часто используемая структура. Он либо
Список - часто используемая структура. Он либо пуст, либо состоит из головы и хвоста, который в свою очередь также является списком. Для списков в Прологе имеется специальная нотация. В данной главе рассмотрены следующие операции над списками: принадлежность к списку, конкатенация, добавление элемента, удаление элемента, удаление подсписка. Операторная запись позволяет программисту приспособить синтаксис программ к своим конкретным нуждам. С помощью операторов можно значительно повысить наглядность программ. Новые операторы определяются с помощью директивы ор, в которой указываются его имя, тип и приоритет. Как правило, с оператором не связывается никакой операции; оператор это просто синтаксическое удобство, обеспечивающее альтернативный способ записи термов. Арифметические операции выполняются с помощью встроенных процедур. Вычисление арифметических выражений запускается процедурой is, а также предикатами сравнения <, =< и т.д. Понятия, введенные в данной главе:
список, голова списка, хвост списка
списковая нотация
операторы, операторная нотация
инфиксные, префиксные и постфиксные
операторы
приоритет операторов
арифметические встроенные процедуры Назад | Содержание | Вперёд
в данном разделе, иллюстрируют некоторые
Примеры, рассмотренные в данном разделе, иллюстрируют некоторые достоинства и характерные черты программирования на Прологе: Базу данных можно естественным образом представить в виде множества прологовских фактов. Такие механизмы Пролога, как вопросы и сопоставление, можно гибко использовать для получения информации из базы данных. Кроме этого можно использовать вспомогательные процедуры-утилиты, еще больше облегчающие взаимодействие с конкретной базой данных. Абстракцию данных можно рассматривать как метод программирования, который облегчает работу со сложными структурами данных и вносит большую ясность и наглядность в программы. В Прологе легко соблюдать основные принципы абстракции данных. Часто легко можно осуществить перевод абстрактных математических конструкций, таких как автоматы, на язык определений Пролога, готовых к выполнению. Как это было в случае восьми ферзей, многие задачи допускают различные подходы, связанные с разными представлениями этих задач. Часто внесение избыточности в представление экономит вычисления. Происходит как бы проигрыш в рабочем пространстве, но выигрыш во времени. Часто основным шагом на пути к решению оказывается обобщение задачи. Парадоксально, но рассмотрение более общей задачи позволяет облегчить формулировку решения. Назад | Содержание | Вперёд
Отсечение подавляет перебор. Его применяют
Отсечение подавляет перебор. Его применяют как для повышения эффективности программ, так и для повышения выразительности языка. Эффективность повышается путем прямого указания (при помощи отсечения) пролог - системе не проверять альтернативы, про которые нам заранее известно, что они должны потерпеть неудачу. Отсечение дает возможность сформулировать взаимно исключающие утверждения при помощи правил вида:
если Условие то Утверждение1 иначе Утверждение2
Отсечение дает возможность ввести отрицание как неуспех: not( Цель) определяется через неуспех цели Цель. Иногда бывают полезными две особые цели true и fail. true - всегда успешна и fail - всегда терпит неудачу. Существуют ограничения в применении отсечения: его появление может нарушить, соответствие между декларативным и процедурным смыслами программы. Поэтому хороший стиль программирования предполагает осторожное применение отсечений и отказ от их применения без достаточных оснований. Оператор not, определенный через неуспех, не полностью соответствует отрицанию в математической логике. Поэтому not тоже нужно применять с осторожностью.
к программе) осуществляется посредством встроенных
Ввод и вывод (отличный от связанного с вопросами к программе) осуществляется посредством встроенных процедур. В данной главе описан простой и практичный набор таких процедур, имеющихся во многих реализациях Пролога. Файлы являются последовательными. Существуют текущие входной и выходной потоки. Пользовательский терминал рассматривается как файл с именем user. Переключение между потоками осуществляется с помощью процедур:
sее( Файл) Файл становится текущим входным потоком
tell( Файл) Файл становится текущим выходным потоком
seen закрывается текущий входной поток
told закрывается текущий выходной поток
Файлы читаются и записываются двумя способами:
как последовательности символов
как последовательности термов
Встроенные процедуры для чтения и записи символов и термов таковы:
rеad( Терм)
вводит следующий терм
write( Терм)
выводит Терм
put( КодСимвола)
выводит символ с заданным ASCII - кодом
В любой реализации Пролога обычно
В любой реализации Пролога обычно предусматривается набор встроенных процедур для выполнения различных полезных операций, несуществующих в чистом Прологе. В данной главе мы рассмотрели подобное множество предикатов, имеющееся во многих реализациях. Тип терма можно установить при помощи следующих предикатов:
var( X) Х - (неконкретизированная) переменная
nonvar( X) Х - не переменная
atom( X) Х - атом
integer( X) Х - целое
atomic( X) Х - или атом, или целое
Термы можно синтезировать или разбирать на части:
Терм =.. [Функтор [ СписокАргументов]
functor( Терм, Функтор, Арность)
arg( N, Терм, Аргумент)
name( атом, КодыСимволов)
Программу на Прологе можно рассматривать как реляционную базу данных, которую можно изменять при помощи следующих процедур:
аssert( Предл) добавляет предложение Предл к программе
аssегtа( Предл) добавляет в начало
asserfz( Предл) добавляет в конец
Для оценки качества программы существует
Для оценки качества программы существует несколько критериев:
правильность
эффективность
простота, читабельность
удобство модификации
документированность
Принцип пошаговой детализации - хороший способ организации процесса разработки программ. Пошаговая детализация применима к отношениям, алгоритмам и структурам данных. Следующие методы часто помогают находить идеи для совершенствования программ на Прологе:
Применение рекурсии: выявить граничные и общие случаи рекурсивного определения.
Обобщение: рассмотреть такую более общую задачу, которую проще решить, чем исходную.
Использование рисунков: графическое представление помогает в выявлении важных отношений.
Полезно следовать некоторым стилистическим соглашениям для уменьшения опасности внесения ошибок в программы и создания программ, легких для чтения, отладки и модификации. В пролог-системах обычно имеются средства отладки. Наиболее полезными являются средства трассировки программ. Существует много способов повышения эффективности программы. Наиболее простые способы включают в себя:
изменение порядка целей и предложений
управляемый перебор при помощи введения отсечений
запоминание (с помощью assert) решений, которые иначе пришлось бы перевычислять Более тонкие и радикальные методы связаны с улучшением алгоритмов (особенно, в части повышения эффективности перебора) и с совершенствованием структур данных.
Назад | Содержание | Вперёд
В данной главе мы изучали
В данной главе мы изучали реализацию на Прологе некоторых часто используемых структур данных и соответствующих операций над ними. В том числе Списки:
варианты представления списков
сортировка списков:
сортировка методом "пузырька"
сортировка со вставками
быстрая сортировка
эффективность этих процедур
Представление множеств двоичными деревьями и двоичными справочниками:
поиск элемента в дереве
добавление элемента
удаление элемента
добавление в качестве листа или корня
сбалансированность деревьев и его связь с
эффективностью этих операций
отображение деревьев
Графы:
представление графов
поиск пути в графе
построение остовного дерева
?- Родитель( X, _ )
Лексический диапазон имени - одно предложение. Это значит, что если, например, имя Х15 встречается в двух предложениях, то оно обозначает две разные переменные. Однако внутри одного предложения каждое его появлений обозначает одну и ту же переменную. Для констант ситуация другая: один и тот же атом обозначает один и тот же объект в любом предложении, иначе говоря, - во всей программе.
Сцепление ( конкатенация)
Для сцепления списков мы определим отношение
конк( L1, L2, L3)
Здесь L1 и L2 - два списка, a L3 - список, получаемый при их сцеплении. Например,
конк( [а, b], [c, d], [a, b, c, d] )
истинно, а
конк( [а, b], [c, d], [a, b, a, c, d] )
ложно. Определение отношения конк, как и раньше, содержит два случая в зависимости от вида первого аргумента L1:
(1) Если первый аргумент пуст, тогда второй и третий аргументы представляют собой один и тот же список (назовем его L), что выражается в виде следующего прологовского факта:
конк( [ ], L, L ).
