям наших трех категорий:
класс( X, боец) :-
победил( X, _ ),
победил( _, X).
класс( X, победитель) :-
победил( X, _ ),
not победил( _, X).
класс( X, спортсмен) :-
not победил( X, _ ).
В качестве еще одного примера использования not
рассмотрим еще раз программу 1 для решения задачи о восьми ферзях из предыдущей главы (рис. 4.7).Мы определили там отношение небьет между некоторым ферзем и остальными ферзями. Это отношение можно определить также и как отрицание отношения "бьет". На рис. 5.3 приводится соответствующим образом измененная программа.
Переменные
Переменные - это цепочки, состоящие из букв, цифр и символов подчеркивания. Они начинаются с прописной буквы или с символа подчеркивания:
Х
Результат
Объект2
Список_участников
СписокПокупок
_х23
_23
Если переменная встречается в предложения только один раз, то нет необходимости изобретать ей имя. Можно использовать так называемую "анонимную" переменную, которая записывается в виде одного символа подчеркивания. Рассмотрим, например, следующее правило:
Перестановки
Иногда бывает полезно построить все перестановки некоторого заданного списка. Для этого мы определим отношение перестановка с двумя аргументами. Аргументы - это два списка, один из которых является перестановкой другого. Мы намереваемся порождать перестановки списка с помощью механизма автоматического перебора, используя процедуру перестановка, подобно тому, как это делается в следующем примере:
?- перестановка( [а, b, с], Р).
Р = [а, b, с];
Р = [а, с, b];
Р = [b, а, с];
. . .
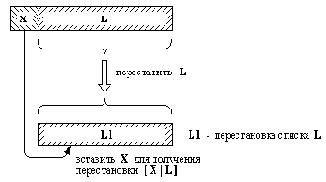
Рис. 3. 5. Один из способов построения перестановки списка [X | L].
Программа для отношения перестановка в свою очередь опять может основываться на рассмотрении двух случаев в зависимости от вида первого списка:
(1) Если первый список пуст, то и второй список должен быть пустым.
(2) Если первый список не пуст, тогда он имеет вид [Х | L], и перестановку такого списка можно построить так, как Это показано на рис. 3.5: вначале получить список L1 - перестановку L, а затем внести Х в произвольную позицию L1.
Два прологовских предложения, соответствующих этим двум случаям, таковы:
перестановка( [ ], [ ]).
перестановка( [X | L ], Р) :-
перестановка( L, L1),
внести( X, L1, Р).
Другой вариант этой программы мог бы предусматривать удаление элемента Х из первого списка, перестановку оставшейся его части - получение списка Р, а затем добавление Х в начало списка Р. Соответствующая программа такова:
перестановка2( [ ], [ ]).
перестановка2( L, [X | Р] ) :-
удалить( X, L, L1),
перестановка2( L1, Р).
Поучительно проделать несколько экспериментов с нашей программой перестановки. Ее нормальное использование могло бы быть примерно таким:
?- перестановка( [красный, голубой, зеленый], Р).
Как и предполагалось, будут построены все шесть перестановок:
Р = [ красный, голубой, зеленый];
Р = [ красный, зеленый, голубой];
Р = [ голубой, красный, зеленый];
Р = [ голубой, зеленый, красный];
Р = [ зеленый, красный, голубой];
Р = [ зеленый, голубой, красный];
nо (нет)
Приведем другой вариант использования процедуры перестановка:
?- перестановка( L, [а, b, с] ).
Наша первая версия, перестановка, произведет успешную конкретизацию L всеми шестью перестановками. Если пользователь потребует новых решений, он никогда не получит ответ "нет", поскольку программа войдет в бесконечный цикл, пытаясь отыскать новые несуществующие перестановки. Вторая версия, перестановка2, в этой ситуации найдет только первую (идентичную) перестановку, а затем сразу зациклится. Следовательно, при использовании этих отношений требуется соблюдать осторожность.
Планирование поездки
В данном разделе мы создадим программу, которая дает советы по планированию воздушного путешествия. Эта программа будет довольно примитивным советчиком, тем не менее она сможет отвечать на некоторые полезные вопросы, такие как: По каким дням недели есть прямые рейсы из Лондона в Любляну? Как в четверг можно добраться из Любляны в Эдинбург? Мне нужно посетить Милан, Любляну и Цюрих; вылетать нужно из Лондона во вторник и вернуться обратно в Лондон в пятницу. В какой последовательности мне следует посещать эти города, чтобы ни разу на протяжении поездки не пришлось совершать более одного перелета в день.
Центральной частью программы будет база данных, содержащая информацию о рейсах. Эта информация будет представлена в виде трехаргументного отношения:
расписание( Пункт1, Пункт2, Список_рейсов)
где Список_рейсов - это список, состоящий из структурированных объектов вида:
Время_отправления / Время_прибытия / Номер_рейса
/ Список_дней_вылета
Список_дней_вылета - это либо список дней недели, либо атом "ежедневно". Одно из предложений, входящих в расписание могло бы быть, например, таким:
расписание( лондон, эдинбург,
[ 9:40 / 10:50 / bа4733/ ежедневно,
19:40 / 20:50 / bа4833 / [пн, вт, ср, чт, пт, сб]] ).
Время представлено в виде структурированных объектов, состоящих из двух компонент - часов и минут, объединенных оператором ":".
Главная задача состоит в отыскании точных маршрутов между двумя заданными городами в определенные дни недели. Ее решение мы будем программировать в виде четырехаргументного отношения:
маршрут( Пункт1, Пункт2, День, Маршрут)
Здесь Маршрут - это последовательность перелетов, удовлетворяющих следующим критериям:
(1) начальная точка маршрута находится в Пункт1;
(2) конечная точка - в Пункт2;
(3) все перелеты совершаются в один и тот же день недели - День;
(4) все перелеты, входящие в Маршрут, содержатся в определении отношения расписание;
(5) остается достаточно времени для пересадки с рейса на рейс.
Маршрут представляется в виде списка структурированных объектов вида
Откуда - Куда : Номер_рейса : Время_отправления
Мы еще будем пользоваться следующими вспомогательными предикатами:
(1) рейс( Пункт1, Пункт2, День, N_рейса, Вр_отпр, Вр_приб)
Здесь сказано, что существует рейс N_рейса между Пункт1 и Пункт2 в день недели День с указанными временами отправления и прибытия.
(2) вр_отпр( Маршрут, Время)
Время - это время отправления по маршруту Маршрут.
(3) пересадка( Время1, Время2)
Между Время1 и Время2 должен существовать промежуток не менее 40 минут для пересадки с одного рейса на другой.
Задача нахождения маршрута напоминает моделирование недетерминированного автомата из предыдущего раздела: Состояния автомата соответствуют городам. Переход из состояния в состояние соответствует перелету из одного города в другой. Отношение переход автомата соответствует отношению расписание. Модель автомата находит путь в графе переходов между исходным и конечным состояниями; планировщик поездки находит маршрут между начальным н конечным пунктами поездки. Неудивительно поэтому, что отношение маршрут можно определить аналогично отношению допускает, с той разницей, что теперь нет "спонтанных переходов".
Существуют два случая:
(1) Прямой рейс: если существует прямой рейс между пунктами Пункт1 и Пункт2, то весь маршрут состоит только из одного перелета:
маршрут( Пункт1, Пункт2, День, [Пункт1-Пункт2 : Nр : Отпр]):-
рейс( Пункт1, Пункт2, День, Np, Отпр, Приб).
(2) Маршрут с пересадками: маршрут между пунктами Р1 и Р2 состоит из первого перелета из P1 в некоторый промежуточный пункт Р3 и маршрута между Р3 и Р2. Кроме того, между окончанием первого перелета и отправлением во второй необходимо оставить достаточно времени для пересадки.
маршрут( Р1, Р2, День, [Р1-Р3 : Nр1 : Отпр1 | Маршрут]) :-
маршрут( Р3, Р2, День, Маршрут ),
рейс( Р1, Р3, День, Npl, Oтпpl, Приб1),
вр_отпр( Маршрут, Отпр2),
пересадка( Приб1, Отпр2).
Вспомогательные отношения рейс, пересадка и вр_отпр запрограммировать легко; мы включили их в полный текст программы планировщика поездки на рис. 4.5. Там же приводится и пример базы данных расписания.
Наш планировщик исключительно прост и может рассматривать пути, очевидно ведущие в никуда. Тем не менее его оказывается вполне достаточно, если база данных о рейсах самолетов невелика. Для больших баз данных потребовалось бы разработать более интеллектуальный планировщик, который мог бы справиться с большим количеством путей, участвующих в перебора при нахождении нужного пути.
Вот некоторые примеры вопросов к планировщику: По каким дням недели существуют прямые рейсы из Лондона в Люблину?
?- рейс( лондон, любляна, День, _, _, _ ).
День = пт;
День = сб;
no (нет) line(); % ПЛАНИРОВЩИК ВОЗДУШНЫХ МАРШРУТОВ
:- ор( 50, xfy, :).
рейс( Пункт1, Пункт2, День, Np, ВрОтпр, ВрПриб) :-
расписание( Пункт1, Пункт2, СписРейсов),
принадлежит( ВрОтпр / ВрПриб / Nр / СписДней, СписРейсов),
день_выл( День, СписДней).
принадлежит( X, [X | L] ).
принадлежит( X, [Y | L] ) :-
принадлежит( X, L ).
день_выл( День, СписДней) :-
принадлежит( День, СписДней).
день_выл( День, ежедневно) :-
принадлежит( День, [пн, вт, ср, чт, пт, сб, вс] ).
маршрут( P1, P2, День, [Р1-Р2 : Np : ВрОтпр] ) :-
% прямой рейс
рейс( P1, P2, День, Np, ВрОтпр, _ ).
маршрут( Р1, Р2, День, [Pl-P3 : Np1 : Oтпp1 | Маршрут]) :-
% маршрут с пересадками
маршрут( Р3, P2, День, Маршрут ),
рейс( Р1, Р3, День, Npl, Oтпp1, Приб1),
вр_отпр( Маршрут, Отпр2),
пересадка( Приб1, Отпр2).
вр_отпр( [Р1-Р2 : Np : Отпр | _ ], Отпр).
пересадка( Часы1 : Минуты1, Часы2 : Минуты2) :-
60 * (Часы2-Часы1) + Минуты2 - Минуты1 >= 40
% БАЗА ДАННЫХ О РЕЙСАХ САМОЛЕТОВ
расписание( эдинбург, лондон,
[ 9:40 / 10:50 / bа4733 / ежедневно,
13:40 / 14:50 / ba4773 / ежедневно,
19:40 / 20:50 / bа4833 / [пн, вт, ср, чт, пт, вс] ] ).
расписание( лондон, эдинбург,
[ 9:40 / 10:50 / bа4732 / ежедневно,
11:40 / 12:50 / bа4752 / ежедневно,
18:40 / 19:50 / bа4822 / [пн, вт, ср, чт, пт] ] ),
расписание( лондон, любляна,
[13:20 / 16:20 / ju201 / [пт],
13:20 / 16:20 / ju213 / [вс] ] ).
расписание( лондон, цюрих,
[ 9:10 / 11:45 / bа614 / ежедневно,
14:45 / 17:20 / sr805 / ежедневно ] ).
расписание( лондон, милан,
[ 8:30 / 11:20 / bа510 / ежедневно,
11:00 / 13:50 / az459 / ежедневно ] ).
расписание( любляна, цюрих,
[11:30 / 12:40 / ju322 / [вт,чт] ] ).
расписание( любляна, лондон,
[11:10 / 12:20 / yu200 / [пт],
11:25 / 12:20 / yu212 / [вс] ] ).
расписание( милан, лондон,
[ 9:10 / 10:00 / az458 / ежедневно,
12:20 / 13:10 / bа511 / ежедневно ] ).
расписание( милан, цюрих,
[ 9:25 / 10:15 / sr621 / ежедневно,
12:45 / 13:35 / sr623 / ежедневно ] ).
расписание( цюрих, любляна,
[13:30 / 14:40 / yu323 / [вт, чт] ] ).
расписание( цюрих, лондон,
9:00 / 9:40 / bа613 /
[ пн, вт, ср, чт, пт, сб],
16:10 / 16:55 / sr806 / [пн, вт, ср, чт, пт, сб] ] ).
расписание( цюрих, милан,
[ 7:55 / 8:45 / sr620 / ежедневно ] ).
line(); Рис. 4. 5. Планировщик воздушных маршрутов и база данных о рейсах самолетов.
Как мне добраться из Любляны в Эдинбург в четверг?
?- маршрут( любляна, эдинбург, чт, R).
R = [любляна-цюрих : уu322 : 11:30, цюрих-лондон:
sr806 : 16:10,
лондон-эдинбург : bа4822 : 18:40 ]
Как мне посетить Милан, Любляну и Цюрих, вылетев из Лондона во вторник и вернувшись в него в пятницу, совершая в день не более одного перелета? Этот вопрос сложнее, чем предыдущие. Его можно сформулировать, использовав отношение перестановка, запрограммированное в гл. 3. Мы попросим найти такую перестановку городов Милан, Любляна и Цюрих, чтобы соответствующие перелеты можно было осуществить в несколько последовательных дней недели:
?- перестановка( [милан, любляна, цюрих],
[Город1, Город2, Город3] ),
рейс( лондон, Город1, вт, Np1, Oтпp1, Пpиб1),
peйc( Город1, Город2, ср, Np2, Отпр2, Приб2),
рейс( Город2, Город3, чт, Np3, Отпp3, Приб3),
рейс( Город3, лондон, пт, Np4, Отпр4, Приб4).
Город1 = милан
Город2 = цюрих
Город3 = любляна
Npl = ba510
Отпр1 = 8:30
Приб1 = 11:20
Np2 =sr621
Отпр2 = 9:25
Приб2 = 10:15
Np3 = yu323
Отпр3 = 13:30
Приб3 = 14:40
Np4 = yu200
Отпр4 = 11:10
Приб4 = 12:20 Назад | Содержание | Вперёд
Подсписок
Рассмотрим теперь отношение подсписок. Это отношение имеет два аргумента - список L и список S, такой, что S содержится в L в качестве подсписка. Так отношение
подсписок( [c, d, e], [a, b, c, d, e, f] )
имеет место, а отношение
подсписок( [c, e], [a, b, c, d, e, f] )
нет. Пролог-программа для отношения подсписок может основываться на той же идее, что и принадлежит1, только на этот раз отношение более общо (см. рис. 3.4).
Рис. 3. 4. Отношения принадлежит и подсписок.
Его можно сформулировать так:
S является подсписком L, если
(1) L можно разбить на два списка L1 и L2 и
(2) L2 можно разбить на два списка S и L3.
Как мы видели раньше, отношение конк можно использовать для разбиения списков. Поэтому вышеприведенную формулировку можно выразить на Прологе так:
подсписок( S, L) :-
конк( L1, L2, L),
конк( S, L3, L2).
Ясно, что процедуру подсписок можно гибко использовать различными способами. Хотя она предназначалась для проверки, является ли какой-либо список подсписком другого, ее можно использовать, например, для нахождения всех подсписков данного списка:
?- подсписок( S, [а, b, с] ).
S = [ ];
S = [a];
S = [а, b];
S = [а, b, с];
S = [b];
. . .
Поиск c предпочтением применительно к головоломке "игра в восемь"
Если мы хотим применить программу поиска с предпочтением, показанную на рис. 12.3, к какой-нибудь задаче, мы должны добавить к нашей программе отношения, отражающие специфику этой конкретной задачи. Эти отношения определяют саму задачу ("правила игры"), а также вносят в алгоритм эвристическую информацию о методе ее решения. Эвристическая информация задается в форме эвристической функции.
line();/* Процедуры, отражающие специфику головоломки
"игра в восемь".
Текущая ситуация представлена списком положений фишек;
первый элемент списка соответствует пустой клетке.
Пример:
|
Эта позиция представляется так: [2/2, 1/3, 2/3, 3/3, 3/2, 3/1, 2/1, 1/1, 1/2] |
"Пусто" можно перемещать в любую соседнюю клетку,
т.е. "Пусто" меняется местами со своим соседом.