(2) Если первый аргумент отношения конк не пуст, то он имеет голову и хвост в выглядит так:
[X | L1]
На рис. 3.2 показано, как производится сцепление списка [X | L1] с произвольным списком L2. Результат сцепления - список [X | L3], где L3 получен после сцепления списков L1 и L2. На прологе это можно записать следующим образом:
конк( [X | L1, L2, [X | L3]):-
конк( L1, L2, L3).

Рис. 3. 2. Конкатенация списков.
Составленную программу можно теперь использовать для сцепления заданных списков, например:
?- конк( [a, b, с], [1, 2, 3], L ).
L = [a, b, c, 1, 2, 3]
?- конк( [а, [b, с], d], [а, [ ], b], L ).
L = [a, [b, c], d, а, [ ], b]
Хотя программа для конк выглядит довольно просто, она обладает большой гибкостью и ее можно использовать многими другими способами. Например, ее можно применять как бы в обратном направлении для разбиения заданного списка на две части:
?- конк( L1, L2, [а, b, с] ).
L1 = [ ]
L2 = [а, b, c];
L1 = [а]
L2 = [b, с];
L1 = [а, b]
L2 = [c];
L1 = [а, b, с]
L2 = [ ];
no (нет)
Список [а, b, с] разбивается на два списка четырьмя способами, и все они были обнаружены нашей программой при помощи механизма автоматического перебора.
Нашу программу можно также применить для поиска в списке комбинации элементов, отвечающей некоторому условию, задаваемому в виде шаблона или образца. Например, можно найти все месяцы, предшествующие данному, и все месяцы, следующие за ним, сформулировав такую цель:
?- конк( До, [май | После ],
[янв, фев, март, апр, май, июнь,
июль, авг, сент, окт, ноябрь, дек]).
До = [янв, фев, март, апр]
После = [июнь, июль, авг, сент, окт, ноябрь, дек].
Далее мы сможем найти месяц, непосредственно предшествующий маю, и месяц, непосредственно следующий за ним, задав вопрос:
?- конк( _, [Месяц1, май, Месяц2 | _ ],
[янв, февр, март, апр, май, июнь,
июль, авг, сент, окт, ноябрь, дек]).
Месяц1 = апр
Месяц2 = июнь
Более того, мы сможем, например, удалить из некоторого списка L1 все, что следует за тремя последовательными вхождениями элемента z в L1 вместе с этими тремя z. Например, это можно сделать так:
?- L1 = [a, b, z, z, c, z, z, z, d, e],
конк( L2, [z, z, z | _ ], L1).
L1 = [a, b, z, z, c, z, z, z, d, e]
L2 = [a, b, z, z, c]
Мы уже запрограммировали отношение принадлежности. Однако, используя конк, можно было бы определить это отношение следующим эквивалентным способом:
принадлежит1( X, L) :-
конк( L1, [X | L2], L).
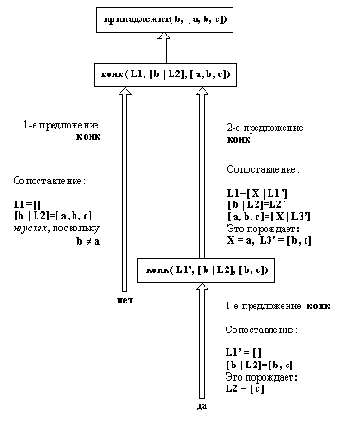
Рис. 3. 3. Процедура принадлежит1 находит элемент в заданном
списке, производя по нему последовательный поиск.
В этом предложении сказано: "X принадлежит L, если список L можно разбить на два списка таким образом, чтобы элемент Х являлся головой второго из них. Разумеется, принадлежит1 определяет то же самое отношение, что и принадлежит. Мы использовали другое имя только для того, чтобы различать таким образом две разные реализации этого отношения, Заметим, что, используя анонимную переменную, можно записать вышеприведенное предложение так:
принадлежит1( X, L) :-
конк( _, [X | _ ], L).
Интересно сравнить между собой эти две реализации отношения принадлежности. Принадлежит имеет довольно очевидный процедурный смысл:
Для проверки, является ли Х элементом списка L, нужно
(1) сначала проверить, не совпадает ли голова списка L с X, а затем
(2) проверить, не принадлежит ли Х хвосту списка L.
С другой стороны, принадлежит1, наоборот, имеет очевидный декларативный смысл, но его процедурный смысл не столь очевиден.
Интересным упражнением было бы следующее: выяснить, как в действительности принадлежит1 что-либо вычисляет. Некоторое представление об этом мы получим, рассмотрев запись всех шагов вычисления ответа на вопрос:
?- принадлежит1( b, [а, b, с] ).
На рис. 3.3 приведена эта запись. Из нее можно заключить, что принадлежит1 ведет себя точно так же, как и принадлежит. Он просматривает список элемент за элементом до тех пор, пока не найдет нужный или пока не кончится список.
СИНТАКСИС И СЕМАНТИКА ПРОЛОГ ПРОГРАММ
В данной главе дается систематическое изложение синтаксиса и семантики основных понятий Пролога, а также вводятся структурные объекты данных. Рассматриваются следующие темы: простые объекты данных (атомы, числа, переменные) структурные объекты сопоставление как основная операция над объектами декларативная (или непроцедурная) семантика программ взаимосвязь между декларативным и процедурным смыслами программ изменение процедурного смысла путем изменения порядка следования предложений и целей
Большая часть этих тем уже была затронута в гл. 1. Теперь их изложение будет более формальным и детализированным.
double_line();Сочетание декларативного и процедурного подходов
В предыдущем разделе было показано, что порядок целей и предложений имеет существенное значение. Более того, существуют программы, которые верны в декларативном смысле, но на практике не работают. Такое противоречие между декларативным и процедурным смыслами может вызвать недовольство. Кто-нибудь спросит: "А почему вообще не забыть о декларативном смысле?" Такое пожелание становится особенно сильным, когда рассматриваются предложения типа:
предок( X, Z) :- предок( X, Z).
Это предложение верно в декларативном смысле, но совершенно бесполезно в качестве рабочей программы.
Причина, по которой не следует забывать о декларативном смысле, кроется в том, что прогресс, достигнутый в технологии программирования, получен на пути продвижения от учета всех процедурных деталей к концентрации внимания на декларативных аспектах, которые обычно легче формулировать и понимать. Сама система, а не программист, должна нести бремя заботы о процедурных деталях. В этом Пролог оказывает некоторую помощь, хотя, как мы видели в данном разделе, помощь лишь частичную: иногда он правильно прорабатывает эти процедурные детали, иногда - нет. Многие придерживаются мнения, что лучше иметь хоть какую-то декларативную семантику, чем никакой (отсутствие декларативной семантики характерно для многих других языков программирования). Практическим следствием такого взгляда является тот факт, что часто довольно легко получить работающую программу, имея программу декларативно корректную. Поэтому практичным следует признать такой подход: сосредоточиться на декларативных аспектах задачи, затем пропустить на машине полученную программу и, если она окажется процедурно неправильной, попытаться изменить порядок следования предложений и целей.
Назад | Содержание | Вперёд
Сопоставление
В предыдущем разделе мы видели, как используются термы для представления сложных объектов данных. Наиболее важной операцией над термами является сопоставление. Сопоставление само по себе может производить содержательные вычисления.
Пусть даны два терма. Будем говорить, что они сопоставимы, если:
(1) они идентичны или
(2) переменным в обоих термах можно приписать в качестве значений объекты (т.е. конкретизировать их) таким образом, чтобы после подстановки этих объектов в термы вместо переменных, последние стали идентичными.
Например, термы дата( Д, М, 1983) и дата( Д1, май, Y1) сопоставимы. Одной из конкретизации, которая делает эти термы идентичными, является следующая: Д заменяется на Д1 М заменяется на май Y1 заменяется на 1983
Более компактно такая подстановка записывается в привычной форме, т. е. в той, в которой пролог-система выводит результаты:
Д = Д1
М = май
Y1 = 1983
С другой стороны, дата( Д, М, 1983) и дата( Д1, Ml, 1944) не сопоставимы, как и термы дата( X, Y, Z) и точка( X, Y, Z).
Сопоставление - это процесс, на вход которого подаются два терма, а он проверяет, соответствуют ли эти термы друг другу. Если термы не сопоставимы, будем говорить, что этот процесс терпит неуспех. Если же они сопоставимы, тогда процесс находит конкретизацию переменных, делающую эти термы тождественными, и завершается успешно.
Рассмотрим еще раз сопоставление двух дат. Запрос на проведение такой операции можно передать системе, использовав оператор '=':
?- дата( Д, М, 1983) = дата( Д1, май, Y1).
Мы уже упоминали конкретизацию Д = Д1, М = май, Y1 = 1983, на которой достигается сопоставление. Существуют, однако, и другие конкретизации, делающие оба терма идентичными.
Вот две из них:
Д = 1
Д1 = 1
М = май
Y1 = 1983
Д = третий
Д1 = третий
М = май
Y1 = 1983
Говорят, что эти конкретизации являются менее общими по сравнению с первой, поскольку они ограничивают значения переменных Д и Д1
в большей степени, чем это необходимо. Для того, чтобы сделать оба терма нашего примера идентичными, важно лишь, чтобы Д и Д1
имели одно и то же значение, однако само это значение может быть произвольным. Сопоставление в Прологе всегда дает наиболее общую конкретизацию. Таковой является конкретизация, которая ограничивает переменные в наименьшей степени, оставляя им, тем самым, наибольшую свободу для дальнейших конкретизаций, если потребуются новые сопоставления. В качестве примера рассмотрим следующий вопрос:
?- дата( Д, М, 1983) = дата( Д1, май, Y1),
дата( Д, М, 1983) = дата( 15, М, Y).
Для достижения первой цели система припишет переменным такие значения:
Д = Д1
М = май
Y1 = 1983
После достижения второй цели, значения переменных станут более конкретными, а именно:
Д = 15
Д1 = 15
М = май
Y1 = 1983
Y = 1983
Этот пример иллюстрирует также и тот факт, что переменным по мере вычисления последовательности целей приписываются обычно все более и более конкретные значения.
Общие правила выяснения, сопоставимы ли два терма S и Т, таковы:
line();
(1) Если S и Т - константы, то S и Т сопоставимы, только если они являются одним и тем же объектом.
(2) Если S - переменная, а Т - произвольный объект, то они сопоставимы, и S приписывается значение Т. Наоборот, если Т -переменная, а S -произвольный объект, то Т приписывается значение S.
(3) Если S и Т - структуры, то они сопоставимы, только если
(а) S и Т имеют одинаковый главный функтор
и
(б) все их соответствующие компоненты сопоставимы.
Результирующая конкретизация определяется сопоставлением компонент.
line();
Последнее из этих правил можно наглядно представить себе, рассмотрев древовидное изображение термов, такое, например, как на рис. 2.7. Процесс сопоставления начинается от корня (главных функторов). Поскольку оба функтора сопоставимы, процесс продолжается и сопоставляет соответствующие пары аргументов. Таким образом, можно представить себе, что весь процесс сопоставления состоит из следующей последовательности (более простых) операций сопоставления:
треугольник = треугольник,
точка( 1, 1) = X,
А = точка( 4, Y),
точка( 2, 3) = точка( 2, Z).
Весь процесс сопоставления успешен, поскольку все сопоставления в этой последовательности успешны. Результирующая конкретизация такова:
Х = точка( 1, 1)
А = точка( 4, Y)
Z = 3
В приведенном ниже примере показано, как сопоставление само по себе можно использовать для содержательных вычислений. Давайте вернемся к простым геометрическим объектам с рис. 2.4 и напишем фрагмент программы для распознавания горизонтальных и вертикальных отрезков. "Вертикальность" - это свойство отрезка, поэтому его можно формализовать в Прологе в виде унарного отношения. Рис. 2.8 помогает сформулировать это отношение. Отрезок
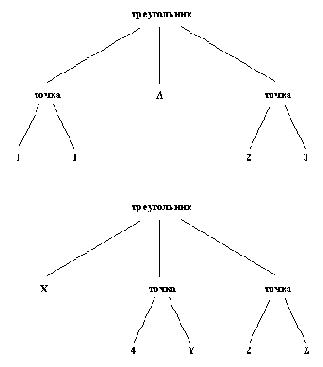
Рис. 2. 7. Сопоставление треугольник(( точка( 1, 1), А, точка( 2, 3)) = треугольник( Х, точка( 4, Y),
точка( 2, Z))
является вертикальным, если x-координаты его точек-концов совпадают; никаких других ограничений на отрезок не накладывается. Свойство "горизонтальности" формулируется аналогично, нужно только в этой формулировке х и y поменять местами. Следующая программа, содержащая два факта, реализует эти формулировки:
верт( отр( точка( Х, Y), точка( Х, Y1) ) ).
гор( отр( точка( Х, Y), точка( Х1, Y) ) ).
С этой программой возможен такой диалог:
?- верт( отр( точка( 1, 1), точка( 1, 2) ) ).
да
?- верт( отр( точка( 1, 1), точка( 2, Y) ) ).
нет
?- гор( отр( точка( 1, 1), точка( 2, Y) ) ).
Y = 1
На первый вопрос система ответила "да", потому. что цель, поставленная в вопросе, сопоставима с одним из фактов программы. Для второго вопроса сопоставимых фактов не нашлось. Во время ответа на третий вопрос при сопоставлении с фактом о горизонтальных отрезках Y получил значение 1.
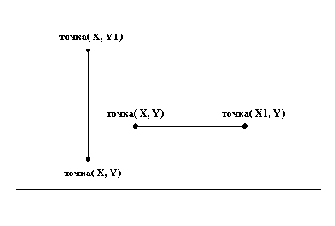
Рис. 2. 8. Пример вертикальных и горизонтальных отрезков прямых.
Сформулируем более общий вопрос к программе: "Существуют ли какие-либо вертикальные отрезки, начало которых лежит в точке (2,3)?"
?- верт( отр( точка( 2, 3), Р) ).
Р = точка( 2, Y)
Такой ответ означает: "Да, это любой отрезок, с концом в точке (2,Y), т. е. в произвольной точке вертикальной прямой х = 2". Следует заметить, что ответ пролог-системы возможно будет выглядеть не так красиво, как только что описано, а (в зависимости от реализации) приблизительно следующим образом:
Р = точка( 2, _136)
Впрочем, разница здесь чисто внешняя. В данном случае _136 - это неинициализированная переменная. Имя _136 - законное имя прологовской переменной, которое система построила сама во время вычислений. Ей приходится генерировать новые имена, для того чтобы переименовывать введенные пользователем переменные в программе. Это необходимо по двум причинам: первая - одинаковые имена обозначают в разных предложениях разные переменные; и вторая - при последовательном применении одного и того же предложения используется каждый раз его "копия" с новым набором переменных.
Другим содержательным вопросом к нашей программe является следующий: "Существует ли отрезок, который одновременно и горизонтален в вертикален?"
?- верт( S), гор( S).
S = отр( точка( Х, Y), точка( Х, Y) )
Такой ответ пролог-системы следует, понимать так: "да, любой отрезок, выродившийся в точку, обладает как свойством вертикальности, так и свойством горизонтальности одновременно". Этот ответ снова получен лишь из сопоставления. Как и раньше, в ответе вместо Х и Y могут появиться некоторые имена, сгенерированные системой.
Сортировка списков
Сортировка применяется очень часто. Список можно отсортировать (упорядочить), если между его элементами определено отношение порядка. Для удобства изложения мы будем использовать отношение порядка
больше( X, Y)
означающее, что Х больше, чем Y, независимо от того, что мы в действительности понимаем под "больше, чем". Если элементами списка являются числа, то отношение больше будет, вероятно, определено как
больше( X, Y) := Х > Y.
Если же элементы списка - атомы, то отношение больше может соответствовать алфавитному порядку между ними.