*/
после( [Пусто | Спис], [Фшк | Спис1], 1) :-
% Стоимости всех дуг равны 1
перест( Пусто, Фшк, Спис, Спис1).
% Переставив Пусто и Фшк, получаем СПИС1
перест( П, Ф, [Ф | С], [П | С] ) :-
расст( П, Ф, 1).
перест( П, Ф, [Ф1 | С], [Ф1 | С1] ) :-
перест( П, Ф, С, С1).
расст( X/Y, X1/Y1, Р) :-
% Манхеттеновское расстояние между клетками
расст1( X, X1, Рх),
расст1( Y, Y1, Ру),
Р is Рх + Py.
расст1( А, В, Р) :-
Р is А-В, Р >= 0, ! ;
Р is B-A.
% Эвристическая оценка h равна сумме расстояний фишек
% от их "целевых" клеток плюс "степень упорядоченности",
% умноженная на 3
h( [ Пусто | Спис], H) :-
цель( [Пусто1 | Цспис] ),
сумрасст( Спис, ЦСпис, Р),
упоряд( Спис, Уп),
Н is Р + 3*Уп.
сумрасст( [ ], [ ], 0).
сумрасст( [Ф | С], [Ф1 | С1], Р) :-
расст( Ф, Ф1, Р1),
сумрасст( С, Cl, P2),
Р is P1 + Р2.
упоряд( [Первый | С], Уп) :-
упоряд( [Первый | С], Первый, Уп).
упоряд( [Ф1, Ф2 | С], Первый, Уп) :-
очки( Ф1, Ф2, Уп1),
упоряд( [Ф2 | С], Первый, Уп2),
Уп is Уп1 + Уп2.
упоряд( [Последний], Первый, Уп) :-
очки( Последний, Первый, Уп).
очки( 2/2, _, 1) :- !.
% Фишка в центре - 1 очко
очки( 1/3, 2/3, 0) :- !.
% Правильная последовательность - 0 очков
очки( 2/3, 3/3, 0) :- !.
очки( 3/3, 3/2, 0) :- !.
очки( 3/2, 3/1, 0) :- !.
очки( 3/1, 2/1, 0) :- !.
очки( 2/1, 1/1, 0) :- !.
очки( 1/1, 1/2, 0) :- !.
очки( 1/2, 1/3, 0) :- !.
очки( _, _, 2).
% Неправильная последовательность
цель( [2/2, 1/3, 2/3, 3/3, 3/2, 3/1, 2/1, 1/1, 1/2] ).
% Стартовые позиции для трех головоломок
старт1( [2/2, 1/3, 3/2, 2/3, 3/3, 3/1, 2/1, 1/1, 1/2] ).
% Требуется для решения 4 шага
старт2( [2/1, 1/2, 1/3, 3/3, 3/2, 3/1, 2/2, 1/1, 2/3] ).
% 5 шагов
старт3( [2/2, 2/3, 1/3, 3/1, 1/2, 2/1, 3/3, 1/1, 3/2] ).
% 18 шагов
% Отображение решающего пути в виде списка позиций на доске
показреш( [ ]).
показреш( [ Поз | Спис] :-
показреш( Спис),
nl, write( '---'),
показпоз( Поз).
% Отображение позиции на доске
показпоз( [S0, S1, S2, S3, S4, S5, S6, S7, S8] ) :-
принадлежит Y, [3, 2, 1] ), % Порядок Y-координат
nl, принадлежит X, [1, 2, 3] ),
% Порядок Х-координат
принадлежит( Фшк-X/Y,
[' '-S0, 1-S1, 2-S2, 3-S3, 4-S4, 5-S5, 6-S6, 7-S7, 8-S8]),
write( Фшк),
fail.
%Возврат с переходом к следующей клетке
показпоз( _ ).
line();
Рис. 12. 6. Процедуры для головоломки "игра в восемь",
предназначенные для использования программой поиска
с предпочтением рис. 12.3.
Существуют три отношения, отражающих специфику конкретной задачи:
после( Верш, Верш1, Ст)
Это отношение истинно, когда в пространстве состояний существует дуга стоимостью Ст
между вершинами Верш и Верш1.
цель( Верш)
Это отношение истинно, если Верш - целевая вершина.
h( Верш, Н)
Здесь Н - эвристическая оценка стоимости самого дешевого пути из вершины Верш
в целевую вершину.
В данном и следующих разделах мы определим эти отношения для двух примеров предметных областей: для головоломки "игра в восемь" (описанной в разделе 11.1) и планирования прохождения задач в многопроцессорной системе.
Отношения для "игры в восемь" показаны на рис. 12.6. Вершина пространства состояний - это некоторая конфигурация из фишек на игровой доске.
В программе она задается списком текущих положений фишек. Каждое положение определяется парой координат X/Y. Элементы списка располагаются в следующем порядке:
(1) текущее положение пустой клетки,
(2) текущее положение фишки 1,
(3) текущее положение фишки 2,
...
Целевая ситуация (см. рис. 11.3) определяется при помощи предложения
цель( [2/2, 1/3, 2/3, 3/3, 3/2, 3/1, 2/1, 1/1, 1/2] ).
Имеется вспомогательное отношение
расст( K1, K2, Р)
Р - это "манхеттеновское расстояние" между клетками Kl и K2, равное сумме двух расстояний между Kl и K2: расстояния по горизонтали и расстояния по вертикали.
Рис. 12. 7. Три стартовых позиции для "игры в восемь": (а) решение требует
4 шага; (b) решение требует 5 шагов; (с) решение требует 18 шагов.
Наша задача - минимизировать длину решения, поэтому мы положим стоимости всех дуг пространства состояний равными 1. В программе рис. 12. 6. даны также определения трех начальных позиций (см. рис. 12.7).
Эвристическая функция h, запрограммирована как отношение
h( Поз, Н)
Поз - позиция на доске; Н вычисляется как комбинация из двух оценок:
(1) сумрасст - "суммарное расстояние" восьми фишек, находящихся в позиции Поз, от их положений в целевой позиции. Например, для начальной позиции, показанной на рис. 12.7(а), сумрасст = 4.
(2) упоряд - степень упорядоченности фишек в текущей позиции по отношению к тому порядку, в котором они должны находиться в целевой позиции. Величина упоряд вычисляется как сумма очков, приписываемых фишкам, согласно следующим правилам: фишка в центральной позиции - 1 очко; фишка не в центральной позиции, и непосредственно за ней следует (по часовой стрелке) та фишка, какая и должна за ней следовать в целевой позиции - 0 очков. то же самое, но за фишкой следует "не та" фишка - 2 очка. Например, для начальной позиции рис.12.7(а),
упоряд = 6.
Эвристическая оценка Н вычисляется как сумма
Н = сумрасст + 3 * упоряд
Эта эвристическая функция хорошо работает в том смысле, что она весьма эффективно направляет поиск к цели. Например, при решении головоломок рис. 12.7(а) и (b) первое решение обнаруживается без единого отклонения от кратчайшего решающего пути. Другими словами, кратчайшие решения обнаруживаются сразу, без возвратов. Даже трудная головоломка рис. 12.7 (с) решается почти без возвратов. Но данная эвристическая функция страдает тем недостатком, что она не является допустимой: нет гарантии, что более короткие пути обнаруживаются раньше более длинных. Дело в том, что для функции h условие h <= h* выполнено не для всех вершин пространства состояний. Например, для начальной позиции рис. 12.7 (а)
h = 4 + 3 * 6 = 22, h* = 4
С другой стороны, оценка "суммарное расстояние" допустима: для всех позиций
сумрасст <= h*
Доказать это неравенство можно при помощи следующего рассуждения: если мы ослабим условия задачи и разрешим фишкам взбираться друг на друга, то каждая фишка сможет добраться до своего целевого положения по траектории, длина которой в точности равна манхеттеновскому расстоянию между ее начальным и целевым положениями. Таким образом, длина оптимального решения упрощенной задачи будет в точности равна сумрасст. Однако в исходном варианте задачи фишки взаимодействуют друг с другом и мешают друг другу, так что им уже трудно идти по своим кратчайшим траекториям. В результате длина оптимального решения окажется больше либо равной сумрасст.
Поиск пути в графе
Пусть G - граф, а А и Z - две его вершины. Определим отношение
путь( А, Z, G, Р)
где Р - ациклический путь между А и Z в графе G. Если G - граф, показанный в левой части рис. 9.18, то верно:
путь( a, d, G, [a, b, d] )
путь( а, d, G, [a, b, c, d] )
Поскольку путь не должен содержать циклов, любая вершина может присутствовать в пути не более одного раза. Вот один из методов поиска пути:
line();Для того, чтобы найти ациклический путь Р между А и Z в графе G, необходимо:
Если А = Z , то положить Р = [А], иначе найти ациклический путь Р1 из произвольной вершины Y в Z, а затем найти путь из А в Y, не содержащий вершин из Р1.
line();В этой формулировке неявно предполагается, что существует еще одно отношение, соответствующее поиску пути со следующий ограничением: путь не должен проходить через вершины из некоторого подмножества (в данном случае Р1) множества всех вершин графа. В связи с этим мы определим ещё одну процедуру:
путь1( А, Р1, G, Р)
Аргументы в соответствии с рис. 9.19 имеют следующий смысл: А - некоторая вершина,

Pис. 9. 19. Отношение путь1: Путь - это путь между А и Z, в своей
заключительной части он перекрывается с Путь1.
Между путь и путь1 имеется следующее соотношение:
путь( А, Z, G, Р) :- путь1( А, [Z], G, Р).
На рис. 9.19 показана идея рекурсивного определения отношения путь1. Существует "граничный" случай, когда начальная вершина пути P1 (Y на рис. 9.19) совпадает с начальной вершиной А пути Р. Если же начальные вершины этих двух путей не совпадают, то должна существовать такая вершина X, что
(1) Y - вершина, смежная с X,
(2) Х не содержится в Р1 и
(3) для Р выполняется отношение
путь1( А, [Х | Р1], G, Р).
line();
путь( A, Z, Граф, Путь) :-
путь1( А, [Z], Граф, Путь).
путь1( А, [А | Путь1, _, [А | Путь1] ).
путь1( А, [Y | Путь1], Граф, Путь) :-
смеж( X, Y, Граф),
принадлежит( X, Путь1), % Условие отсутствия цикла
путь1( А, [ X, Y | Путь1], Граф, Путь).
line();
Рис. 9. 20. Поиск в графе Граф
ациклического пути Путь из А в Z.
На рис. 9. 20 программа показана полностью. Здесь принадлежит
- отношение принадлежности элемента списку. Отношение
смеж( X, Y, G)
означает, что в графе G существует дуга, ведущая из Х в Y. Определение этого отношения зависит от способа представления графа. Если G представлен как пара множеств (вершин и ребер)
G = граф( Верш, Реб)
то
смеж( X, Y, граф( Верш, Реб) ) :-
принадлежит( р( X, Y), Реб);
принадлежит( р( Y, X), Реб).
Классическая задача на графах - поиск Гамильтонова цикла, т.е. ациклического пути, проходящего через все вершины графа. Используя отношение путь, эту задачу можно решить так:
гамильтон( Граф, Путь) :-
путь( _, _, Граф, Путь),
всевершины( Путь, Граф).
всевершины( Путь, Граф) :-
not (вершина( В, Граф),
not принадлежит( В, Путь) ).
Здесь вершина( В, Граф) означает: В
- вершина графа Граф.
Каждому пути можно приписать его стоимость. Стоимость пути равна сумме стоимостей входящих в него дуг. Если дугам не приписаны стоимости, то тогда, вместо стоимости, говорят о длине пути.
Для того, чтобы наши отношения путь и путь1
могли работать со стоимостями, их нужно модифицировать, введя дополнительный аргумент для каждого пути:
путь( А, Z, G, Р, С)
путь1( A, P1, C1, G, Р, С)
Здесь С - стоимость пути Р, a C1 - стоимость пути Р1. В отношении смеж также появится дополнительный аргумент, стоимость дуги. На рис. 9.21 показана программа поиска пути, которая строит путь и вычисляет его стоимость.
line();
путь( А, Z, Граф, Путь, Ст) :-
путь1( A, [Z], 0, Граф, Путь, Ст).
путь1( А, [А | Путь1], Ст1, Граф, [А | Путь1], Ст).
путь1( А, [Y | Путь1], Ст1, Граф, Путь, Ст) :-
смеж( X, Y, СтXY, Граф),
not принадлежит( X, Путь1),
Ст2 is Ст1 + СтXY,
путь1( А, [ X, Y | Путь1], Ст2, Граф, Путь, Ст).
line();
Рис. 9. 21. Поиск пути в графе: Путь - путь между А и Z в графе Граф
стоимостью Ст.
Эту процедуру можно использовать для нахождения пути минимальной стоимости. Мы можем построить путь минимальной стоимости между вершинами Верш1, Верш2 графа Граф, задав цели
путь( Bepш1, Верш2, Граф, МинПуть, МинСт),
not ( путь( Верш1, Верш2, Граф, _, Ст), Ст<МинСт )
Аналогично можно среди всех путей между вершинами графа найти путь максимальной стоимости, задав цели
путь( _, _, Граф, МаксПуть, МаксСт),
not ( путь( _, _, Граф, _, Ст), Ст > МаксСт)
Заметим, что приведенный способ поиска максимальных и минимальных путей крайне неэффективен, так как он предполагает просмотр всех возможных путей и потому не подходит для больших графов из-за своей высокой временной сложности. В искусственном интеллекте задача поиска пути возникает довольно часто. В главах 11 и 12 мы изучим более сложные методы нахождения оптимальных путей.
Поиск с предпочтением
Программу поиска с предпочтением можно получить как результат усовершенствования программы поиска в ширину (рис. 11.13). Подобно поиску в ширину, поиск с предпочтением начинается со стартовой вершины и использует множество путей-кандидатов. В то время, как поиск в ширину всегда выбирает для продолжения самый короткий путь (т.е. переходит в вершины наименьшей глубины), поиск с предпочтением вносит в этот принцип следующее усовершенствование: для каждого кандидата вычисляется оценка и для продолжения выбирается кандидат с наилучшей оценкой.
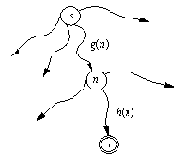
Рис. 12. 1. Построение эвристической оценки f(n) стоимости
самого дешевого пути из s в t, проходящего через n: f(n) = g(n) + h(n).
Мы будем в дальнейшем предполагать, что для дуг пространства состояний определена функция стоимости с(n, n') - стоимость перехода из вершины n к вершине-преемнику n'.
Пусть f - это эвристическая оценочная функция, при помощи которой мы получаем для каждой вершины n оценку f( n) "трудности" этой вершины. Тогда наиболее перспективной вершиной-кандидатом следует считать вершину, для которой f принимает минимальное значение. Мы будем использовать здесь функцию f специального вида, приводящую к хорошо известному А*-алгоритму. Функция f( n) будет построена таким образом, чтобы давать оценку стоимости оптимального решающего пути из стартовой вершины s к одной из целевых вершин при условии, что этот путь проходит через вершину n. Давайте предположим, что такой путь существует и что t - это целевая вершина, для которой этот путь минимален. Тогда оценку f( n) можно представить в виде суммы из двух слагаемых (рис. 12.1):
f( n) = g( n) + h( n)
Здесь g( n) - оценка оптимального пути из s в n; h( n) - оценка оптимального пути из n в t.
Когда в процессе поиска мы попадаем в вершину n, мы оказываемся в следующей ситуация: путь из s в n уже найден, и его стоимость может быть вычислена как сумма стоимостей составляющих его дуг. Этот путь не обязательно оптимален (возможно, существует более дешевый, еще не найденный путь из s в n), однако стоимость этого пути можно использовать в качестве оценки g(n) минимальной стоимости пути из s в n. Что же касается второго слагаемого h(n), то о нем трудно что-либо сказать, поскольку к этому моменту область пространства состояний, лежащая между n и t, еще не "изучена" программой поиска. Поэтому, как правило, о значении h(n) можно только строить догадки на основании эвристических соображений, т.е. на основании тех знаний о конкретной задаче, которыми обладает алгоритм. Поскольку значение h зависит от предметной области, универсального метода для его вычисления не существует. Конкретные примеры того, как строят эти "эвристические догадки", мы приведем позже. Сейчас же будем считать, что тем или иным способом функция h задана, и сосредоточим свое внимание на деталях нашей программы поиска с предпочтением.