Пусть
сорт( Спис, УпорСпис)
обозначает отношение, в котором Спис - некоторый список, а УпорСпис - это список, составленный из тех же элементов, но упорядоченный по возрастанию в соответствия с отношением больше. Мы построим три определения этого отношения на Прологе, основанные на трех различных идеях о механизме сортировки. Вот первая идея:
line();Для того, чтобы упорядочить список Спис, необходимо: Найти в Спис два смежных элемента Х и Y, таких, что больше( X, Y), и поменять Х и Y местами, получив тем самым новый список Спис1; затем отсортировать Спис1. Если в Спис нет ни одной пары смежных элементов Х и Y, таких, что больше( X, Y), то считать, что Спис уже отсортирован. line();
Мы переставили местами 2 элемента X и Y, расположенные в списке "не в том порядке", с целью приблизить список к своему упорядоченному состоянию. Имеется в виду, что после достаточно большого числа перестановок все элементы списка будут расположены в правильном порядке. Описанный принцип сортировки принято называть методом пузырька, поэтому соответствующая прологовская процедура будет называться пузырек.
пузырек( Спис, УпорСпис) :-
перест( Спис, Спис1), !,
% Полезная перестановка ?
пузырек( Спис1, УпорСпис).
пузырек( УпорСпис, УпорСпис).
% Если нет, то список уже упорядочен
перест( [Х, Y | Остаток], [Y, Х ) Остаток] ):-
% Перестановка первых двух элементов
больше( X, Y).
перест( [Z | Остаток], [Z | Остаток1] ):-
перест( Остаток, Остаток1). % Перестановка в хвосте
Еще один простой алгоритм сортировки называется сортировкой со вставками.
Он основан на следующей идее:
line();
Для того, чтобы упорядочить непустой список L = [X | Хв], необходимо:
(1) Упорядочить хвост Хв
списка L.
(2) Вставить голову Х списка L в упорядоченный хвост, поместив ее в такое место, чтобы получившийся список остался упорядоченным. Список отсортирован.
line();
Этот алгоритм транслируется в следующую процедуру вставсорт на Прологе:
вставсорт([ ], [ ]).
вставсорт( [X | Хв], УпорСпис) :-
вставсорт( Хв, УпорХв),
% Сортировка хвоста
встав( X, УпорХв, УпорСпис).
% Вставить Х на нужное место
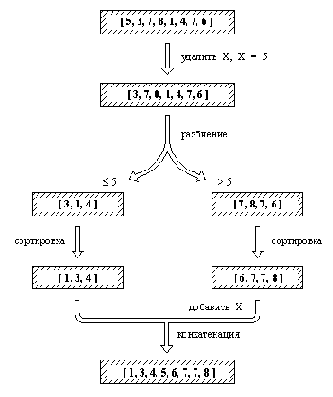
Рис. 9. 1. Сортировка списка процедурой быстрсорт.
встав( X, [Y | УпорСпис], [Y | УпорСпис1]):-
больше( X, Y), !,
встав( X, УпорСпис, УпорСпис1).
встав( X, УпорСпис, [X | УпорСпис] ).
Процедуры сортировки пузырек и вставсорт просты, но не эффективны. Из этих двух процедур процедура со вставками более эффективна, однако среднее время, необходимое для сортировки списка длиной n процедурой вставсорт, возрастает с ростом n пропорционально n2. Поэтому для длинных списков значительно лучше работает алгоритм быстрой сортировки, основанный на следующей идее (рис. 9.1):
line(); Для того, чтобы упорядочить непустой список L, необходимо:
(1) Удалить из списка L какой-нибудь элемент Х и разбить оставшуюся часть на два списка, называемые Меньш и Больш, следующим образом: все элементы большие, чем X, принадлежат списку Больш, остальные - списку Меньш.
(2) Отсортировать список Меньш, результат - список УпорМеньш.
(3) Отсортировать список Больш, результат - список УпорБольш.
(4) Получить результирующий упорядоченный список как конкатенацию списков УпорМеньш и [ Х | УпорБольш].
line(); Заметим, что если исходный список пуст, то результатом сортировки также будет пустой список. Реализация быстрой сортировки на Прологе показана на рис. 9.2. Здесь в качестве элемента X, удаляемого из списка, всегда выбирается просто голова этого списка. Разбиение на два списка запрограммировано как отношение с четырьмя аргументами:
разбиение( X, L, Больш, Меньш).
Временная сложность нашего алгоритма зависит от того, насколько нам повезет при разбиении сортируемого списка. Если списки всегда разбиваются на два списка примерно равной длины, то процедура сортировки имеет временную сложность порядка nlogn, где n - длина исходного списка. Если же, наоборот, разбиение всегда приводит к тому, что один из списков оказывается значительно больше другого, то сложность будет порядка n2. Анализ показывает, что, к счастью, средняя производительность быстрой сортировки ближе к лучшему случаю, чем к худшему.
Программу, показанную на рис. 9.2, можно усовершенствовать, если реализовать операцию конкатенации более эффективно. Напомним, что конкатенация
line(); быстрсорт( [ ], [ ] ).
быстрсорт( [X | Хвост], УпорСпис) :-
разбиение( X, Хвост, Меньш, Больш),
быстрсорт( Меньш, УпорМеньш),
быстрсорт( Больш, УпорБольш),
конк( УпорМеньш, [X | УпорБольш], УпорСпис).
разбиение( X, [ ], [ ], [ ] ).
разбиение( X, [Y | Хвост], [Y | Меньш], Больш ) :-
больше( X, Y), !,
разбиение( X, Хвост, Меньш, Больш).
разбиение( X, [Y | Хвост], Меньш, [Y | Больш] ) :-
разбиение( X, Хвост, Меньш, Больш).
конк( [ ], L, L).
конк( [X | L1], L2, [X | L3] ) :-
конк( L1, L2, L3 ).
line(); Рис. 9. 2. Быстрая сортировка.
становится тривиальной операцией после применения разностного представления списков, введенного в гл. 8. Для того, чтобы использовать эту идею в нашей процедуре сортировки, нужно представить встречающиеся в ней списки в форме пар вида A-Z следующим образом:
УпорМеньш имеет вид A1-Z1
УпорБольш имеет вид A2-Z2
Тогда конкатенации списков
УпорМеньш и [ Х | УпорБольш]
будет соответствовать конкатенация пар
A1-Z1 и [ Х | A2]-Z2
В результате мы получим
А1-Z2, причем Z1 = [ Х | А2]
Пустой список представляется парой Z-Z. Систематически вводя изменения в программу рис. 9.2, мы получим более эффективный способ реализации процедуры быстрсорт, показанный на рис. 9.3 под именем
line(); быстрсорт( Спис, УпорСпис) :-
быстрсорт2( Спис, УпорСпис-[ ] ).
быстрсорт2( [ ], Z-Z).
быстрсорт2( [X | Хвост], A1-Z2) :-
разбиение( X, Хвост, Меньш, Больш),
быстрсорт2( Меньш, А1-[Х | A2] ),
быстрсорт2( Больш, A2-Z2).
line(); Рис. 9. 3. Более эффективная реализация процедуры быстрсорт
с использованием разностного представления списков. Отношение
разбиение( Х, Спис, Меньш, Больш) определено, как на рис. 9.2.
быстрсорт2. Здесь, как и раньше, процедура быстрсорт использует обычное представление списков, но в действительности сортировку выполняет более эффективная процедура быстрсорт2, использующая разностное представление. Эти две процедуры связаны между собой, соотношением
быстрсорт( L, S) :-
быстрсорт2( L, S-[ ] ).
Создание и декомпозиция атомов
Часто желательно информацию, считанную как последовательность символов, иметь в программе в виде атома. Для этой цели существует встроенный предикат name. Он устанавливает взаимосвязь между атомами и их кодировкой в ASCII. Таким образом,
name( A, L)
истинно, если L - список кодов ASCII, кодирующих атом. Например,
name( zx232, [122, 120, 50, 51, 50] )
истинно. Существуют два типичных способа использования name:
(1) дан атом, разбить его на отдельные символы;
(2) дан список символов, объединить их в один атом.
Примером первого случая применения предиката является программа, которая имеет дело с заказами такси и водителями. Все это представлено в программе атомами
заказ1, заказ2, водитель1, водитель2, такси1, таксилюкс
Предикат
такси( X)
проверяет, относится ли атом Х к тем атомам, которые представляют такси:
такси( Х) :-
name( X, Хспис),
nаmе( такси, Тспис),
конк( Тспис, _, Хспис).
конк( [ ], L, L).
конк( [А | L1], L2, [А | L3] ) :-
конк( L1, L2, L3).
Предикаты заказ и водитель можно определить аналогично.
Наш следующий пример иллюстрирует применение объединения отдельных символов в один атом. Мы определим предикат
читпредложение( Списслов)
который считает предложение с произвольной формой на естественном языке и конкретизирует Списслов
некоторым внутренним представлением этого предложения.
В качестве внутреннего представления, обеспечивающего возможность дальнейшей обработки предложения, естественно избрать следующее: каждое слово входного предложения представляется прологовским атомом, а все предложение представляется списком этих атомов. Например, если входной поток таков:
Мэри было приятно видеть неудачу робота.
то цель читпредложение( Предложение)
вызовет конкретизацию
Предложение=['Мэри', было, приятно, видеть, неудачу, робота]
Для простоты будем считать, что каждое предложение оканчивается точкой и внутри него не используются никакие знаки препинания.
Программа для читпредложение
показана на рис. 6.4. Вначале процедура читает текущий входной символ Симв, а затем передает его процедуре читостальное
для завершения работы. Процедура читостальное
должна правильно обработать следующие три случая:
(1) Симв - точка, тогда все сделано.
(2) Симв - пробел, - игнорировать его и читпредложение от остального ввода.
(3) Симв - буква, - сначала считать слово Слово, которое начинается с Симв, а затем запустить читпредложение, чтобы считать оставшуюся часть предложения, породив при этом Списслов. Общим результатом этого будет список [Слово | Списслов].
Процедура, считывающая символы одного слова, такова:
читбуквы( Буква, Буквы, Сделсимв)
Ее три аргумента:
(1) Буква - текущая буква (уже считанная) читаемого слова.
(2) Буквы - список букв (начинающийся с буквы Буква), оставшихся до конца слова.
(3) Следсимв - входной символ, непосредственно следующий за читаемым словом. Следсимв не должен быть буквой.
Мы завершим данный пример замечанием о возможном применения процедуры читпредложение.
Ее можно использовать в программе обработки текста на естественном языке. Предложения, представленные в виде списков слов, имеют удобную форму для дальнейшей обработки при помощи Пролога. В простейшем
line();
/*
Процедура читпредложение считывает предложение и из его слов создает список атомов. Например,
читпредложение( Списслов)
порождает
Списслов=['Мэри', было, приятно, видеть, неудачу, робота]
если входным было предложение
Мэри было приятно видеть неудачу робота.
*/
читпредложение( Списслов) :-
gеt0( Симв),
читостальное( Симв, Списслов).
читостальное( 46, [ ]) :- !.
% Конец предложения: 46 = ASCII-код для ' '
читостальное( 32, Списслов) :- !,
% 32 = ASCII-код для пробела
читпредложение( Списслов).
% Пропустить пробел
читостальное( Буква, [Слово | Списслов]) :-
читбуквы( Буква, Буквы, Следсимв),
% Считать буквы текущего слова
nаmе( Слово, Буквы),
читостальное( Следсимв, Списслов).
читбуквы( 46, [ ], 46) :- !.
% Конец слова: 46 = точка
читбуквы( 32, [ ], 32) :- !.
% Конец слова: 32 = пробел
читбуквы( Бкв, [Бкв | Буквы], Следсимв) :-
get0( Симв),
читбуквы( Симв, Буквы, Следсимв).
line();
Рис. 6. 4. Процедура для преобразования предложения в список атомов.
случае такой обработкой мог бы быть поиск во входном предложении определенных ключевых слов. Значительно более сложной задачей является понимание предложения, т. е. извлечение из него смысла, представленного в некотором избранном формализме. Это важная область исследований в искусственном интеллекте.
Создание и декомпозиция термов: =, functor, arg, name
Имеются три встроенные предиката для декомпозиции и синтеза термов: functor, arg и =.. . Рассмотрим сначала отношение =.. , которое записывается как инфиксный оператор. Цель
Терм =.. L
истинна, если L - список, начинающийся с главного функтора терма Терм, вслед за которым идут его аргументы. Вот примеры:
?- f( а, b) =.. L.
L = [f, а, b]
?- Т =.. [прямоугольник, 3, 5].
Т = прямоугольник( 3, 5)
?- Z =.. [р, X, f( X,Y) ].
Z = p( X, f( X,Y) )
Зачем может понадобиться разбирать терм на составляющие компоненты - функтор и его аргументы? Зачем создавать новый терм из заданного функтора и аргументов? Следующий пример показывает, что это действительно нужно.
Рассмотрим программу, которая манипулирует геометрическими фигурами. Фигуры - это квадраты, прямоугольники, треугольники, окружности в т.д. В программе их можно представлять в виде термов, функтор которых указывает на тип фигуры, а аргументы задают ее размеры:
квадрат( Сторона)
треугольник( Сторона1, Сторона2, Сторона3)
окружность( R)
Одной из операций над такими фигурами может быть увеличение. Его можно реализовать в виде трехаргументного отношения
увел( Фиг, Коэффициент, Фиг1)
где Фиг и Фиг1 - геометрические фигуры одного типа (с одним в тем же функтором), причем параметры Фиг1 равны параметрам Фиг, умноженным на Коэффициент. Для простоты будем считать, что все параметры Фиг, а также Коэффициент уже известны, т. е. конкретизированы числами. Один из способов программирования отношения увел таков:
увел( квадрат( A), F, квадрат( А1) ) :-
A1 is F*A
увел( окружность( R), F, окружность( R1) ) :-
R1 is F*R1
увел( прямоугольник( А, В), F, прямоугольник( А1, В1)) :-
A1 is F*A, B1 is F*B.
Такая программа будет работать, однако она будет выглядеть довольно неуклюже при большом количестве различных типов фигур. Мы будем вынуждены заранее предвидеть все возможные типы, которые могут когда-либо встретиться. Придется заготовить по предложению на каждый тип, хотя во всех этих предложениях по существу говорится одно и то же: возьми параметры исходной фигуры, умножь их на коэффициент и создай фигуру того же типа с этими новыми параметрами.
Ниже приводится программа, в которой делается попытка (неудачная) справиться для начала хотя бы со всеми однопараметрическими фигурами при помощи одного предложения:
увел( Тип( Пар), F, Тип( Пар1) ):-
Пар1 is F*Пар.
Однако в Прологе подобные конструкции, как правило, запрещены, поскольку функтор должен быть атомом, и, следовательно, переменная Тип
синтаксически не будет воспринята как функтор. Правильный метод - воспользоваться предикатом '=..' . Тогда процедура увел будет иметь обобщенную формулировку, пригодную для фигур любых типов:
увел( Фиг, F, Фиг1):-
Фиг =.. [Тип | Параметры],
умножспис( Параметры, F, Параметры1),
Фиг1 =.. [Тип | Параметры)].
умножспис( [ ], _, [ ]).
умножспис( [X | L], F, [X1 | L1] ) :-
X1 is F*X, умножспис( L, F, L1).
Наш следующий пример использования предиката '=..' связан с обработкой символьных выражений (формул), где часто приходится подставлять вместо некоторого подвыражения другое выражение. Мы определим отношение
подставить( Подтерм, Терм, Подтерм1, Терм1)
следующим образом: если все вхождения Подтерм'а в Терм заменить на Подтерм1, то получится Терм1. Например:
?- подставить( sin( x), 2*sin( x)*f( sin( x)), t, F ).
F = 2*t*f( t)
Под "вхождением" Подтерм'а в Терм
мы будем понимать такой элемент Терм'а, который сопоставим с Подтерм'ом. Вхождения будем искать сверху вниз. Поэтому цель
?- подставить( а+b, f( а, А+В), v, F).
даст результат
F = f( а, v) F = f( a, v+v)
А = а
а не А = а+b
В = b В = а+b
При определении отношения подставить
нам нужно рассмотреть несколько случаев и для каждого принять свое решение:
если Подтерм = Терм, то Терм1 = Подтерм1;
иначе если Терм - "атомарный" (не структура),
то Терм1 = Терм (подставлять нечего),
иначе подстановку нужно выполнить над
аргументами Tерм'a.