Можно представлять себе поиск с предпочтением следующим образом. Процесс поиска состоит из некоторого числа конкурирующих между собой подпроцессов, каждый из которых занимается своей альтерна-
Рис. 12. 2. Поиск кратчайшего маршрута из s в t. (а) Карта со
связями между городами; связи помечены своими длинами; в
квадратиках указаны расстояния по прямой до цели t.
(b) Порядок, в котором при поиске с предпочтением происходит
обход городов. Эвристические оценки основаны на расстояниях
по прямой. Пунктирной линией показано переключение активности
между альтернативными путями. Эта линия задает тот порядок, в
котором вершины принимаются для продолжения пути, а не тот
порядок, в котором они порождаются.
тивой, т.е. просматривает свое поддерево. У поддеревьев есть свои поддеревья, их просматривают подпроцессы подпроцессов и т.д. В каждый данный момент среди всех конкурирующих процессов активен только один - тот, который занимается наиболее перспективной к настоящему моменту альтернативой, т.е. альтернативой с наименьшим значением f. Остальные процессы спокойно ждут того момента, когда f-оценки изменятся и в результате какая-нибудь другая альтернатива станет наиболее перспективной. Тогда производится переключение активности на эту альтернативу. Механизм активации-дезактивации процессов функционирует следующим образом: процесс, работающий над текущей альтернативой высшего приоритета, получает некоторый "бюджет" и остается активным до тех пор, пока его бюджет не исчерпается. Находясь в активном состоянии, процесс продолжает углублять свое поддерево. Встретив целевую вершину, он выдает соответствующее решение. Величина бюджета, предоставляемого процессу на данный конкретный запуск, определяется эвристической оценкой конкурирующей альтернативы, ближайшей к данной.
На рис. 12.2 показан пример поведения конкурирующих процессов. Дана карта, задача состоит в том, чтобы найти кратчайший маршрут из стартового города s в целевой город t. В качестве оценки стоимости остатка маршрута из города Х до цели мы будем использовать расстояние по прямой расст( X, t) от Х до t. Таким образом,
f( Х) = g( X) + h( X) = g( X) + расст( X, t)
Мы можем считать, что в данном примере процесс поиска с предпочтением состоит из двух процессов. Каждый процесс прокладывает свой путь - один из двух альтернативных путей: Процесс 1 проходит через а. Процесс 2 - через е. Вначале Процесс 1 более активен, поскольку значения f вдоль выбранного им пути меньше, чем вдоль второго пути. Когда Процесс 1 достигает города с, а Процесс 2 все еще находится в е, ситуация меняется:
f( с) = g( c) + h( c) = 6 + 4 = 10
f( e) = g( e) + h( e) = 2 + 7 = 9
Поскольку f( e) < f( c), Процесс 2 переходит к f, a Процесс 1 ждет. Однако
f( f) = 7 + 4 = 11
f( c) = 10
f( c) < f( f)
Поэтому Процесс 2 останавливается, а Процессу 1 дается разрешение продолжать движение, но только до d, так как f( d) = 12 > 11. Происходит активация Процесса 2, после чего он, уже не прерываясь, доходит до цели t.
Мы реализуем этот механизм программно при помощи усовершенствования программы поиска в ширину (рис. 11.13). Множество путей-кандидатов представим деревом. Дерево будет изображаться в программе в виде терма, имеющего одну из двух форм:
(1) л( В, F/G) - дерево, состоящее из одной вершины (листа); В - вершина пространства состояний, G - g( B) (стоимость уже найденного пути из стартовой вершины в В); F - f( В) = G + h( В).
(2) д( В, F/G, Пд) - дерево с непустыми поддеревьями; В - корень дерева, Пд - список поддеревьев; G - g( B); F - уточненное значение f( В), т.е. значение f для наиболее перспективного преемника вершины В; список Пд упорядочен в порядке возрастания f-оценок поддеревьев.
Уточнение значения f необходимо для того, чтобы дать программе возможность распознавать наиболее перспективное поддерево (т.е. поддерево, содержащее наиболее перспективную концевую вершину) на любом уровне дерева поиска. Эта модификация f-оценок на самом деле приводит к обобщению, расширяющему область определения функции f. Теперь функция f определена не только на вершинах, но и на деревьях.
Для одновершинных деревьев (листов) n остается первоначальное определение
f( n) = g( n) + h( n)
Для дерева T с корнем n, имеющем преемников m1, m2, ..., получаем
f( T) = min f( mi )
i
Программа поиска с предпочтением, составленная в соответствии с приведенными выше общими соображениями, показана на рис 12.3. Ниже даются некоторые дополнительные пояснения.
Так же, как и в случае поиска в ширину (рис. 11.13), ключевую роль играет процедура расширить, имеющая на этот раз шесть аргументов:
расширить( Путь, Дер, Предел, Дер1, ЕстьРеш, Решение)
Эта процедура расширяет текущее (под)дерево, пока f-оценка остается равной либо меньшей, чем Предел.
line(); % Поиск с предпочтением
эврпоиск( Старт, Решение):-
макс_f( Fмакс). % Fмакс > любой f-оценки
расширить( [ ], л( Старт, 0/0), Fмакс, _, да, Решение).
расширить( П, л( В, _ ), _, _, да, [В | П] ) :-
цель( В).
расширить( П, л( В, F/G), Предел, Дер1, ЕстьРеш, Реш) :-
F <= Предел,
( bagof( B1/C, ( после( В, В1, С), not принадлежит( В1, П)),
Преемники), !,
преемспис( G, Преемники, ДД),
опт_f( ДД, F1),
расширить( П, д( В, F1/G, ДД), Предел, Дер1,
ЕстьРеш, Реш);
ЕстьРеш = никогда). % Нет преемников - тупик
расширить( П, д( В, F/G, [Д | ДД]), Предел, Дер1,
ЕстьРеш, Реш):-
F <= Предел,
опт_f( ДД, OF), мин( Предел, OF, Предел1),
расширить( [В | П], Д, Предел1, Д1, ЕстьРеш1, Реш),
продолжить( П, д( В, F/G, [Д1, ДД]), Предел, Дер1,
ЕстьРеш1, ЕстьРеш, Реш).
расширить( _, д( _, _, [ ]), _, _, никогда, _ ) :- !.
% Тупиковое дерево - нет решений
расширить( _, Дер, Предел, Дер, нет, _ ) :-
f( Дер, F), F > Предел. % Рост остановлен
продолжить( _, _, _, _, да, да, Реш).
продолжить( П, д( В, F/G, [Д1, ДД]), Предел, Дер1,
ЕстьРеш1, ЕстьРеш, Реш):-
( ЕстьРеш1 = нет, встав( Д1, ДД, НДД);
ЕстьРеш1 = никогда, НДД = ДД),
опт_f( НДД, F1),
расширить( П, д( В, F1/G, НДД), Предел, Дер1,
ЕстьРеш, Реш).
преемспис( _, [ ], [ ]).
преемспис( G0, [В/С | ВВ], ДД) :-
G is G0 + С,
h( В, Н), % Эвристика h(B)
F is G + Н,
преемспис( G0, ВВ, ДД1),
встав( л( В, F/G), ДД1, ДД).
% Вставление дерева Д в список деревьев ДД с сохранением
% упорядоченности по f-оценкам
встав( Д, ДД, [Д | ДД] ) :-
f( Д, F), опт_f( ДД, F1),
F =< F1, !.
встав( Д, [Д1 | ДД], [Д1 | ДД1] ) ) :-
встав( Д, ДД, ДД1).
% Получение f-оценки
f( л( _, F/_ ), F). % f-оценка листа
f( д( _, F/_, _ ) F). % f-оценка дерева
опт_f( [Д | _ ], F) :- % Наилучшая f-оценка для
f( Д, F). % списка деревьев
опт_f( [ ], Fмакс) :- % Нет деревьев:
мaкс_f( Fмакс). % плохая f-оценка
мин( X, Y, X) :-
Х =< Y, !.
мин( X, Y, Y).
line(); Рис. 12. 3. Программа поиска с предпочтением.
Аргументы процедуры расширить имеют следующий смысл:
Путь Путь между стартовой вершиной и корнем дерева Дер.
Дер Текущее (под)дерево поиска.
Предел Предельное значение f-оценки, при котором допускается расширение.
Дер1 Дерево Дер, расширенное в пределах ограничения Предел;
f-оценка дерева Дер1 больше, чем Предел ( если только при расширении не была обнаружена целевая вершина).
ЕстьРеш Индикатор, принимающий значения "да", "нет" и "никогда".
Решение Решающий путь, ведущий из стартовой вершины через дерево Дер1
к целевой вершине и имеющий стоимость, не превосходящую ограничение Предел (если такая целевая вершина была обнаружена).
Переменные Путь, Дер, и Предел - это "входные" параметры процедуры расширить в том смысле, что при каждом обращении к расширить они всегда конкретизированы. Процедура расширить порождает результаты трех видов. Какой вид результата получен, можно определить по значению индикатора ЕстьРеш следующим образом:
(1) ЕстьРеш = да.
Решение = решающий путь, найденный при расширении дерева Дер с учетом ограничения Предел.
Дер1 = неконкретизировано.
(2) ЕстьРеш = нет
Дер1 = дерево Дер, расширенное до тех пор, пока его f-оценка не превзойдет Предел (см. рис. 12.4).
Решение = неконкретизировано.
(3) ЕстьРеш = никогда.
Дер1 и Решение = неконкретизированы.
В последнем случае Дер является "тупиковой" альтернативой, и соответствующий процесс никогда не будет реактивирован для продолжения просмотра этого дерева. Случай этот возникает тогда, когда f-оценка дерева Дер не превосходит ограничения Предел, однако дерево не может "расти" потому, что ни один его лист не имеет преемников, или же любой преемник порождает цикл.
Некоторые предложения процедуры расширить требуют пояснений. Предложение, относящееся к наиболее сложному случаю, когда Дер имеет поддеревья, т.е.
Дер = д( В, F/G, [Д | ДД ] )
означает следующее. Во-первых, расширению подвергается наиболее перспективное дерево Д. В качестве ограничения этому дереву выдается не Предел, а не-

Рис. 12. 4. Отношение расширить: расширение дерева Дер до тех
пор, пока f-оценка не превзойдет Предел, приводит к дереву Дер1.
которое, возможно, меньшее значение Предел1, зависящее от f-оценок других конкурирующих поддеревьев ДД. Тем самым гарантируется, что "растущее" дерево - это всегда наиболее перспективное дерево, а переключение активности между поддеревьями происходит в соответствии с их f-оценками. После того, как самый перспективный кандидат расширен, вспомогательная процедура продолжить решает, что делать дальше, а это зависит от типа результата, полученного после расширения. Если найдено решение, то оно и выдается, в противном случае процесс расширения деревьев продолжается.
Предложение, относящееся к случаю
Дер = л( В, F/G)
порождает всех преемников вершины В вместе со стоимостями дуг, ведущих в них из В. Процедура преемспис формирует список поддеревьев, соответствующих вершинам-преемникам, а также вычисляет их g- и f-оценки, как показано на рис. 12.5. Затем полученное таким образом дерево подвергается расширению с учетом ограничения Предел. Если преемников нет, то переменной ЕстьРеш придается значение "никогда" и в результате лист В покидается навсегда.
Другие отношения:
после( В, В1, С) В1 - преемник вершины В; С - стоимость дуги, ведущей из В в В1.
h( В, Н) Н - эвристическая оценка стоимости оптимального пути
из вершины В в целевую вершину.
макс_f( Fмакс) Fмакс - некоторое значение, задаваемое пользователем,
про которое известно, что оно больше любой возможной f-оценки.
В следующих разделах мы покажем на примерах, как можно применить нашу программу поиска с предпочтением к конкретным задачам. А сейчас сделаем несколько заключительных замечаний общего характера относительно этой программы. Мы реализовали один из вариантов эвристического алгоритма, известного в литературе как А*-алгоритм (ссылки на литературу см. в конце главы). А*-алгоритм привлек внимание многих исследователей. Здесь мы приведем один важный результат, полученный в результате математического анализа А*-алгоритма:
Рис. 12. 5. Связь между g-оценкой вершины В и f- и g-оценками
ее "детей" в пространстве состояний.
line(); Алгоритм поиска пути называют допустимым, если он всегда отыскивает оптимальное решение (т.е. путь минимальной стоимости) при условии, что такой путь существует. Наша реализация алгоритма поиска, пользуясь механизмом возвратов, выдает все существующие решения, поэтому, в нашем случае, условием допустимости следует считать оптимальность первого из найденных решений. Обозначим через h*(n) стоимость оптимального пути из произвольной вершины n в целевую вершину. Верна следующая теорема о допустимости А*-алгоритма: А*-алгоритм, использующий эвристическую функцию h, является допустимым, если
h( n) <= h*( n)
для всех вершин n пространства состояний.
line(); Этот результат имеет огромное практическое значение. Даже если нам не известно точное значение h*, нам достаточно найти какую-либо нижнюю грань h* и использовать ее в качестве h в А*-алгоритме - оптимальность решения будет гарантирована.
Существует тривиальная нижняя грань, а именно:
h( n) = 0, для всех вершин n пространства состояний.
И при таком значении h допустимость гарантирована.Однако такая оценка не имеет никакой эвристической силы и ничем не помогает поиску. А*-алгоритм при h=0 ведет себя аналогично поиску в ширину. Он, действительно, превращается в поиск в ширину, если, кроме того, положить с(n, n' )=1 для всех дуг (n, n') пространства состояний. Отсутствие эвристической силы оценки приводит к большой комбинаторной сложности алгоритма. Поэтому хотелось бы иметь такую оценку h, которая была бы нижней гранью h* (чтобы обеспечить допустимость) и, кроме того, была бы как можно ближе к h* (чтобы обеспечить эффективность). В идеальном случае, если бы нам была известна сама точная оценка h*, мы бы ее и использовали: А*-алгоритм, пользующийся h*, находит оптимальное решение сразу, без единого возврата.
ПОИСК С ПРЕДПОЧТЕНИЕМ: ЭВРИСТИЧЕСКИЙ ПОИСК
Поиск в графах при решении задач, как правило, невозможен без решения проблемы комбинаторной сложности, возникающей из-за быстрого роста числа альтернатив. Эффективным средством борьбы с этим служит эвристический поиск.
Один из путей использования эвристической информации о задаче - это получение численных эвристических оценок для вершин пространства состояний. Оценка вершины указывает нам, насколько данная вершина перспективна с точки зрения достижения цели. Идея состоит в том, чтобы всегда продолжать поиск, начиная с наиболее перспективной вершины, выбранной из всего множества кандидатов. Именно на этом принципе основана программа поиска с предпочтением, описанная в данной главе.
double_line();Поиск в ширину
В противоположность поиску в глубину стратегия поиска в ширину предусматривает переход в первую очередь к вершинам, ближайший к стартовой вершине. В результате процесс поиска имеет тенденцию развиваться более в ширину, чем в глубину, что иллюстрирует рис. 11.9.
Поиск в ширину программируется не так легко, как поиск в глубину. Причина состоят в том, что

Рис. 11. 9. Простое пространство состояний: а - стартовая вершина,
f и j - целевые вершины. Применение стратегии поиска в ширину
дает следующий порядок прохода по вершинам: а, b, c, d, e, f. Более
короткое решение [a, c, f] найдено раньше, чем более длинное
[а, b, e, j]
нам приходится сохранять все множество альтернативных вершин-кандидатов, а не только одну вершину, как при поиске в глубину. Более того, если мы желаем получить при помощи процесса поиска решающий путь, то одного множества вершин недостаточно. Поэтому мы будем хранить не множество вершин-кандидатов, а множество путей-кандидатов. Таким образом, цель
вширину( Пути, Решения)
истинна только тогда, когда существует путь из множества кандидатов Пути, который может быть продолжен вплоть до целевой вершины. Этот продолженный путь и есть Решение.
Получение структурированной информации из базы данных
Это упражнение развивает навыки представления структурных объектов данных и управления ими. Оно показывает также, что Пролог является естественным языком запросов к базе данных.
База данных может быть представлена на Прологе в виде множества фактов. Например, в базе данных о семьях каждая семья может описываться одним предложением. На рис. 4.1 показано, как информацию о каждой семье можно представить в виде структуры. Каждая семья состоит из трех компонент: мужа, жены и детей. Поскольку количество детей в разных семьях может быть разным, то их целесообразно представить в виде списка, состоящего из произвольного числа элементов. Каждого члена семьи в свою очередь можно представить структурой, состоящей из

Рис. 4. 1. Структурированная информация о семье.
четырех компонент: имени, фамилии, даты рождения и работы. Информация о работе - это либо "не работает", либо указание места работа и оклада (дохода). Информацию о семье, изображенной на рис. 4.1, можно занести в базу данных с помощью предложения:
семья( членсемьи( том, фокс, дата( 7, май, 1950),
работает( bbс, 15200) ),
членсемьи( энн, фокс, дата( 9, май, 1951), неработает),
[членсемьи( пат, фокс, дата( 5, май, 1973), неработает),
членсемьи( джим, фокс, дата( 5, май, 1973), неработает) ] ).
Тогда база данных будет состоять из последовательности фактов, подобных этому, и описывать все семьи, представляющие интерес для нашей программы.
В действительности Пролог очень удобен для извлечения необходимой информации из такой базы данных. Здесь хорошо то, что можно ссылаться на объекты, не указывая в деталях всех их компонент. Можно задавать только структуру
интересующих нас объектов и оставлять конкретные компоненты без точного описания или лишь с частичным описанием.
На рис. 4. 2 приведено несколько примеров. Так, а запросах к базе данных можно ссылаться на всех Армстронгов с помощью терма
семья( членсемьи( _, армстронг, _, _ ), _, _ )
Символы подчеркивания обозначают различные анонимные переменные, значения которых нас не заботят. Далее можно сослаться на все семьи с тремя детьми при помощи терма:
семья( _, _, [ _, _, _ ])
Чтобы найти всех замужних женщин, имеющих по крайней мере троих детей, можно задать вопрос:
?- семья( _, членсемьи( Имя, Фамилия, _, _ ), [ _, _, _ | _ ]).
Главным моментом в этих примерах является то, что указывать интересующие нас объекты можно не только по их содержимому, но и по их структуре. Мы задаем одну структуру и оставляем ее аргументы в виде слотов (пропусков).

Рис. 4. 2. Описания объектов по их структурным свойствам: (а) любая семья Армстронгов; (b) любая семья, имеющая ровно трех детей; (с) любая семья, имеющая по крайней мере три ребенка. Структура (с) дает возможность получить имя и фамилию жены конкретизацией переменных Имя и Фамилия.
Можно создать набор процедур, который служил бы утилитой, делающей взаимодействие с нашей базой данных более удобным. Такие процедуры являлись бы частью пользовательского интерфейса. Вот некоторые полезные процедуры для нашей базы данных:
муж( X) :- % X - муж
семья( X, _, _ ).
жена( X) :- % X - жена
семья( _, X, _ ).
ребенок( X) :- % X - ребенок
семья( _, _, Дети),
принадлежит( X, Дети).
принадлежит( X, [X | L ]).
принадлежит( X, [Y | L ]) :-
принадлежит( X, L).
существует( Членсемьи) :-
% Любой член семьи в базе данных
муж( Членсемьи);
жена( Членсемьи);
ребенок( Членсемьи).
дата рождения( Членсемьи( _, _, Дата, _ ), Дата).
доход( Членсемьи( _, _, _, работает( _, S) ), S).
% Доход работающего
доход( Членсемьи( _, _, _, неработает), 0).
% Доход неработающего
Этими процедурами можно воспользоваться, например, в следующих запросах к базе данных: Найти имена всех людей из базы данных:
?- существует( членсемьи( Имя,Фамилия, _, _ )).
Найти всех детей, родившихся в 1981 году:
?- ребенок( X), датарождения( X, дата( _, _, 1981) ).
Найти всех работающих жен:
?- жена( членсемьи( Имя, Фамилия, _, работает( _, _ ))).
Найти имена и фамилии людей, которые не работают и родились до 1963 года:
?- существует членсемьи( Имя, Фамилия, дата( _, _, Год), неработает) ),
Год < 1963.
Найти людей, родившихся до 1950 года, чей доход меньше, чем 8000:
?- существует( Членсемьи),
датарождения( Членсемьи, дата( _, _, Год) ),
Год < 1950,
доход( Членсемьи, Доход),
Доход < 8000.
Найти фамилии людей, имеющих по крайней мере трех детей:
?- семья( членсемьи( _, Фамилия, _, _ ), _, [ _, _, _ | _ ]). Для подсчета общего дохода семья полезно определить сумму доходов людей из некоторого списка в виде двухаргументного отношения:
общий( Список_Людей, Сумма_их_доходов)
Это отношение можно запрограммировать так:
общий( [ ], 0). % Пустой список людей
общий( [ Человек | Список], Сумма) :-
доход( Человек, S),
% S - доход первого человека
общий( Список, Остальные),
% Остальные - сумма доходов остальных
Сумма is S + Остальные.
Теперь общие доходы всех семей могут быть найдены с помощью вопроса:
?- семья( Муж, Жена, Дети),
общий( [Муж, Жена | Дети], Доход).
Пусть отношение длина подсчитывает количество элементов списка, как это было определено в разд. 3.4. Тогда мы можем найти все семьи, которые имеют доход на члена семьи, меньший, чем 2000, при помощи вопроса:
?- семья( Муж, Жена, Дети),
общий( [ Муж, Жена | Дети], Доход),
длина( [ Муж, Жена | Дети], N),
Доход/N < 2000.
Построение остовного дерева
Граф называется связным, если между любыми двумя его вершинами существует путь. Пусть G = (V, Е) - связный граф с множеством вершин V и множеством ребep Е. Остовное дерево графа G - это связный граф Т = ( V, Е'), где Е' - подмножество Е такое, что
(1) Т - связный граф,
(2) в Т нет циклов.
Выполнение этих двух условий гарантирует то, что Т - дерево. Для графа, изображенного в левой части рис. 9.18, существует три остовных дерева, соответствующих следующим трем спискам ребер:
Дер1 = [а-b, b-c, c-d]
Дер2 = [а-b, b-d, d-с]
Дер3 = [а-b, b-d, b-c]
Здесь каждый терм вида X-Y обозначает ребро, соединяющее вершины Х и Y. В качестве корня можно взять любую из вершин, указанных в списке. Остовные деревья представляют интерес, например в задачах проектирования сетей связи, поскольку они позволяют, имея минимальное число линий, установить связь между любыми двумя узлами, соответствующими вершинам графа.
Определим процедуру
остдерево( G, Т)
где Т - остовное дерево графа G. Будем предполагать, что G - связный граф. Можно представить себе алгоритмический процесс построения остовного дерева следующим образом. Начать с пустого множества ребер и постепенно добавлять новые ребра, постоянно следя за тем, чтобы не образовывались циклы. Продолжать этот процесс до тех пор, пока не обнаружится, что нельзя присоединить ни одного ребра, поскольку любое новое ребро порождает цикл. Полученное множество ребер будет остовным деревом. Отсутствие циклов можно обеспечить, если придерживаться следующего простого правила: ребро присоединяется к дереву только в том случае, когда одна из его вершин уже содержится в строящемся дереве, а другая пока еще не включена в него.
Программа, реализующая эту идею, показана на рис. 9.22. Основное отношение, используемое в этой программе, - это
расширить( Дер1, Дер, G)
Здесь все три аргумента - множества ребер. G
-
line();
% Построение остовного дерева графа
%
% Деревья и графы представлены списками
% своих ребер, например:
% Граф = [а-b, b-с, b-d, c-d]
остдерево( Граф, Дер) :-
% Дер - остовное дерево Граф'а
принадлежит( Ребро, Граф),
расширить( [Ребро], Дер, Граф).
расширить( Дер1, Дер, Граф) :-
добребро( Дер1, Дер2, Граф),
расширить( Дер2, Дер, Граф).
расширить( Дер, Дер, Граф) :-
not добребро( Дер, _, Граф).
% Добавление любого ребра приводит к циклу
добребро( Дер, [А-В | Дер], Граф) :-
смеж( А, В, Граф),
% А и В - смежные вершины
вершина( А, Дер).
% А содержится в Дер
не вершина( В, Дер).
% А-В не порождает цикла
смеж( А, В, Граф) :-
принадлежит ( А-В, Граф);
принадлежит ( В-А, Граф).
вершина( А, Граф) :-
% А содержится в графе, если
смеж( А, _, Граф).
% А смежна какой-нибудь вершине
line();
Pис. 9. 22. Построение остовного дерева: алгоритмический подход.
Предполагается, что Граф - связный граф.
связный граф; Дер1 и Дер - два подмножества G, являющиеся деревьями. Дер
- остовное дерево графа G, полученное добавлением некоторого ( может быть пустого) множества ребер из G к Дер1. Можно сказать, что "Дер1 расширено до Дер".
Интересно, что можно написать программу построения остовного дерева совершенно другим, полностью декларативным способом, просто формулируя на Прологе некоторые математические определения.
Допустим, что как графы, так и деревья задаются списками своих ребер, как в программе рис. 9.22. Нам понадобятся следующие определения:
(1) Т является остовным деревом графа G, если
Т - это подмножество графа G и
Т - дерево и
Т "накрывает" G, т.е. каждая вершина из G содержится также в Т.
(2) Множество ребер Т есть дерево, если
Т - связный граф и
Т не содержит циклов.
Эти определения можно сформулировать на Прологе (с использованием нашей программы путь
из предыдущего раздела) так, как показано на рис. 9.23. Следует, однако, заметить, что эта программа в таком ее виде не представляет практического интереса из-за своей неэффективности.
line();
% Построение остовного дерева
% Графы и деревья представлены списками ребер.
остдерево( Граф, Дер) :-
подмнож( Граф, Дер),
дерево( Дер),
накрывает( Дер, Граф).
дерево( Дер) :-
связи( Дер),
not имеетцикл( Дер).
связи( Дер) :-
not ( вершина( А, Дер), вершина( В, Дер),
not путь( А, А, Дер, _ ) ).
имеетцикл( Дер) :-
смеж( А, В, Дер),
путь( А, В, Дер, [А, X, Y | _ ).
% Длина пути > 1
накрывает( Дер, Граф) :-
not ( вершина( А, Граф), not вершина( А, Дер) ).
подмнож( [ ], [ ]).
подмнож( [ Х | L], S) :-
подмнож( L, L1),
( S = L1; S = [ Х | L1] ).
line();
Рис. 9. 23. Построение остовного дерева: "декларативный подход".
Отношения вершина и смеж
см. на рис. 9. 22.
Повышение эффективности конкатенации списков за счет совершенствования структуры данных
До сих пор в наших программах конкатенация была определена так:
конк( [ ], L, L).
конк( [X | L1], L2, [X | L3] ) :-
конк( L1, L2, L3 ).
Эта процедура неэффективна, если первый список - длинный. Следующий пример объясняет, почему это так:
?- конк( [а, b, с], [d, e], L).
Этот вопрос порождает следующую последовательность целей:
конк( [а, b, с], [d, e], L)
конк( [b, с], [d, e], L') где L = [a | L']
конк( [с], [d, e], L") где L' = [b | L"]
конк( [ ], [d, e], L'") где L" = [c | L''']
true (истина) где L'" = [d, е]
Ясно, что программа фактически сканирует весь первый список, пока не обнаружит его конец.
А нельзя ли было бы проскочить весь первый список за один шаг и сразу подсоединить к нему второй список, вместо того, чтобы постепенно продвигаться вдоль него? Но для этого необходимо знать, где расположен конец списка, а следовательно, мы нуждаемся в другом его представлении.
Один из вариантов - представлять список парой списков. Например, список
[а, b, с]
можно представить следующими двумя списками:
L1 = [a, b, c, d, e]
L2 = [d, e]
Подобная пара списков, записанная для краткости как L1-L2, представляет собой "разность" между L1 и L2. Это представление работает только при том условии, что L2 - "конечный участок" списка L1. Заметим, что один и тот же список может быть представлен несколькими "разностными парами". Поэтому список [а, b, с] можно представить как
[а, b, с]-[ ]
или
[a, b, c, d, e]-[d, e]
или
[a, b, c, d, e | T]-[d, e | T]
или
[а, b, с | Т]-Т
где Т - произвольный список, и т.п. Пустой список представляется любой парой L-L.
Поскольку второй член пары указывает на конец списка, этот конец доступен сразу. Это можно использовать для эффективной реализации конкатенации. Метод показан на рис. 8.1. Соответствующее отношение конкатенации записывается на Прологе в виде факта
конкат( A1-Z1, Z1-Z2, A1-Z2).
Давайте используем конкат для конкатенации двух списков: списка [а, b, с], представленного парой [а, b, с | Т1]-Т1, и списка [d, e], представленного парой [d, e | Т2]-Т2 :
?- конкат( [а, b, с | Т1]-T1, [d, е | Т2]-Т2, L ).
Оказывается, что для выполнения конкатенации достаточно простого сопоставления этой цели с предложением конкат. Результат сопоставления:
T1 = [d, e | Т2]
L = [a, b, c, d, e | T2]-T2
Рис. 8. 1. Конкатенация списков, представленных в виде разностных пар.
L1 представляется как A1-Z1, L2 как A2-Z2 и результат L3 - как A1-Z2.
При этом должно выполняться равенство Z1 = А2.
Повышение эффективности программы раскраски карты
Задача раскраски карты состоит в приписывании каждой стране на заданной карте одного из четырех заданных цветов с таким расчетом, чтобы ни одна пара соседних стран не была окрашена в одинаковый цвет. Существует теорема, которая гарантирует, что это всегда возможно.
Пусть карта задана отношением соседства
соседи( Страна, Соседи)
где Соседи - список стран, граничащих со страной Страна. При помощи этого отношения карта Европы с 20-ю странами будет представлена (в алфавитном порядке) так:
соседи( австрия, [венгрия, запгермания, италия,
лихтенштейн, чехословакия,
швейцария, югославия]),
соседи( албания, [греция, югославия]).
соседи( андорра, [испания, франция]).
. . .
Решение представим в виде списка пар вида
Страна / Цвет
которые устанавливают цвет для каждой страны на данной карте. Для каждой карты названия стран всегда известны заранее, так что задача состоит в нахождении цветов. Таким образом, для Европы задача сводится к отысканию подходящей конкретизации переменных C1, C2, СЗ и т.д. в списке
[австрия/C1, албания/С2, андорра/С3, . . .]
Теперь определим предикат
цвета( СписЦветСтран)
который истинен, если СписЦветСтран
удовлетворяет тем ограничениям, которые наложены на раскраску отношением соседи.
Пусть четырьмя цветами будут желтый, синий, красный и зеленый. Условие запрета раскраски соседних стран в одинаковый цвет можно сформулировать на Прологе так:
цвета( [ ]).
цвета( [Страна/Цвет | Остальные] ) :-
цвета( Остальные),
принадлежит( Цвет, [желтый, синий, красный, зеленый]),
not( принадлежит( Страна1/Цвет, Остальные),
сосед( Страна, Страна1) ).
сосед( Страна, Страна1) :-
соседи( Страна, Соседи),
принадлежит( Страна1, Соседи).
Здесь принадлежит( X, L) - как всегда, отношение принадлежности к списку. Для простых карт с небольшим числом стран такая программа будет работать. Что же касается Европы, то здесь результат проблематичен. Если считать, что мы располагаем встроенным предикатом setof, то можно попытаться раскрасить карту Европы следующим образом. Определим сначала вспомогательное отношение:
страна( С) :- соседи( С, _ ).
Тогда вопрос для раскраски карты Европы можно сформулировать так:
?- sеtоf( Стр/Цвет, страна( Стр), СписЦветСтран),
цвета( СписЦветСтран).