Эти правила можно превратить в программу, показанную на рис. 7.3.
Термы, полученные при помощи предиката '=..', разумеется, можно использовать и в качестве целей. Это дает возможность программе в процессе вычислений самой порождать и вычислять цели, структура которых не обязательно была известна заранее в момент написания программы. Последовательность целей, иллюстрирующая этот прием, могла бы выглядеть примерно так:
получить( Функтор),
вычислить( Списарг),
Цель =.. [Функтор | Списарг],
Цель
Здесь получить и вычислить - некоторые определенные пользователем процедуры, предназначенные для вычисления компонент цели. После этого цель порождается предикатом '=..', а затем активизируется при помощи простого указания ее имени Цель.
Некоторые реализации Пролога могут содержать требование, чтобы все цели, появляющиеся в программе, по своей синтаксической форме были либо атомами, либо структурами с атомом в качестве главного функтора. Поэтому переменная, вне
line();
% Отношение
%
% подставить( Подтерм, Терм, Подтерм1, Терм1)
%
% состоит в следующем: если все вхождения Подтерм'а в Терм
% заменить на Подтерм1, то получится Терм1.
% Случай 1: Заменить весь терм
подставить( Терм, Терм, Терм1, Терм1) :- !.
% Случай 2: нечего подставлять
подставить( _, Терм, _, Терм) :-
atomic( Терм), !.
% Случай 3: Проделать подстановку в аргументах
подставить( Под, Терм, Под1, Терм1) :-
Терм =.. [F | Арги],
% Выделить аргументы
подспис( Под, Арги, Под1, Арги1),
% Выполнить над ними подстановку
Терм1 =.. [F | Арги1].
подспис( Под, [Терм | Термы], Под1, [Терм1 | Термы1]) :-
подставить( Под, Терм, Под1, Терм1),
подспис( Под, Термы, Под1, Термы1).
line();
Рис. 7. 3. Процедура подстановки в терм вместо одного из его
подтермов некоторого другого подтерма.
зависимости от ее текущей конкретизации, может по своей синтаксической форме не подойти в качестве цели.
Эту трудность можно обойти при помощи еще одного встроенного предиката call (вызов), чьим аргументом является цель, подлежащая вычислению. В соответствий с этим предыдущий пример должен быть переписан так:
. . .
Цель = [Функтор | Списарг],
саll( Цель)
Иногда нужно извлечь из терма только его главный функтор или один из аргументов. В этом случае можно, конечно, воспользоваться отношением '=..' Но более аккуратным и практичным, а также и более эффективным способом будет применение одной из двух новых встроенных процедур: functor и аrg. Вот их смысл: цель
functor( Терм, F, N)
истинна, если F - главный функтор Tepм'a, а N -арность F. Цель
arg( N, Терм, А)
истинна, если А - N-й аргумент в Терм'е, в предположении, что нумерация аргументов идет слева направо и начинается с 1. Примеры для иллюстрации:
?- functor( t( f( x), X, t), Фун, Арность).
Фун = t
Арность = 3
?- аrg( 2, f( X, t( a), t( b) ), Y).
Y = t( a)
?- functor( D, дата, 3),
arg( 1, D, 29),
arg( 2, D, июнь),
arg( 3, D, 1982).
D = дата( 29, июнь, 1982)
Последний пример иллюстрирует особый случай применения предиката functor. Цель functor( D, дата, 3) создает "обобщенный" терм с главным функтором дата и тремя аргументами.Этот терм обобщенный, так как все три его аргумента - не конкретизированные переменные, чья имена генерируются пролог - системой. Например:
D = дата( _5, _6, _7)
Затем эти три переменные конкретизируются при помощи трех целей аrg.
К рассматриваемому множеству встроенных предикатов относится также и введенный в гл. 6 предикат name, предназначенный для синтеза и декомпозиция атомов. Для полноты изложения мы здесь напомним его смысл. Цель
name( A, L)
истинна, если L - список кодов (в кодировке ASCII) символов, входящих в состав атома А.
СПИСКИ, ОПЕРАТОРЫ, АРИФМЕТИКА
В этой главе мы будем изучать специальные способы представления списков. Список - один из самых простых и полезных типов структур. Мы рассмотрим также некоторые программы для выполнения типовых операций над списками и, кроме того, покажем, как можно просто записывать арифметические выражения и операторы, что во многих случаях позволит улучшить "читабельность" программ. Базовый Пролог (глава 2), расширенный этими тремя добавлениями, станет удобной основой для составления интересных программ.
double_line();Списковое представление множества кандидатов
В нашей первой реализации этой идеи мы будем использовать следующее представление для множества
line(); решить( Старт, Решение) :-
вширину( [ [Старт] ], Решение).
вширину( [ [Верш | Путь] | _ ], [Верш | Путь] ) :-
цель( Верш).
вширину( [ [В | Путь] | Пути], Решение ) :-
bagof( [B1, В | Путь ],
( после( В, В1), not принадлежит( В1, [В | Путь])),
НовПути),
% НовПути - ациклические продолжения пути [В | Путь]
конк( Пути, НовПути, Пути1), !,
вширину( Путь1, Решение);
вширину( Пути, Решение).
% Случай, когда у В нет преемника
Рис. 11. 10. Реализации поиска в ширину.
путей-кандидатов. Само множество будет списком путей, а каждый путь - списком вершин, перечисленных в обратном порядке, т. е. головой списка будет самая последняя из порожденных вершин, а последним элементом списка будет стартовая вершина.
Поиск начинается с одноэлементного множества кандидатов
[ [СтартВерш] ]
Общие принципы поиска в ширину таковы:
Для того, чтобы выполнить поиск в ширину при заданном множестве путей-кандидатов, нужно:
если голова первого пути - это целевая вершина, то взять этот путь в качестве решения, иначе
удалить первый путь из множества кандидатов и породить множество всех возможных продолжений этого пути на один шаг; множество продолжений добавить в конец множества кандидатов, а затем выполнить поиск в ширину с полученным новым множеством.
В случае примера рис.11.9 этот процесс будет развиваться следующим образом:
line();
решить( Старт, Решение) :-
вширь( [ [Старт] | Z ]-Z, Решение).
вширь( [ [Верш | Путь] | _ ]-_, [Верш | Путь] ) :-
цель( Верш).
вширь( [ [В | Путь] | Пути]-Z, Решение ) :-
bagof( [B1, В | Путь ],
( после( В, В1),
not принадлежит( В1, [В | Путь]) ),
Нов ),
конк( Нов, ZZ, Z), !,
вширь( Пути-ZZ, Решение);
Пути \== Z, % Множество кандидатов не пусто
вширь( Пути-Z, Решение).
line();
Рис. 11. 11. Программа поиска в ширину более эффективная, чем
программа рис.11.10. Усовершенствование основано на разностном
представлении списка путей-кандидатов.
(1) Начинаем с начального множества кандидатов:
[ [а] ]
(2) Порождаем продолжения пути [а]:
[ [b, а], [с, а] ]
( Обратите внимание, что пути записаны в обратном порядке.)
(3) Удаляем первый путь из множества кандидатов и порождаем его продолжения:
[ [d, b, a], [e, b, а] ]
Добавляем список продолжений в конец списка кандидатов:
[ [с, а], [d, b, a], [e, b, а] ]
(4) Удаляем [с, а], а затем добавляем все его продолжения в конец множества кандидатов. Получаем:
[ [d, b, a], [e, b, а], [f, c, a], [g, c, a] ]
Далее, после того, как пути [d, b, a] и [e, b, а] будут продолжены, измененный список кандидатов примет вид
[[f, c, a], [g, c, a], [h, d, b, a], [i, e, b, a], [j, e, b, a]]
В этот момент обнаруживается путь [f, c, a], содержащий целевую вершину f. Этот путь выдается в качестве решения.
Программа, порождающая этот процесс, показана на рис. 11.10. В этой программе все продолжения пути на один шаг генерируются встроенной процедурой bagof. Кроме того, делается проверка, предотвращающая порождение циклических путей. Обратите внимание на то, что в случае, когда путь продолжить невозможно, и цель bagof терпит неудачу, обеспечивается альтернативный запуск процедуры вширину. Процедуры принадлежит и конк
реализуют отношения принадлежности списку и конкатенации списков соответственно.
Недостатком этой программы является неэффективность операции конк. Положение можно исправить, применив разностное представление списков (см. гл. 8). Тогда множество путей-кандидатов будет представлено парой списков Пути и Z, записанной в виде
Пути-Z
При введении этого представления в программу рис. 11.10 ее можно постепенно преобразовать в программу, показанную на рис. 11.11. Оставим это преобразование читателю в качестве упражнения.
Средства управления
К настоящему моменту мы познакомились с большинством дополнительных средств управления, за исключением repeat (повторение). Здесь мы для полноты приводим список всех таких средств.
отсечение, записывается как '!', предотвращает перебор, введено в гл. 5.
fail - цель, которая всегда терпит неудачу.
true - цель, которая всегда успешна.
not( P) - вид отрицания, который всегда ведет себя в точном соответствии со следующим определением:
not( P) :- P, !, fail; true.
Некоторые проблемы, связанные с отсечением и not
детально обсуждались в гл. 5.
саll( P) активизирует цель Р. Обращение к саll имеет успех, если имеет успех Р.
repeat - цель, которая всегда успешна. Ее особое свойство состоит в том, что она недетерминирована, поэтому всякий раз, как до нее доходит перебор, она порождает новую ветвь вычислений. Цель repeat ведет себя так, как если бы она была определена следующим образом:
repeat.
repeat :- repeat.
Стандартный способ применения repeat
показан в процедуре квадраты, которая читает последовательность чисел и выдает их квадраты. Последовательность чисел заканчивается атомом стоп, который служит для процедуры сигналом окончания работы.
квадраты :-
repeat,
read( X),
( X = стоп, !;
Y is X*X, write( Y), fail ).
Назад | Содержание | Вперёд
Степень достоверности
Наша оболочка экспертной системы, описанная в предыдущем разделе, может работать только с такими вопросами (утверждениями), которые либо истинны, либо ложны. Предметные области, в которых на любой вопрос можно ответить "правда" или "ложь", называются категорическими. Наши правила базы знания (также, как и данные) были категорическими, это были "категорические импликации". Однако многие области экспертных знаний не являются категорическими. Как правило, в заключениях эксперта много догадок (впрочем, высказанных с большой уверенностью), которые обычно верны, но могут быть и исключения. Как данные, относящиеся к конкретной задаче, так и импликации, содержащиеся в правилах, могут быть не вполне определенными. Неопределенность можно промоделировать, приписывая утверждениям некоторые характеристики, отличные от "истина" и "ложь". Характеристики могут иметь свое внешнее выражение в форме дескрипторов, таких, как, например, верно, весьма вероятно, вероятно, маловероятно, невозможно. Другой способ: степень уверенности может выражаться в форме действительного числа, заключенного в некотором интервале, например между 0 и 1 или между -5 и +5. Такую числовую характеристику называют по-разному - "коэффициент определенности", "степень доверия" или "субъективная уверенность". Более естественным было бы использовать вероятности (в математическом смысле слова), но попытки применить их на практике приводят к трудностям. Происходит это по следующим причинам: Экспертам, по-видимому, неудобно мыслить в терминах вероятностей. Их оценки правдоподобия не вполне соответствуют математическому определению вероятностей. Работа с вероятностями, корректная с точки зрения математики, потребовала бы или какой-нибудь недоступной информации, или каких-либо упрощающих допущений, не вполне оправданных с точки зрения практического приложения.
Поэтому, даже если выбранная мера правдоподобия лежит в интервале 0 и 1, более правильным будет называть ее из осторожности "субъективной уверенностью", подчеркивая этим, что имеется в виду оценка, данная экспертом. Оценки эксперта не удовлетворяют всем требованиям теории вероятностей. Кроме того, вычисления над такими оценками могут отличаться от исчисления вероятностей. Но, несмотря на это, они могут служить вполне адекватной моделью того, как человек оценивает достоверность своих выводов.
Для работы в условиях неопределенности было придумано множество различных механизмов. Мы будем рассматривать здесь механизм, используемый в системах Prospector и AL/X для минералогической разведки и локализации неисправностей соответственно. Следует заметить, что модель, применяемая в системе Prospector, несовершенна как с теоретической, так и с практической точек зрения. Однако она использовалась на практике, она проста и может служить хорошей иллюстрацией при изложении основных принципов, а потому вполне подойдет нам, по крайней мере для первого знакомства с этой областью. С другой стороны, известно, что даже в значительно более сложных моделях не обходится без трудностей.
СТИЛЬ И МЕТОДЫ ПРОГРАММИРОВАНИЯ
В этой главе мы рассмотрим некоторые общие принципы хорошего программирования и обсудим, в частности. следующие вопросы: "Как представлять себе прологовские программы? Из каких элементов складывается хороший стиль программирования на Прологе? Как отлаживать пролог - программы? Как повысить их эффективность?"
double_line();Стиль программирования
Подчиняться при программировании некоторым стилистическим соглашениям нужно для того, чтобы уменьшить опасность внесения ошибок в программы и создавать программы, которые легко читать, понимать, отлаживать и модифицировать.
Ниже дается обзор некоторых из составных частей хорошего стиля программирования на Прологе. Мы рассмотрим некоторые общие правила хорошего стиля, табличную организацию длинных процедур и вопросы комментирования программ.
Стратегия поиска в глубину
Существует много различных подходов к проблеме поиска решающего пути для задач, сформулированных в терминах пространства состояний. Основные две стратегии поиска - это поиск в глубину и поиск в ширину. В настоящем разделе мы реализуем первую из них.
Мы начнем разработку алгоритма и его вариантов со следующей простой идеи:
line();Для того, чтобы найти решающий путь Реш из заданной вершины В в некоторую целевую вершину, необходимо: если В - это целевая вершина, то положить Реш = [В], или если для исходной вершины В существует вершина-преемник В1, такая, что можно провести путь Реш1 из В1 в целевую вершину, то положить Реш = [В | Peш1]. line();

Рис. 11. 4. Пример простого пространства состояний: а
- стартовая
вершина, f и j - целевые вершины. Порядок, в которой происходит
проход по вершинам пространства состояний при поиске в глубину:
а, b, d, h, e, i, j. Найдено решение [a, b, e, j]. После возврата
обнаружено другое решение: [а, с, f].
На Пролог это правило транслируется так:
решить( В, [В] ) :-
цель( В).
решить( В, [В | Реш1] ) :-
после( В, В1 ),
решить( В1, Реш1).
Эта программа и есть реализация поиска в глубину. Мы говорим "в глубину", имея в виду тот порядок, в котором рассматриваются альтернативы в пространстве состояний. Всегда, когда алгоритму поиска в глубину надлежит выбрать из нескольких вершин ту, в которую следует перейти для продолжения поиска, он предпочитает самую "глубокую" из них. Самая глубокая вершина - это вершина, расположенная дальше других от стартовой вершины. На рис. 11.4 мы видим на примере, в каком порядке алгоритм проходит по вершинам.
Этот порядок в точности соответствует результату трассировки процесса вычислений в пролог-системе при ответе на вопрос
?- решить( а, Реш).
Поиск в глубину наиболее адекватен рекурсивному стилю программирования, принятому в Прологе. Причина этого состоит в том, что, обрабатывая цели, пролог-система сама просматривает альтернативы именно в глубину.
Поиск в глубину прост, его легко программировать и он в некоторых случаях хорошо работает. Программа для решения задачи о восьми ферзях (см. гл. 4) фактически была примером поиска в глубину. Для того, чтобы можно было применить к этой задаче описанную выше процедуру решить, необходимо сформулировать задачу в терминах пространства состояний. Это можно сделать так:
вершины пространства состояний - позиции, в которых поставлено 0 или более ферзей на нескольких последовательно расположенных горизонтальных линиях доски;
вершина-преемник данной вершины может быть получена из нее после того, как в соответствующей позиции на следующую горизонтальную линию доски будет поставлен еще один ферзь, причем таким образом, чтобы ни один из уже поставленных ферзей не оказался под боем;
стартовая вершина - пустая доска (представляется пустым списком);
целевая вершина - любая позиция с восемью ферзями (правило получения вершины-преемника гарантирует, что ферзи не бьют друг друга).