Цель setof - построить "шаблон" списка СписЦветСтран, в котором в элементах вида страна/ цвет вместо цветов будут стоять неконкретизированные переменные.
Предполагается, что после этого цель цвета
конкретизирует их. Такая попытка скорее всего потерпит неудачу вследствие неэффективности работы программы.
Тщательное исследование способа, при помощи которого пролог-система пытается достичь цели цвета, обнаруживает источник неэффективности. Страны расположены в списке в алфавитном порядке, а он не имеет никакого отношения к их географическим связям. Порядок, в котором странам приписываются цвета, соответствует порядку их расположения в списке (с конца к началу), что в нашем случае никак не связано с отношением соседи. Поэтому процесс раскраски начинается в одном конце карты, продолжается в другой и т.д., перемещаясь по ней более или менее случайно. Это легко может привести к ситуации, когда при попытке раскрасить очередную страну окажется, что она окружена странами, уже раскрашенными во все четыре доступных цвета. Подобные ситуации приводят к возвратам, снижающим эффективность.
Ясно поэтому, что эффективность зависит от порядка раскраски стран. Интуиция подсказывает простую стратегию раскраски, которая должна быть лучше, чем случайная: начать со страны, имеющей иного соседей, затем перейти к ее соседям, затем - к соседям соседей и т.д. В случае Европы хорошим кандидатом для начальной страны является Западная Германия (как имеющая наибольшее количество соседей - 9). Понятно, что при построении шаблона списка элементов вида страна/цвет Западную Германию следует поместить в конец этого списка, а остальные страны - добавлять со стороны его начала. Таким образом, алгоритм раскраски, который начинает работу с конца списка, в начале займется Западной Германией и продолжит работу, переходя от соседа к соседу.
Новый способ упорядочивания списка стран резко повышает эффективность по отношению к исходному, алфавитному порядку, и теперь возможные раскраски карты Европы будут получены без труда.
Можно было бы построить такой правильно упорядоченный список стран вручную, но в этом нет необходимости. Эту работу выполнит процедура создспис.
Она начинает построение с некоторой указанной страны (в нашем случае - с Западной Германии) и собирает затем остальные страны в список под названием Закрытый. Каждая страна сначала попадает в другой список, названный Открытый, а потом переносится в Закрытый. Всякий раз, когда страна переносится из Открытый
в Закрытый, ее соседи добавляются в Открытый.
создспис( Спис) :-
собрать( [запгермания], [ ], Спис ).
собрать( [ ], Закрытый, Закрытый).
% Кандидатов в Закрытый больше нет
собрать( [X | Открытый], Закрытый, Спис) :-
принадлежит( Х | Закрытый), !,
% Х уже собран ?
собрaть( Открытый, Закрытый, Спис).
% Отказаться от Х
собрать( [X | Открытый], Закрытый, Спис) :-
соседи( X, Соседи),
% Найти соседей Х
конк( Соседи, Открытый, Открытый1),
% Поместить их в Открытый
собрать( Открытый1, [X | Закрытый], Спис).
% Собрать остальные
Отношение конк - как всегда - отношение конкатенации списков.
Повышение эффективности решения задачи о восьми ферзях
В качестве простого примера повышения эффективности давайте вернемся к задаче о восьми ферзях (см. рис. 4.7). В этой программе Y-координаты ферзей перебираются последовательно - для каждого ферзя пробуются числа от 1 до 8. Этот процесс был запрограммирован в виде цели
принадлежит( Y, [1, 2, 3, 4, 5, 6, 7, 8] )
Процедура принадлежит работает так: вначале пробует Y = 1, затем Y = 2, Y = 3 и т.д. Поскольку ферзи расположены один за другим в смежных вертикалях доски, очевидно, что такой порядок перебора не является оптимальным. Дело в том, что ферзи, расположенные в смежных вертикалях будут бить друг друга, если они не будут разнесены по вертикали на расстояние, превышающее, по крайней мере одно поле. В соответствии с этим наблюдением можно попытаться повысить эффективность, просто изменив порядок рассмотрения координат-кандидатов. Например:
принадлежит( Y, [1, 5, 2, 6, 3, 7, 4, 8] )
Это маленькое изменение уменьшит время, необходимое для нахождения первого решения, в 3-4 раза.
В следующем примере такая же простая идея, связанная с изменением порядка, превращает практически неприемлемую временную сложность в тривиальную.
Повышение эффективности зa счет добавления вычисленных фактов к базе данных
Иногда в процессе вычислений приходится одну и ту же цель достигать снова и снова. Поскольку в Прологе отсутствует специальный механизм выявления этой ситуации, соответствующая цепочка вычислений каждый раз повторяется заново.
В качестве примера рассмотрим программу вычисления N-го числа Фибоначчи для некоторого заданного N. Последовательность Фибоначчи имеет вид:
1, 1, 2, 3, 5, 8, 13, ...
Каждый член последовательности, за исключением первых двух, представляет собой сумму предыдущих двух членов. Для вычисления N-гo числа Фибоначчи F определим предикат
фиб( N, F)
Нумерацию чисел последовательности начнем с N = 1. Программа для фиб обрабатывает сначала первые два числа Фибоначчи как два особых случая, а затем определяет общее правило построения последовательности Фибоначчи:
фиб( 1, 1). % 1-е число Фибоначчи
фиб( 2, 1). % 2-е число Фибоначчи
фиб( N, F) :-
% N-е число Фиб., N > 2
N > 2,
N1 is N - 1, фиб( N1, F1),
N2 is N - 2, фиб( N2, F2),
F is F1 + F2.
% N-e число есть сумма двух
% предыдущих
Процедура фиб имеет тенденцию к повторению вычислений. Это легко увидеть, если трассировать цель
?- фиб( 6, F).
На рис. 8.2 показано, как протекает этот вычислительный процесс. Например, третье число Фибоначчи f( 3) понадобилось в трех местах, и были повторены три раза одни и те же вычисления.
Этого легко избежать, если запоминать каждое вновь вычисленное число. Идея состоит в применении встроенной процедуры assert
для добавления этих (промежуточных) результатов в базу данных в виде фактов. Эти факты должны предшествовать другим предложениям, чтобы предотвратить применение общего правила в случаях, для которых результат уже известен. Усовершенствованная процедура фиб2
отличается от фиб только этим добавлением:
фиб2( 1, 1).
% 1-е число Фибоначчи
фиб2( 2, 1).
% 2-е число Фибоначчи
фиб2( N, F) :-
% N-e число Фиб., N > 2
N > 2,
Nl is N - 1, фиб2( N1, F1),
N2 is N - 2, фиб2( N2, F2),
F is F1 + F2,
% N-e число есть сумма
% двух предыдущих
asserta( фиб2( N, F) ). % Запоминание N-го числа
Эта программа, при попытке достичь какую-либо цель, будет смотреть сперва на накопленные об этом отношении факты и только после этого применять общее правило. В результате, после вычисления цели фиб2( N, F), все числа Фибоначчи вплоть до N-го будут сохранены. На рис. 8.3 показан процесс вычислении 6-го числа при помощи фиб2. Сравнение этого рисунка с рис. 8.2. показывает, на сколько уменьшилась вычислительная сложность. Для больших N такое уменьшение еще более ощутимо.
Запоминание промежуточных результатов - стандартный метод, позволяющий избегать повторных вычислений. Следует, однако, заметить, что в случае чисел Фибоначчи повторных вычислений можно избежать еще и применением другого алгоритма, а не только запоминанием промежуточных результатов.
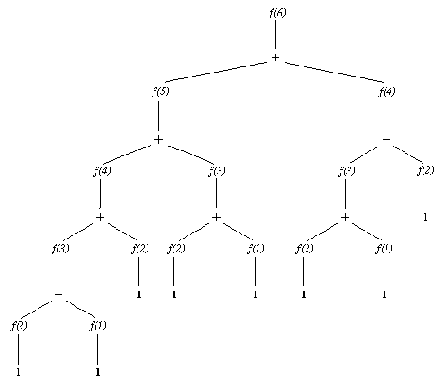
Рис. 8. 2. Вычисление 6-го числа Фибоначчи процедурой фиб.

Рис. 8. 3. Вычисление 6-го числа Фибоначчи при помощи процедуры фиб2, которая запоминает предыдущие результаты. По сравнению с процедурой фиб здесь вычислений меньше (см. рис. 8.2).
Этот новый алгоритм позволяет создать программу более трудную для понимания, зато более эффективную. Идея состоит на этот раз не в том, чтобы определить N-e число Фибоначчи просто как сумму своих предшественников по последовательности, оставляя рекурсивным вызовам организовать вычисления "сверху вниз" вплоть до самых первых двух чисел.
Вместо этого можно работать "снизу вверх": начать с первых двух чисел и продвигаться вперед, вычисляя члены последовательности один за другим. Остановиться нужно в тот момент, когда будет достигнуто N-e число. Большая часть работы в такой программе выполняется процедурой
фибвперед( М, N, F1, F2, F)
Здесь F1 и F2 - (М - 1)-е и М-е числа, а F - N-e число Фибоначчи. Рис. 8.4 помогает понять отношение фибвперед. В соответствии с этим рисунком фибвперед находит последовательность преобразований для достижения конечной конфигурации (в которой М = N) из некоторой заданной начальной конфигурации. При запуске фибвперед все его аргументы, кроме F, должны быть конкретизированы, а М должно быть меньше или равно N. Вот эта программа:
фиб3( N, F) :-
фибвперед( 2, N, 1, 1, F).
% Первые два числа Фиб. равны 1
фибвперед( М, N, F1, F2, F2) :-
М >= N. % N-e число достигнуто
фибвперед( M, N, F1, F2, F) :-
M < N, % N-e число еще не достигнуто
СледМ is М + 1,
СледF2 is F1 + F2,
фибвперед( СледМ, N, F2, СледF2, F).
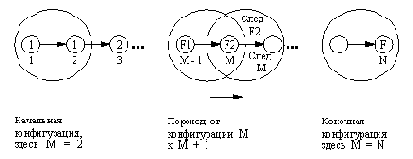
Рис. 8. 4. Отношения в последовательности Фибоначчи. "Конфигурация" изображается
здесь в виде большого круга и определяется тремя параметрами: индексом М и двумя
последовательными числами f( M-1) и f( М).
Правила и таблицы советов
В Языках Советов отдельные элементарные советы объединяются в полную схему представления знаний, имеющую следующую иерархическую структуру. Элементарный совет является частью "если-то"-правила. Набор "если-то"-правил образует таблицу советов. Множество таблиц советов имеет структуру иерархической сети. Каждая таблица советов выполняет роль эксперта в своей узкой области и работает с какой-нибудь специфической подзадачей. Примером такого специализированного эксперта может служить таблица советов, содержащая знания о том, как поставить мат королем и ладьей. Эта таблица вызывается в том случае, когда в процессе игры возникает соответствующее окончание.
Мы рассмотрим здесь упрощенную версию Языка Советов, допускающую только одну таблицу советов. Будем называть эту версию Язык Советов 0 или, для краткости, AL0 (Advice Language 0). Ниже описывается структура языка AL0, синтаксически специально приспособленная для удобной реализации на Прологе.
Программа на AL0 называется таблицей советов. Таблица советов представляет из себя упорядоченное множество "если-то"-правил. Каждое правило имеет вид:
ИмяПравила: если Условие то СписокСоветов
Условие - это логическое выражение, состоящее из имен предикатов, соединенных между собой логическими связками и, или, не. СписокСоветов - список имен элементарных советов. Приведем пример правила под названием "правило_края" из окончания "король и ладья против короля":
правило_края:
если король_противника_на_краю и короли_рядом
то [мат_2, потеснить, приблизиться,
сохранить_простр, отделить].
В этом правиле говорится: если в текущей позиции король противника находится на краю доски, а король игрока расположен близко к королю противника (точнее, расстояние между королями меньше четырех клеток), то попытаться выполнить в указанном порядке предпочтения следующие советы: "мат_2", "потеснить", "приблизиться", "сохранить_простр", "отделить". Элементарные советы расположены в порядке убывания их "притязаний" на успех: сначала попытаться поставить мат в два хода, если не получится - "потеснить" короля противника в угол и т.д. Обратите внимание на то, что при соответствующем определении операторов наше правило станет синтаксически корректным предложением Пролога.
Для представления элементарных советов в виде прологовских предложений предназначен еще один формат:
совет( ИмяСовета,
ГлавнаяЦель:
ЦельПоддержка:
ХодыИгрока:
ХодыПротивника).
Цели представляются как выражения, состоящие из имен предикатов и логических связок и, или, не. Ограничения на ходы сторон - это тоже выражения, состоящие из имен предикатов и связок и и затем: связка и имеет обычный логический смысл, а затем задает порядок. Например, ограничение, имеющее вид
Огр1 затем Огр2
означает: сначала рассмотреть ходы, удовлетворяющие ограничению Oгp1, а затем - ходы, удовлетворяющие Огр2.
Например, элементарный совет, относящийся к мату в два хода в окончании "король и ладья против короля", записанный в такой синтаксической форме, имеет вид:
совет( мат_2,
мат:
не потеря_ладьи:
(глубина = 0) и разреш затем
(глубина = 2) и ход_шах :
(глубина = 1) и разреш ).
Здесь главная цель - мат, цель-поддержка не потеря_ладьи. Ограничение на ходы игрока означает: на глубине 0 (т. е. в текущей позиции) попробовать любой разрешенный ход и затем на глубине 2 (следующий ход игрока) пробовать только ходы с шахом. Глубина измеряется в полуходах. Ограничение на ходы противника: любой разрешенный ход на глубине 1.
В процессе игры таблица советов используется многократно вплоть до окончания игры, при этом выполняется следующий основной цикл: построить форсированное дерево, затем играть в соответствии с этим деревом, пока не произойдет выход из него; построить другое форсированное дерево и т.д. Форсированное дерево строится каждый раз таким образом: берется текущая позиция Поз и просматриваются одно за другим все правила таблицы советов; для каждого правила сопоставляется Поз с предварительным условием этого правила и просмотр прекращается, когда будет обнаружено правило, для которого Поз удовлетворяет предварительному условию. В этом случае надо рассмотреть список советов найденного правила: обработать элементарные советы один за другим, пока не будет построено форсированное дерево, представляющее собой детальную стратегию игры в этой позиции.
Следует обратить внимание на существенность того порядка, в котором перечисляются правила в таблице советов.Правило, которое реально используется, - это первое из тех правил, предварительные уловия которых согласуются с текущей позицией. Для любой возможной позиции должно существовать по крайней мере одно такое правило. Из него берется список советов, и первый из выполнимых советов списка используется в игре.
Таким образом, таблица советов это программа в высшей степени непроцедурного характера. Интерпретатор языка AL0 принимает на входе некоторую позицию, а затем, "исполняя" таблицу советов, строит форсированное дерево, определяющее стратегию игры в этой позиции.
Назад | Содержание | Вперёд
Правила типа "если-то" для представления знаний
В качестве кандидата на использование в экспертной системе можно рассматривать, в принципе, любой непротиворечивый формализм, в рамках которого можно описывать знания о некоторой проблемной области. Однако самым популярным формальным языком представления знаний является язык правил типа "если-то" (или кратко: "если-то"-правил), называемых также продукциями. Каждое такое правило есть, вообще говоря, некоторое условное утверждение, но возможны и различные другие интерпретации. Вот примеры: если предварительное условие Р то заключение (вывод) С если ситуация S то действие А если выполнены условия С1 и С2 то не выполнено условие С
"Если-то"-правила обычно оказываются весьма естественным выразительным средством представления знаний. Кроме того, они обладают следующими привлекательными свойствами: Модульность: каждое правило описывает небольшой, относительно независимый фрагмент знаний. Возможность инкрементного наращивания: добавление новых правил в базу знаний происходит относительно независимо от других правил. Удобство модификации (как следствие модульности): старые правила можно изменять и заменять на новые относительно независимо от других правил. Применение правил способствует прозрачности системы.
Последнее свойство - это важное, отличительное свойство экспертных систем. Под прозрачностью мы понимаем способность системы к объяснению принятых решений и полученных результатов. Применение "если-то"-правил облегчает получение ответов на следующие основные типы вопросов пользователя:
(1) Вопросы типа "как": Как вы пришли к этому выводу?
(2) Вопросы типа "почему": Почему вас интересует эта информация?
Механизмы, основанные на "если-то"-правилах, для формирования ответов на подобные вопросы мы обсудим позже.
line(); если
1 тип инфекции - это первичная бактериемия и
2 материал для посева был отобран стерильно, и
3 предполагаемые ворота инфекции - желудочно- кишечный тракт
то
имеются веские аргументы (0.7) за то,
что инфекционный агент является бактерией
line(); Рис. 14. 2. "Если-то"-правило медицинской консультативной системы
MYCIN (Shortliffe, 1976). Параметр 0.7 показывает степень доверия
этому правилу.
"Если-то"-правила часто применяют для определения логических отношений между понятиями предметной области. Про чисто логические отношения можно сказать, что они принадлежат к "категорическим знаниям", "категорическим" - потому, что соответствующие утверждения всегда, абсолютно верны. Однако в некоторых предметных областях, таких, как медицинская диагностика, преобладают "мягкие" или вероятностные знания. Эти знания являются "мягкими"; в том смысле, что говорить об их применимости к любым практическим ситуациям можно только до некоторой степени ("часто, но не всегда"). В таких случаях используют модифицированные "если-то"-правила, дополняя их логическую интерпретацию вероятностной оценкой. Например:
если условие А то заключение В с уверенностью F
Рис. 14.2, 14.3 и 14.4 дают представление о разнообразии способов, которыми знания могут быть выражены при помощи "если-то"-правил. На этих рисунках приведены примеры правил из трех различных систем, основанных на знаниях: медицинской консультативной системы MYCIN, системы AL/X для диагностики неисправностей в оборудовании и системы AL3 для решения шахматных задач.
Вообще говоря, если вы хотите разработать серьезную экспертную систему для некоторой выбранной вами предметной области, вы должны провести консультации с экспертами в этой области и многое узнать о ней сами. Достигнуть определенного понимания предметной области после общения с экспертами и чтения литературы, а затем облечь это понимание в форму представления знаний в рамках выбранного формального языка - это искусство, называемое инженерией знаний. Как правило, это сложная задача, требующая больших усилий, чего мы не можем себе позволить в данной книге. Но какая-нибудь предметная область и какая-нибудь база данных нам необходимы в качестве материала для экспериментов. С практической точки зрения нам для этой цели вполне подойдет "игрушечная" база знаний. На рис. 14.5 показана часть такой базы знаний. Она состоит из простых правил, помогающих идентифицировать животных по их основным признаками в предположении, что задача идентификации ограничена только небольшим числом разных животных.
Правила, содержащиеся в базе знаний, имеют вид
ИмяПравила : если Условие то Заключение
где Заключение - это простое утверждение, а
line(); если
давление в v-01 достигло уровня открытия
выпускного клапана
то
выпускной клапан в v-01 открылся
[N=0.005, S=400]
если
давление в v-01 не достигло уровня открытия
выпускного клапана и выпускной клапан в v-01
открылся
то
преждевременное открытие выпускного клапана
(сместилась установка порогового давления)
[N=0.001, S=2000]
line(); Рис. 14. 3. Два правила из демонстрационной базы знаний системы
AL/X для диагностики неисправностей (Reiter 1980). N и S -
величины "необходимости" и "достаточности", детально описанные
в разд. 14.7. Величина S указывает степень, с которой условие
влечет за собой заключение (вывод). Величина N указывает, до
какой степени истинность условия необходима для того, чтобы
заключение было истинным.
line(); если
1 существует гипотеза H, что план Р ведет к
успеху, и
2 существуют две гипотезы
H1, что план Р1 опровергает план Р, и
Н2, что план Р2 опровергает план Р, и
3 имеют место факты: гипотеза H1 ложна и
гипотеза Н2 ложна
то
1 породить гипотезу Н3, что составной план "Р1
или Р2" опровергает план Р, и
2 породить факт: из Н3 следует не( Н)
line(); Рис. 14. 4. Правило уточнения плана из системы AL3
для решения шахматных задач (Bratko 1982).
Условие - это набор простых утверждений, соединенных между собой операторами и и или. Мы также разрешим в части условия использовать оператор не, хотя и с некоторыми оговорками. При надлежащем прологовском определении этих операторов (как это сделано на рис. 14.5) правила станут синтаксически верными предложениями Пролога. Заметим, что оператор и связывает операнды сильнее, чем или, что соответствует обычным соглашениям.
line(); % Небольшая база знаний для идентификации животных
:- ор( 100, xfx, [имеет, 'кормит детенышей',
'не может', ест, откладывает, это]).
:- ор( 100, xf, [плавает, летает, хорошо]).
прав1: если
Животное имеет шерсть
или
Животное 'кормит детенышей' молоком
то
Животное это млекопитающее.
прав2: если
Животное имеет перья
или
Животное летает и
Животное откладывает яйца
то
Животное это птица.
прав3: если
Животное это млекопитающее и
( Животное ест мясо
или
Животное имеет 'острые зубы' и
Животное имеет когти и
Животное имеет
'глаза, направленные вперед' )
то
Животное это хищник.
прав4: если
Животное это хищник и
Животное имеет
'рыжевато-коричневый цвет' и
Животное имеет 'темные пятна'
то
Животное это гепард.
прав5: если
Животное это хищник и
Животное имеет
'рыжевато-коричневый цвет' и
Животное имеет 'черные полосы'
то
Животное это тигр,
прав6: если
Животное это птица и
Животное 'не может' летать и
Животное плавает
то
Животное это пингвин,
прав7: если
Животное это птица и
Животное летает хорошо
то
Животное это альбатрос.
факт: X это животное :-
принадлежит( X, [гепард, тигр, пингвин, альбатрос]).
можно_спросить( _ 'кормит детенышей'_,
'Животное' 'кормит детенышей' 'Чем').
можно_спросить( _ летает, 'Животное' летает).
можно_спросить( _ откладывает яйца,
'Животное' откладывает яйца).
можно_спросить( _ ест _, 'Животное' ест 'Что').
можно_спросить( _ имеет _,'Животное' имеет 'Нечто').
можно_спросить( _ 'не может' _,
'Животное' 'не может' 'Что делать').
можно_спросить( _ плавает, 'Животное' плавает).
можно_спросить( _ летает хорошо,
'Животное' летает хорошо).
line(); Рис. 14. 5. Простая база знаний для идентификации животных.
Заимствовано из Winston (1984). Отношение "можно_спросить"
определяет вопросы, которые можно задавать пользователю.
Операторы если, то, и, или определены на рис. 14.10.
Рассмотрим еще одну небольшую базу знаний, которая может помочь локализовать неисправности в простой электрической схеме, состоящей из электрических приборов и предохранителей. Электрическая схема показана на рис. 14.6. Вот одно из возможных правил:
если
лампа1 включена и
лампа1 не работает и
предохранитель1 заведомо цел
то
лампа1 заведомо неисправна.
Вот другой пример правила:
если
радиатор работает
то
предохранитель1 заведомо цел.
Эти два правила опираются на некоторые факты (относящиеся к нашей конкретной схеме), а именно что лампа1 соединена с предохранитель1 и что лампа1 и радиатор имеют общий предохранитель.
Для другой схемы нам понадобится еще один набор правил. Поэтому было бы лучше сформулировать правила в более общем виде (используя прологовские переменные) так, чтобы они были применимы к любой схеме, а затем уже дополнять их информацией о конкретной схеме. Например, вот одно из полезных правил: если прибор включен, но не работает, а соответствующий предохранитель цел, то прибор неисправен. На наш
Рис. 14. 6. Соединения между предохранителями и приборами в
простой электрической схеме.
формальный язык это транслируется так:
правило_поломки:
если
Прибор включен и
не (Прибор работает) и
Прибор соединен с Предохранитель и
Предохранитель заведомо цел
то
Прибор заведомо неисправен.
База знаний такого рода показана на рис. 14. 7.
Предикаты var, nоnvar, atom, integer, atomic
Термы бывают разных типов: переменные, целые числа, атомы и т.д. Если терм - переменная, то в некоторый момент выполнения программы он может оказаться конкретизированным или не конкретизированным. Далее, если он конкретизирован, то его значение может быть атомом, структурой и т. п. Иногда бывает полезно узнать, каков тип этого значения. Например, пусть мы хотим сложить значения двух переменных Х и Y:
Z is X + Y
Перед вычислением этой цели необходимо, чтобы Х и Y были конкретизированы целыми числами. Если у нас нет уверенности в том, что Х и Y действительно конкретизированы целыми числами, то перед выполнением арифметического действия нужно проверить это программно.
Для этого следует воспользоваться встроенным предикатом integer (целое). Предикат integer( X) принимает значение истина, если Х - целое или если Х - переменная, имеющая целое значение. Будем говорить в этом случае, что Х "обозначает" целое. Цель для сложения Х и Y можно тогда "защитить" такой проверкой переменных Х и Y:
. . ., integer( X), integer( Y), Z is X + Y, . . .
Если неверно, что X и Y оба являются целыми, то система и не будет пытаться их сложить. Таким образом, цели integer "охраняют" цель Z is Х + Y от бессмысленного вычисления.
Встроенные предикаты этого типа таковы: var (переменная), nonvar (непеременная), atom (атом), integer (целое), atomic (атомарный). Они имеют следующий смысл:
var( X)
Эта цель успешна, если Х в текущий момент - не конкретизированная переменная.
nonvar( X)
Эта цель успешна, если Х - терм, отличный от переменной, или если Х - уже конкретизированная переменная.
atom( X)
Эта цель истинна, если Х обозначает атом.
integer( X)
Цель истинна, если Х обозначает целое.
atomic( X)
Цель истинна, если Х обозначает целое или атом.
Следующие примеры вопросов к пролог- системе иллюстрируют применение этих встроенных предикатов:
?- var( Z), Z = 2.
Z = 2
?- Z = 2, var( Z).
no
?- integer( Z), Z = 2.
no
?- Z = 2, integer( Z), nonvar( Z).
Z = 2
?- atom( 22).
no
?- atomic( 22).
yes
?- atom( ==>).
yes
?- atom( p( 1) ).
no
Необходимость в предикате atom продемонстрируем на следующем примере. Пусть мы хотим подсчитать, сколько раз заданный атом встречается в некоторой списке объектов. Для этого мы определим процедуру
счетчик( А, L, N)
где А - атом, L - список и N - количество вхождений этого атома. В качестве первой попытки можно было бы определить счетчик так:
счетчик( _, [ ], 0).
счетчик( A, [A | L], N) :- !,
счетчик( A, L, N1),
% N1 - число вхождений атома в хвост
N is N1 + 1.
счетчик( А, [ _ | L], N) :-
счетчик( A, L, N).
Теперь на нескольких примерах посмотрим, как эта процедура работает:
?- счетчик( а, [а, b, а, а], N).
N = 3
?- счетчик( a, [a, b, X, Y], Na).
Na = 3
. . .
?- счетчик( b, [a, b, X, Y], Nb).
Nb = 3
. . .
?- L=[a, b, Х, Y], счетчик( а, L, Na), счетчик( b, L, Nb).
Na = 3
Nb = 1
X = a
Y = a
. . .
В последнем примере как X, так и Y после конкретизации получили значение а, и поэтому Nb оказалось равным только 1, однако мы хотели не этого. Нас интересовало количество реальных появлений конкретного атома, а вовсе не число термов, сопоставимых с этим атомом. В соответствии с этим более точным определением отношения счетчик мы должны теперь проверять, является ли голова списка атомом. Усовершенствованная программа выглядит так:
счетчик( _, [ ], 0).
счетчик( А, [В | L], N) :-
atom( В), А = В, !, % B равно атому А?
счетчик( A, L, N1), % Подсчет в хвосте
N is N1 + 1;
счетчик( А, L, N).
% Иначе - подсчитать только в хвосте
В следующем более сложном упражнении по программированию числовых ребусов используется предикат nonvar.
В средние века знание латинского
В средние века знание латинского и греческого языков являлось существенной частью образования любого ученого. Ученый, владеющий только одним языком, неизбежно чувствовал себя неполноценным, поскольку он был лишен той полноты восприятия, которая возникает благодаря возможности посмотреть на мир сразу с двух точек зрения. Таким же неполноценным ощущает себя сегодняшний исследователь в области искусственного интеллекта, если он не обладает основательным знакомством как с Лиспом, так и с Прологом - с этими двумя основополагающими языками искусственного интеллекта, без знания которых невозможен более широкий взгляд на предмет исследования.
Сам я приверженец Лиспа, так как воспитывался в Массачусетском технологическом институте, где этот язык был изобретен. Тем не менее, я никогда не забуду того волнения, которое я испытал, увидев в действии свою первую программу, написанную в прологовском стиле. Эта программа была частью знаменитой системы Shrdlu Терри Винограда. Решатель задач, встроенный в систему, работал в "мире кубиков" и заставлял руку робота (точнее, ее модель) перемещать кубики на экране дисплея, решая при этом хитроумные задачи, поставленные оператором.
Решатель задач Винограда был написан на Микропленнере, языке, который, как мы теперь понимаем, был своего рода Прологом в миниатюре. Любой прологоподобный язык заставляет программиста мыслить в терминах целей, поэтому, несмотря на все недостатки Микропленнера, достоинством этой программы было то, что в ее структуре содержались многочисленные явные указания на те или иные цели. Процедуры-цели "схватить", "освободить", "избавиться", "переместить", "отпустить" и т.п. делали программу простой и компактной, а поведение ее казалось поразительно разумным.
Решатель задач Винограда навсегда изменил мое программистское мышление. Я даже переписал его на Лиспе и привел в своем учебнике по Лиспу в качестве примера - настолько эта программа всегда поражала меня мощью заложенной в ней философии "целевого" программирования, да и само программирование в терминах целей всегда доставляло мне удовольствие.
Однако учиться целевому программированию на примерах лисповских программ - это все равно, что читать Шекспира на языке, отличном от английского. Какое-то впечатление вы получите, но сила эстетического воздействия будет меньшей, чем при чтении оригинала. Аналогично этому, лучший способ научиться целевому программированию - это читать и писать программы на Прологе, поскольку сама сущность Пролога как раз и состоит в программировании в терминах целей.
В самом широком смысле слова эволюция языков программирования - это движение от языков низкого уровня, пользуясь которыми, программист описывает, как что-либо следует делать, к языкам высокого уровня, на которых просто указывается, что необходимо сделать. Так, например, появление Фортрана освободило программистов от необходимости разговаривать с машиной на прокрустовом языке адресов и регистров. Теперь они уже могли говорить на своем (или почти на своем) языке, только изредка делая уступки примитивному миру 80-колонных перфокарт.
Однако Фортран и почти все другие языки программирования все еще остаются языками типа "как". И чемпионом среди этих языков является, пожалуй, современный модернизированный Лисп. Так, скажем, Common Lisp, имея богатейшие выразительные возможности, разрешает программисту описывать наиболее "выразительно" именно то, как что-либо следует делать. В то же время очевидно, что Пролог порывает с традициями языков типа "как", поскольку он определенным образом направляет программистское мышление, заставляя программиста давать определения ситуаций и формулировать задачи вместо того, чтобы во всех деталях описывать способ решения этих задач.
Отсюда следует, насколько важен вводный курс по Прологу для всех студентов, изучающих вычислительную технику и программирование - просто не существует лучшего способа понять, что из себя представляет программирование типа "что".
Многие страницы этой книги могут служить хорошей иллюстрацией того различия, которое существует между этими двумя стилями программистского мышления.
Например, в первой главе это различие иллюстрируется на задачах, относящихся к семейным отношениям. Прологовский программист дает простое и естественное описание понятия "дедушка": дедушка -это отец родителя. На Прологе это выглядит так:
дедушка( X, Z) :- отец( X, Y), родитель( Y, Z).
Как только пролог-система узнала, что такое дедушка, ей можно задать вопрос, например: кто является дедушкой Патрика? В обозначениях Пролога этот вопрос и типичный ответ имеют вид:
?- дедушка( X, патрик).
X = джеймс;
X = карл.
Каким образом решать эту задачу, как "прочесывать" базу данных, в которой записаны все известные отношения "отец" и "родитель", - это уже забота самой пролог-системы. Программист только сообщает системе то, что ему известно, и задает вопросы. Его в большей степени интересуют знания и в меньшей - алгоритмы, при помощи которых из этих знаний извлекается нужная информация.
Поняв, что очень важно научиться Прологу, естественно задать себе следующий вопрос - как это сделать. Я убежден, что изучение языка программирования во многом сходно с изучением естественного языка. Так, например, в первом случае может пригодиться инструкция по программированию точно так же, как во втором - словарь. Но никто не изучает язык при помощи словаря, так как слова - это только часть знаний, необходимых для овладения языком. Изучающий язык должен кроме того узнать те соглашения, следуя которым, можно получать осмысленные сочетания слов, а затем научиться у мастеров слова искусству литературного стиля.
Точно так же, никто не изучает язык программирования, пользуясь только инструкцией по программированию, так как в инструкциях очень мало или вообще ничего не говорится о том, как хорошие программисты используют элементарные конструкции языка. Поэтому необходим учебник, причем лучшие учебники обычно предлагают читателю богатый набор примеров.
Ведь в хороших примерах сконцентрирован опыт лучших программистов, а именно на опыте мы, в основном, и учимся.
В этой книге первый пример появляется уже на первой странице, а далее на читателя как из рога изобилия обрушивается поток примеров прологовских программ, написанных программистом-энтузиастом, горячим приверженцем прологовской идеологии программирования. После тщательного изучения этих примеров читатель не только узнает, как "работает" Пролог, но и станет обладателем личной коллекции программ-прецедентов, готовых к употреблению: он может разбирать эти программы на части, приспосабливать каждую часть к своей задаче, а затем снова собирать их вместе, получая при этом новые программы. Такое усвоение предшествующего опыта можно считать первым шагом на пути от новичка к программисту-мастеру.
Изучение хороших программных примеров дает, как правило, один полезный побочный эффект: мы узнаем из них не только очень многое о самом программировании, но и кое-что - о какой-нибудь интересной научной области. В данной книге такой научной областью, стоящей за большинством примеров, является искусственный интеллект. Читатель узнает о таких идеях в области автоматического решения задач, как сведение задач к подзадачам, прямое и обратное построение цепочки рассуждений, ответы на вопросы "как" и "почему", а также разнообразные методы поиска.
Одним из замечательных свойств Пролога является то, что это достаточно простой язык, и студенты могли бы использовать его непосредственно в процессе изучения вводного курса по искусственному интеллекту. Я не сомневаюсь, что многие преподаватели включат эту книгу в свои курсы искусственного интеллекта с тем, чтобы студенты смогли увидеть, как при помощи Пролога абстрактные идеи приобретают конкретные и действенные формы.
Полагаю, что среди учебников по Прологу эта книга окажется особенно популярной, и не только из-за своих хороших примеров, но также из-за целого ряда других своих привлекательных черт: тщательно составленные резюме появляются на всем протяжении книги; все вводимые понятия подкрепляются многочисленными упражнениями; процедуры выборки элементов структур подводят нас к понятию абстракции данных; обсуждение вопросов стиля и методологии программирования занимает целую главу; автор не только показывает приятные свойства языка, но и со всей откровенностью обращает наше внимание на трудные проблемы, возникающие при программировании на Прологе. Все это говорит о том, что перед нами прекрасно написанная, увлекательная и полезная книга.
Патрик Г. Уинстон
Кеймбридж, Массачусетс
Январь 1986
Назад | Содержание | Вперёд
Язык программирования Пролог базируется на
Язык программирования Пролог базируется на ограниченном наборе механизмов, включающих в себя сопоставление образцов, древовидное представление структур данных и автоматический возврат. Этот небольшой набор образует удивительно мощный и гибкий программный аппарат. Пролог особенно хорошо приспособлен для решения задач, в которых фигурируют объекты (в частности, структуры) и отношения между ними. Например, в качестве легкого упражнения, можно попробовать выразить на Прологе пространственные отношения между объектами, изображенными на обложке этой книги. Пример такого отношения: верхний шар расположен дальше, чем левый шар. Нетрудно также сформулировать и более общее положение в виде следующего правила: если X ближе к наблюдателю, чем Y, a Y - ближе, чем Z, то объект X находится ближе, чем Z. Пользуясь правилами и фактами, пролог-система может проводить рассуждения относительно имеющихся пространственных отношений и, в частности, проверить, насколько они согласуются с вышеуказанным общим правилом. Все эти возможности придают Прологу черты мощного языка для решения задач искусственного интеллекта, а также любых задач, требующих нечислового программирования.
Само название Пролог есть сокращение, означающее программирование в терминах логики. Идея использовать логику в качестве языка программирования возникла впервые в начале 70-х годов. Первыми исследователями, разрабатывавшими эту идею, были Роберт Ковальский из Эдинбурга (теоретические аспекты), Маартен ван Эмден из Эдинбурга (экспериментальная демонстрационная система) и Ален Колмероэ из Марселя (реализация). Сегодняшней своей популярности Пролог во многом обязан эффективной реализации этого языка, полученной в Эдинбурге Дэвидом Уорреном в середине 70-х годов.
Поскольку Пролог уходит своими корнями в математическую логику, его преподавание часто начинают с изложения логики. Однако такое введение в Пролог, насыщенное математическими понятиями, приносит мало пользы в том случае, когда Пролог изучается в качестве практического инструмента программирования.
Поэтому в данной книге мы не будем заниматься математическими аспектами этого языка, вместо этого мы сосредоточим свое внимание на навыках использования базовых механизмов Пролога, для решения целого ряда содержательных задач. В то время, как традиционные языки программирования являются процедурно-ориентированными, Пролог основан на описательной или декларативной точке зрения на программирование. Это свойство Пролога коренным образом меняет программистское мышление и делает обучение программированию на Прологе увлекательным занятием, требующим определенных интеллектуальных усилий.
В первой части книги содержится введение в Пролог, в ней показано, как составлять программы на Прологе. Во второй части демонстрируется, как мощные средства языка применяются в некоторых областях искусственного интеллекта, таких как, например, решение задач, эвристический поиск, экспертные системы, машинные игры и системы, управляемые образцами. В этой части излагаются фундаментальные методы в области искусственного интеллекта. Далее они прорабатываются достаточно глубоко для того, чтобы реализовать их на Прологе и получить готовые программы. Эти программы можно использовать в качестве "кирпичиков" для построения сложных прикладных систем. В книге рассматриваются также вопросы обработки таких сложных структур данных, как графы и деревья, хотя эти вопросы, строго говоря, и не имеют прямого отношения к искусственному интеллекту. В программах искусственного интеллекта методы обработки структур применяются довольно часто, и, реализуя их, читатель приобретет самые общие навыки программирования на Прологе. В книге особое внимание уделяется простоте и ясности составляемых программ. Повсеместно мы стремились избегать программистских "хитростей", повышающих эффективность за счет учета особенностей конкретной реализации Пролога.
Эта книга предназначена для тех, кто изучает Пролог и искусственный интеллект. Материал книги можно использовать в курсе лекций по искусственному интеллекту, ориентированном на прологовскую реализацию.
Предполагается, что читатель имеет общее представление о вычислительных машинах, но предварительные знания в области искусственного интеллекта необязательны. От читателя не требуется также какого-либо программистского опыта. Дело в том, что богатый программистский опыт вместе с приверженностью к традиционному процедурному программированию (например, на Паскале) может стать помехой при изучении Пролога, требующего свежего программистского мышления.
Среди различных диалектов Пролога наиболее широко распространен так называемый эдинбургский синтаксис (или синтаксис DEC-10), который мы я принимаем в данной книге. Для того, чтобы обеспечить совместимость с различными реализациями Пролога, мы используем в книге сравнительно небольшое подмножество встроенных средств, имеющихся во многих вариантах Пролога.
Как читать эту книгу? В первой части порядок чтения естественным образом совпадает с порядком изложения, принятым в книге. Впрочем, часть разд. 2.4, в которой дается более формальное описание процедурной семантики Пролога, можно опустить. В главе 4 приводятся примеры программ, которые можно читать только выборочно. Вторая часть книги допускает более гибкий порядок чтения, поскольку различные главы этой части предполагаются взаимно независимыми. Однако некоторые из тем было бы естественным прочесть раньше других - это относится к основным понятиям, связанным со структурами данных (гл. 9), и к базовым стратегиям поиска (гл. 11 и 13). В приведенной ниже диаграмме показана наиболее естественная последовательность чтения глав.

Существует целый ряд исторически сложившихся и противоречащих друг другу взглядов на Пролог. Пролог быстро завоевал популярность в Европе как практический инструмент программирования. В Японии Пролог оказался в центре разработки компьютеров пятого поколения. С другой стороны, в связи с определенными историческими факторами, в США Пролог получил признание несколько позднее. Один из этих факторов был связан с предварительным знакомством с Микропленнером, языком, близким к логическому программированию, но реализованным не эффективно.
Этот отрицательный опыт, относящийся к Микропленнеру, был неоправданно распространен и на Пролог, но позднее, после появления эффективной реализации, предложенной Дэвидом Уорреном, это предубеждение было убедительно снято. Определенная сдержанность по отношению к Прологу объяснялась также существованием "ортодоксальной школы" логического программирования, сторонники которой настаивали на использовании чистой логики, не запятнанной добавлением практически полезных внелогических средств. Практикам в области применения Пролога удалось изменить эту бескомпромиссную позицию и принять более прагматический подход, позволивший удачно сочетать декларативный принцип с традиционным - процедурным. И наконец, третьим фактором, приведшим к задержке признания Пролога, явилось то обстоятельство, что в США в течение долгого времени Лисп не имел серьезных конкурентов среди языков искусственного интеллекта. Понятно поэтому, что в исследовательских центрах с сильными лисповскими традициями возникало естественное противодействие Прологу. Но со временем соперничество между Прологом и Лиспом потеряло свою остроту, и в настоящее время многие считают, что оптимальный подход состоит в сочетании идей, лежащих в основе этих двух языков.
Представление графов
Графы используются во многих приложениях, например для представления отношений, ситуаций или структур задач. Граф определяется как множество вершин вместе с множеством ребер, причем каждое ребро задается парой вершин. Если ребра направлены, то их также называют дугами. Дуги задаются упорядоченными парами. Такие графы называются направленными. Ребрам можно приписывать стоимости, имена или метки произвольного вида, в зависимости от конкретного приложения. На рис. 6.18 показаны примеры графов.
В Прологе графы можно представлять различными способами. Один из них - каждое ребро записывать в виде отдельного предложения. Например, графы, показанные иа рис. 9.18, можно представить в виде следующего множества предложений:
связь( а, b).
связь( b, с).
. . .
дуга( s, t, 3).
дуга( t, v, 1).
дуга( u, t, 2).
. . .
Другой способ - весь граф представлять как один объект. В этом случае графу соответствует пара множеств - множество вершин и множество ребер. Каждое множество можно задавать при помощи списка, каждое ребро - парой вершин. Для объединения двух множеств в пару будем применять функтор граф, а для записи ребра - функтор р. Тогда (ненаправленный) граф рис. 9.18 примет вид:
G1 = граф( [a, b, c, d],
[р( а, b), р( b, d), р( b, с), p( c, d)] )
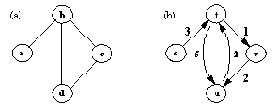
Рис. 9. 18. (а) Граф. (b) Направленный граф. Каждой дуге приписана ее стоимость.
Для представления направленного графа (рис. 9.18), применив функторы диграф и д (для дуг), получим
G2 = диграф( [s, t, u, v],
[д( s, t, 3), д( t, v, 1), д( t, u, 5), д( u, t, 2),
д( v, u, 2) ] )
Если каждая вершина графа соединена ребром еще по крайней мере с одной вершиной, то в представлении графа можно опустить множество вершин, поскольку оно неявным образом содержится в списке ребер.
Еще один способ представления графа - связать с каждой вершиной список смежных с ней вершин. В этом случае граф превращается в список пар, каждая из которых состоит из вершины- плюс ее список смежности. Наши графы (рис. 9.18), например, можно представить как
G1 = [ a->[b1, b->[a, c, d], c->[b, d], d->[b, c] ]
G2 = [s->[t/3], t->[u/5, v/l], u->[t/2], v->[u/2]]
Здесь символы '->' и '/' - инфиксные операторы.
Какой из способов представления окажется более удобным, зависит от конкретного приложения, а также от того, какие операции имеется в виду выполнять над графами. Вот типичные операции: найти путь между двумя заданными вершинами; найти подграф, обладающий некоторыми заданными свойствами. Примером последней операции может служить построение основного дерева графа. В последующих разделах, мы рассмотрим некоторые простые программы для поиска пути в графе и построения основного дерева.
Представление множеств двоичными деревьями
Списки часто применяют для представления множеств. Такое использование списков имеет тот недостаток, что проверка принадлежности элемента множеству оказывается довольно неэффективной. Обычно предикат принадлежит( X, L) для проверки принадлежности Х к L программируют так:
принадлежит X, [X | L] ).
принадлежит X, [ Y | L] ) :-
принадлежит( X, L).
Для того, чтобы найти Х в списке L, эта процедура последовательно просматривает список элемент за элементом, пока ей не встретится либо элемент X, либо конец списка. Для длинных списков такой способ крайне неэффективен.
Для облегчения более эффективной реализация отношения принадлежности применяют различные древовидные структуры. В настоящем разделе мы рассмотрим двоичные деревья.
Двоичное дерево либо пусто, либо состоит из следующих трех частей: корень левое поддерево правое поддерево
Корень может быть чем угодно, а поддеревья должны сами быть двоичными деревьями. На рис. 9.4 показано представление множества [а, b, с, d] двоичным деревом. Элементы множества хранятся в виде вершин дерева. Пустые поддеревья на рис. 9.4 не показаны. Например, вершина b имеет два поддерева, которые оба пусты.
Существует много способов представления двоичных деревьев на Прологе. Одна из простых возможностей - сделать корень главным функтором соответствующего терма, а поддеревья - его аргументами. Тогда дерево рис. 9.4 примет вид
а( b, с( d) )
Такое представление имеет среди прочих своих недостатков то слабое место, что для каждой вершины дерева нужен свой функтор. Это может привести к неприятностям, если вершины сами являются структурными объектами.

Рис. 9. 4. Двоичное дерево.
Существует более эффективный и более привычный способ представления двоичных деревьев: нам нужен специальный символ для обозначения пустого дерева и функтор для построения непустого дерева из трех компонент ( корня и двух поддеревьев).
достигается сразу же после применения первого предложения процедуры внутри. С другой стороны, цель
внутри( d, Т)
будет успешно достигнута только после нескольких рекурсивных обращений. Аналогично цель
внутри( е, Т)
потерпит неудачу только после того, как будет просмотрено все дерево в результате рекурсивного применения процедуры внутри
ко всем поддеревьям дерева Т.
В этом последнем случае мы видим такую же неэффективность, как если бы мы представили множество просто списком. Положение можно улучшить, если между элементами множества существует отношение порядка. Тогда можно упорядочить данные в дереве слева направо в соответствии с этим отношением.
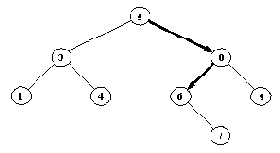
Рис. 9. 6. Двоичный справочник. Элемент 6 найден после прохода по отмеченному пути 5-->8-->6.
Будем говорить, что непустое дерево дер( Лев, X, Прав) упорядочено слева направо, если
(1) все вершины левого поддерева Лев меньше X;
(2) все вершины правого поддерева Прав больше X;
(3) оба поддерева упорядочены.
Будем называть такое двоичное дерево двоичным справочником. Пример показан на рис. 9.6.
Преимущество упорядочивания состоит в том, что для поиска некоторого объекта в двоичном справочнике всегда достаточно просмотреть не более одного поддерева. Экономия при поиске объекта Х достигается за счет того, что, сравнив Х с корнем, мы можем сразу же отбросить одно из поддеревьев. Например, пусть мы ищем элемент 6 в дереве, изображенной на рис. 9.6. Мы начинаем с корня 5, сравниваем 6 с 5, получаем 6 > 5. Поскольку все элементы данных в левом поддереве должны быть меньше, чем 5, единственная область, в которой еще осталась возможность найти элемент 6, - это правое поддерево. Продолжаем поиск в правом поддереве, переходя к вершине 8, и т.д.
Общий метод поиска в двоичном справочнике состоит в следующем:
line(); Для того, чтобы найти элемент Х в справочнике Д, необходимо: если Х - это корень справочника Д, то считать, что Х уже найден, иначе если Х меньше, чем корень, то искать Х в левом поддереве, иначе искать Х в правом поддереве; если справочник Д пуст, то поиск терпит неудачу. line(); Эти правила запрограммированы в виде процедуры, показанной на рис. 9.7. Отношение больше( X, Y), означает, что Х больше, чем Y. Если элементы, хранимые в дереве, - это числа, то под "больше, чем" имеется в виду просто Х > Y.
Существует способ использовать процедуру внутри также и для построения двоичного справочника. Например, справочник Д, содержащий элементы 5, 3, 8, будет построен при помощи следующей последовательности целей:
?- внутри( 5, Д), внутри( 3, Д), внутри( 8, Д).
Д = дер( дер( Д1, 3, Д2), 5, дер( Д3, 8, Д4) ).
Переменные Д1, Д2, Д3 и Д4 соответствуют четырем неопределенным поддеревьям. Какими бы они ни были, все равно дерево Д будет содержать заданные элементы 3, 5 и 8. Структура построенного дерева зависит от того порядка, в котором указываются цели (рис. 9.8).
line(); внутри( X, дер( _, X, _ ).
внутри( X, дер( Лев, Корень, Прав) ) :-
больше( Корень, X), % Корень больше, чем Х
внутри( X, Лев). % Поиск в левом поддереве
внутри( X, дер( Лев, Корень, Прав) ) :-
больше( X, Корень), % Х больше, чем корень
внутри( X, Прав). % Поиск в правом поддереве
line(); Рис. 9. 7. Поиск элемента Х в двоичном справочнике.
Рис. 9. 8. (а) Дерево Д, построенное как результат достижения целей: внутри( 5, Д), внутри( 3, Д), внутри( 8, Д). (b) Дерево, полученное при другом порядке целей: внутри( 5, Д), внутри( 3, Д), внутри( 8, Д).
Здесь уместно сделать несколько замечаний относительно эффективности поиска в справочниках. Вообще говоря, поиск элемента в справочнике эффективнее, чем поиск в списке. Но насколько? Пусть n - число элементов множества. Если множество представлено списком, то ожидаемое время поиска будет пропорционально его длине n. В среднем нам придется просмотреть примерно половину списка. Если множество представлено двоичным деревом, то время поиска будет пропорционально глубине дерева. Глубина дерева - это длина самого длинного пути между корнем и листом дерева. Однако следует помнить, что глубина дерева зависит от его формы.
Мы говорим, что дерево (приближенно) сбалансировано, если для каждой вершины дерева соответствующие два поддерева содержат примерно равное число элементов. Если дерево хорошо сбалансировано, то его глубина пропорциональна log n. В этом случае мы говорим, что дерево имеет логарифмическую сложность. Сбалансированный справочник лучше списка настолько же, насколько log n меньше n. К сожалению, это верно только для приближенно сбалансированного дерева. Если происходит разбалансировка дерева, то производительность падает. В случае полностью разбалансированных деревьев, дерево фактически превращается в список. Глубина дерева в этом случае равна n, а производительность поиска оказывается столь же низкой, как и в случае списка. В связи с этим мы всегда заинтересованы в том, чтобы справочники были сбалансированы.Методы достижения этой цели мы обсудим в гл. 10.
Представление списков
Список - это простая структура данных, широко используемая в нечисловом программировании. Список - это последовательность, составленная из произвольного числа элементов, например энн, теннис, том, лыжи. На Прологе это записывается так:
[ энн, теннис, том, лыжи ]
Однако таково лишь внешнее представление списков. Как мы уже видели в гл. 2, все структурные объекты Пролога - это деревья. Списки не являются исключением из этого правила.
Каким образом можно представить список в виде стандартного прологовского объекта? Мы должны рассмотреть два случая: пустой список и не пустой список. В первом случае список записывается как атом [ ]. Во втором случае список следует рассматривать как структуру состоящую из двух частей:
(1) первый элемент, называемый головой списка;
(2) остальная часть списка, называемая хвостом.
Например, для списка
[ энн, теннис, том, лыжи ]
энн - это голова, а хвостом является список
[ теннис, том, лыжи ]
В общем случае, головой может быть что угодно (любой прологовский объект, например, дерево или переменная); хвост же должен быть списком. Голова соединяется с хвостом при помощи специального функтора. Выбор этого функтора зависит от конкретной реализации Пролога; мы будем считать, что это точка:
.( Голова, Хвост)
Поскольку Хвост - это список, он либо пуст, либо имеет свои собственную голову и хвост. Таким образом, выбранного способа представления списков достаточно для представления списков любой длины. Наш список представляется следующим образом:
.( энн, .( теннис, .( том, .( лыжи, [ ] ) ) ) )
На рис. 3.1 изображена соответствующая древовидная структура. Заметим, что показанный выше пример содержит пустой список [ ]. Дело в том, что самый последний хвост является одноэлементным списком:
[ лыжи ]
Хвост этого списка пуст
[ лыжи ] = .( лыжи, [ ] )
Рассмотренный пример показывает, как общий принцип структуризации объектов данных можно применить к спискам любой длины. Из нашего примера также видно, что такой примитивный способ представления в случае большой глубины вложенности подэлементов в хвостовой части списка может привести к довольно запутанным выражениям. Вот почему в Прологе предусматривается более лаконичный способ изображения списков, при котором они записываются как последовательности элементов, заключенные в квадратные скобки. Программист может использовать оба способа, но представление с квадратными скобками, конечно, в большинстве случаев пользуется предпочтением. Мы, однако, всегда будем помнить, что это всего лишь косметическое улучшение и что во внутреннем представлении наши списки выглядят как деревья. При выводе же они автоматически преобразуются в более лаконичную форму представления. Так, например, возможен следующий диалог:
?- Список1 = [а, b, с],
Список2 = (a, .(b, .(c,[ ]) ) ).
Список1 = [а, b, с]
Список2 = [а, b, с]
?- Увлечения1 = .( теннис, .(музыка, [ ] ) ),
Увлечения2 = [лыжи, еда],
L = [энн, Увлечения1, том, Увлечения2].
Увлечения1 = [теннис, музыка]
Увлечения2 = [лыжи, еда]
L = [энн, [теннис, музыка], том, [лыжи, еда]]
Рис. 3. 1. Представление списка [энн, теннис, том, лыжи] в виде дерева.
Приведенный пример также напоминает вам о том, что элементами списка могут быть любые объекты, в частности тоже списки.
На практике часто бывает удобным трактовать хвост списка как самостоятельный объект. Например, пусть
L = [а, b, с]
Тогда можно написать:
Хвост = [b, с] и L = .(а, Хвост)
Для того, чтобы выразить это при помощи квадратных скобок, в Прологе предусмотрено еще одно расширение нотации для представления списка, а именно вертикальная черта, отделяющая голову от хвоста:
L = [а | Хвост]
На самом деле вертикальная черта имеет более общий смысл: мы можем перечислить любое количество элементов списка, затем поставить символ " | ", а после этого - список остальных элементов. Так, только что рассмотренный пример можно представить следующими различными способами:
[а, b, с] = [а | [b, с]] = [a, b | [c]] = [a, b, c | [ ]]
Подытожим: Список - это структура данных, которая либо пуста, либо состоит из двух частей: головы и хвоста. Хвост в свою очередь сам является списком. Список рассматривается в Прологе как специальный частный случай двоичного дерева. Для повышения наглядности программ в Прологе предусматриваются специальные средства для списковой нотации, позволяющие представлять списки в виде
[ Элемент1, Элемент2, ... ]
или
[ Голова | Хвост ]
или
[ Элемент1, Элемент2, ... | Остальные]
Представление задач в виде И / ИЛИ-графов
В главах 11 и 12, говоря о решении задач, мы сконцентрировали свое внимание на пространстве состояний как средстве представления этих задач. В соответствии с таким подходом решение задач сводилось к поиску пути в графе пространства состояний. Однако для некоторых категорий задач представление в форме И / ИЛИ-графа является более естественным. Такое представление основано на разбиении задач на подзадачи. Разбиение на подзадачи дает преимущества в том случае, когда подзадачи взаимно независимы, а, следовательно, и решать их можно независимо друг от друга.
Проиллюстрируем это на примере. Рассмотрим задачу отыскания на карте дорог маршрута между двумя заданными городами, как показано на рис. 13.1. Не будем пока учитывать длину путей. Разумеется, эту задачу можно сформулировать как поиск пути в про-

Рис. 13. 1. Поиск маршрута из а в z на карте дорог. Через реку
можно переправиться в городах f и g. И / ИЛИ-представление этой
задачи показано на рис. 13.2.
странстве состояний. Соответствующее пространство состояний выглядело бы в точности, как карта рис. 13.1: вершины соответствуют городам, дуги - непосредственным связям между городами. Тем не менее давайте построим другое представление, основанное на естественном разбиении этой задачи на подзадачи.
На карте рис. 13.1 мы видим также реку. Допустим, что переправиться через нее можно только по двум мостам: один расположен в городе f, другой - в городе g. Очевидно, что искомый маршрут обязательно должен проходить через один из мостов, а значит, он должен пройти либо через f, либо через g. Таким образом, мы имеем две главных альтернативы:
Для того, чтобы найти путь из а в z,
необходимо найти одно из двух:
(1) путь из а в z, проходящий через f, или
(2) путь из а в z, проходящий через g.

Рис. 13. 2. И / ИЛИ- представление задачи поиска маршрута рис. 13.1.
Вершины соответствуют задачам или подзадачам, полукруглые дуги
означают, что все (точнее, обе) подзадачи должны быть решены.
Теперь каждую из этих двух альтернативных задач можно, в свою очередь, разбить следующим образом:
(1) Для того, чтобы найти путь из a в z через
f, необходимо:
1.1 найти путь из а и f и
1.2 найти путь из f в z.
(2) Для того, чтобы найти путь из a в z через
g, необходимо:
2.1 найти путь из а в g и
2.2 найти путь из g в z.
Рис. 13. 3. (а) Решить Р - это значит решить Р1 или Р2 или ...
(б) Решить Q - это значит решить все: Q1 и Q2 и ... .
Итак, мы имеем две главных альтернативы для решения исходной задачи: (1) путь через f или (2) путь через g. Далее, каждую из этих альтернатив можно разбить на подзадачи (1.1 и 1.2 или 2.1 и 2.2 соответственно).
Здесь важно то обстоятельство, что каждую из подзадач в обоих альтернативах можно решать независимо от другой. Полученное разбиение исходной задачи можно изобразить в форме И / ИЛИ-графа (рис. 13.2). Обратите внимание на полукруглые дуги, которые указывают на отношение И между соответствующими подзадачами. Граф, показанный на рис. 13.2 - это всего лишь верхняя часть всего И / ИЛИ-дерева. Дальнейшее разбиение подзадач можно было бы строить на основе введения дополнительных промежуточных городов.
Какие вершины И / ИЛИ-графа являются целевыми? Целевые вершины - это тривиальные, или "примитивные" задачи. В нашем примере такой подзадачей можно было бы считать подзадачу "найти путь из а в с", поскольку между городами а и с на карте имеется непосредственная связь.
Рассматривая наш пример, мы ввели ряд важных понятий. И / ИЛИ-граф - это направленный граф, вершины которого соответствуют задачам, а дуги - отношениям между задачами. Между дугами также существуют свои отношения. Это отношения И и ИЛИ, в зависимости от того, должны ли мы решить только одну из задач-преемников или же несколко из них (см. рис. 13.3). В принципе из вершины могут выходить дуги, находящиеся в отношении И вместе с дугами, находящимися в отношении ИЛИ. Тем не менее, мы будем предполагать, что каждая вершина имеет либо только И-преемников, либо только ИЛИ-преемников; дело в том, что в такую форму можно преобразовать любой И / ИЛИ граф, вводя в него при необходимости вспомогательные ИЛИ-вершины. Вершину, из которой выходят только И-дуги, называют И-вершиной; вершину, из которой выходят только ИЛИ-дуги, - ИЛИ-вершиной.
Когда задача представлялась в форме пространства состояний, ее решением был путь в этом пространстве. Что является решением в случае И / ИЛИ-представления? Решение должно, конечно, включать в себя все подзадачи И-вершины. Следовательно, это уже не путь, а дерево. Такое решающее дерево Т определяется следующим образом: исходная задача Р - это корень дерева Т; если Р является ИЛИ-вершиной, то в Т содержится только один из ее преемников (из И / ИЛИ-графа) вместе со своим собственным решающим деревом; если Р - это И-вершина, то все ее преемники (из И / ИЛИ-графа) вместе со своими решающими деревьями содержатся в Т.
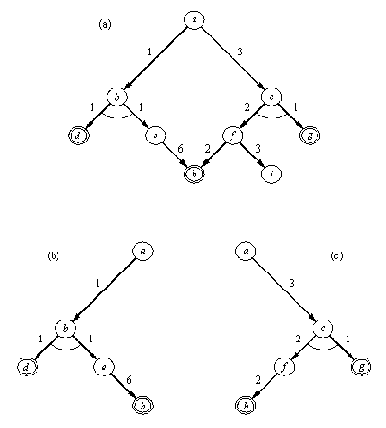
Рис. 13. 4. (а) Пример И / ИЛИ-графа: d, g и h - целевые вершины;
a - исходная задача. (b) и (с) Два решающих дерева, стоимости
которых равны 9 и 8 соответственно. Здесь стоимость решающего
дерева определена как сумма стоимостей всех входящих в него дуг.
Иллюстрацией к этому определению может служить рис. 13.4. Используя стоимости, мы можем формулировать критерии оптимальности решения. Например, можно определить стоимость решающего графа как сумму стоимостей всех входящих в него дуг. Тогда, поскольку обычно мы заинтересованы в минимизации стоимости, мы отдадим предпочтение решающему графу, изображенному на рис. 13.4(с).
Однако мы не обязательно должны измерять степень оптимальности решения, базируясь на стоимостях дуг. Иногда более естественным окажется приписывать стоимость не дугам, а вершинам, или же и тем, и другим одновременно.
Подведем итоги: И / ИЛИ-представление основано на философии сведения задач к подзадачам. Вершины И / ИЛИ-графа соответствуют задачам; связи между вершинами - отношениям между задачами. Вершина, из которой выходят ИЛИ-связи, называется ИЛИ-вершиной. Для того, чтобы решить соответствующую задачу, нужно решить одну из ее задач-преемников. Вершина, из которой выходят И-связи, называ ется И-вершиной. Для того, чтобы решить соответствующую задачу, нужно решить все ее задачи-преемники. При заданном И / ИЛИ-графе конкретная задача специфицируется заданием
стартовой вершины и
целевого условия для распознавания
целевых вершин.
Целевые вершины (или "терминальные вершины") соответствуют тривиальным (или "примитивным") задачам. Решение представляется в виде решающего графа - подграфа всего И / ИЛИ-графа. Представление задач в форме пространства состояний можно рассматривать как специальный частный случай И / ИЛИ-представления, когда все вершины И / ИЛИ-графа являются ИЛИ-вершинами. И / ИЛИ-представление имеет преимущество в том случае, когда вершинами, находящимися в отношении И, представлены подзадачи, которые можно решать независимо друг от друга.Критерий независимости можно несколько ослабить, а именно потребовать, чтобы существовал такой порядок решения И-задач, при котором решение более "ранних" подзадач не разрушалось бы при решении более "поздних" под задач. Дугам или вершинам, или и тем, и другим можно приписать стоимости с целью получить возможность сформулировать критерий оптимальности решения. Назад | Содержание | Вперёд