Позицию на доске будем представлять как список Y-координат поставленных ферзей. Получаем программу:
после( Ферзи, [Ферзь | Ферзи] ) :-
принадлежит( Ферзь, [1, 2, 3, 4, 5, 6, 7, 8] ),
% Поместить ферзя на любую вертикальную линию
небьет( Ферзь, Ферзи).
цель( [ _, _, _, _, _, _, _, _ ] )
% Позиция с восемью ферзями
Отношение небьет означает, что Ферзь
не может поразить ни одного ферзя из списка Ферзи. Эту процедуру можно легко запрограммировать так же, как это сделано в гл. 4. Ответ на вопрос
?- решить( [ ], Решение)
будет выглядеть как список позиций с постепенно увеличивающимся количеством поставленных ферзей. Список завершается "безопасной" конфигурацией из восьми ферзей. Механизм возвратов позволит получить и другие решения задачи.
Поиск в глубину часто работает хорошо, как в рассмотренном примере, однако наша простая процедура решить может попасть в затруднительное положение, причем многими способами. Случится ли это или нет - зависит от структуры пространства состояний. Для того, чтобы затруднить работу процедуры решить в примере рис. 11.4, достаточно внести в задачу совсем небольшое изменение: добавить дугу, ведущую из h в d, чтобы получился цикл (рис. 11.5). В этом случае поиск будет выглядеть так: начиная с вершины а, спускаемся вплоть до h, придерживаясь самой левой ветви графа. На этот раз, в отличие от рис. 11.4, у вершины h будет преемник d. Поэтому произойдет не возврат из h, а переход к d. Затем мы найдем преемника вершины d, т.е. вершину h, и т.д., в результате программа зациклится между h и d.
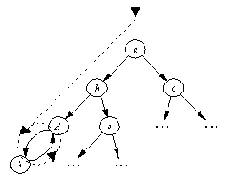
Рис. 11. 5. Начинаясь в а, поиск вглубину заканчивается
бесконечным циклом между d и h: a, b, d, h, d, h, d ... .
Очевидное усовершенствование нашей программы поиска в глубину - добавление к ней механизма обнаружения циклов. Ни одну из вершин, уже содержащихся в пути, построенном из стартовой вершины в текущую вершину, не следует вторично рассматривать в качестве возможной альтернативы продолжения поиска.
Это правило можно сформулировать в виде отношения
вглубину( Путь, Верш, Решение)
Как видно из рис. 11.6, Верш - это состояние, из которого необходимо найти путь до цели; Путь - путь (список вершин) между стартовой вершиной и Верш; Решение - Путь, продолженный до целевой вершины.
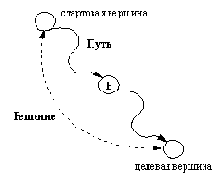
Рис. 11. 6. Отношение вглубину( Путь, В, Решение).
Для облегчения программирования вершины в списках, представляющих пути, будут расставляться в обратном порядке. Аргумент Путь нужен для того,
(1) чтобы не рассматривать тех преемников вершины Верш, которые уже встречались раньше (обнаружение циклов);
(2) чтобы облегчить построение решающего пути Решение. Соответствующая программа поиска в глубину показана на рис. 11.7.
line(); решить( Верш, Решение) :-
вглубину( [ ], Верш, Решение).
вглубину( Путь, Верш, [Верш | Путь] ) :-
цель( Верш).
вглубину( Путь, Верш, Реш) :-
после( Верш, Верш1),
not принадлежит( Верш1, Путь), % Цикл ?
вглубину( [Верш | Путь], Верш1, Реш).
line(); Рис. 11. 7. Программа поиска в глубину без зацикливания.
Теперь наметим один вариант этой программы.
Аргументы Путь и Верш процедуры вглубину можно объединить в один список [Верш | Путь]. Тогда, вместо вершины-кандидата Верш, претендующей на то, что она находится на пути, ведущем к цели, мы будем иметь путь-кандидат П = [Верш | Путь], который претендует на то, что его можно продолжить вплоть до целевой вершины. Программирование соответствующего предиката
вглубину( П, Решение)
оставим читателю в качестве упражнения.
Наша процедура поиска в глубину, снабженная механизмом обнаружения циклов, будет успешно находить решающие пути в пространствах состояний, подобных показанному на рис. 11.5. Существуют, однако, такие пространства состоянии, в которых наша процедура не дойдет до цели. Дело в том, что многие пространства состояний бесконечны. В таком пространстве алгоритм поиска в глубину может "потерять" цель, двигаясь вдоль бесконечной ветви графа. Программа будет бесконечно долго обследовать эту бесконечную область пространства, так и не приблизившись к цели. Пространство состояний задачи о восьми ферзях, определенное так, как это сделано в настоящем разделе, на первый взгляд содержит ловушку именно такого рода. Но оказывается, что оно все-таки конечно, поскольку Y-координаты выбираются из ограниченного множества, и поэтому на доску можно поставить "безопасным образом" не более восьми ферзей.
line(); вглубину2( Верш, [Верш], _ ) :-
цель( Верш).
вглубину2( Верш, [Верш | Реш], МаксГлуб) :-
МаксГлуб > 0,
после( Верш, Верш1),
Maкс1 is МаксГлуб - 1,
вглубину2( Верш1, Реш, Maкс1).
line(); Рис. 11. 8. Программа поиска в глубину с ограничением по глубине.
Для того, чтобы предотвратить бесцельное блуждание по бесконечным ветвям, мы можем добавить в базовую процедуру поиска в глубину еще одно усовершенствование, а именно, ввести ограничение на глубину поиска. Процедура поиска в глубину будет тогда иметь следующие аргументы:
вглубину2( Верш, Решение, МаксГлуб)
Не разрешается вести поиск на глубине большей, чем МаксГлуб. Программная реализация этого ограничения сводится к уменьшению на единицу величины предела глубины при каждом рекурсивном обращений к вглубину2 и к проверке, что этот предел не стал отрицательным. В результате получаем программу, показанную на рис. 11.8.
Структуры
Структурные объекты (или просто структуры) - это объекты, которые состоят из нескольких компонент. Эти компоненты, в свою очередь, могут быть структурами. Например, дату можно рассматривать как структуру, состоящую из трех компонент: день, месяц, год. Хотя они и составлены из нескольких компонент, структуры в программе ведут себя как единые объекты. Для того, чтобы объединить компоненты в структуру, требуется выбрать функтор. Для нашего примера подойдет функтор дата. Тогда дату 1-е мая 1983 г. можно записать так:
дата( 1, май, 1983)
(см. рис. 2.2).
Все компоненты в данном примере являются константами (две компоненты - целые числа и одна - атом). Компоненты могут быть также переменными или структурами. Произвольный день в мае можно представить структурой:
дата( День, май, 1983)
Заметим, что День является переменной и ей можно приписать произвольное значение на некотором более позднем этапе вычислений.
Такой метод структурирования данных прост и эффективен. Это является одной из причин того, почему Пролог естественно использовать для решения задач обработки символьной информации.
Синтаксически все объекты данных в Прологе представляют собой термы. Например,
май
и
дата( 1, май, 1983)
суть термы.
Все структурные объекты можно изображать в виде деревьев (пример см. на рис. 2.2). Корнем дерева служит функтор, ветвями, выходящими из него, - компоненты. Если некоторая компонента тоже является структурой, тогда ей соответствует поддерево в дереве, изображающем весь структурный объект.
Наш следующий пример показывает, как можно использовать структуры для представления геометрических объектов (см. рис. 2.3). Точка в двумерном пространстве определяется двумя координатами; отрезок определяется двумя точками, а треугольник можно задать тремя точками. Введем следующие функторы:
точка
для точек
отрезок
для отрезков и
треугольник
для треугольников.
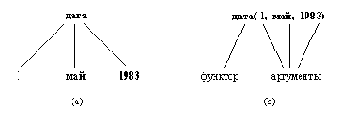
Рис. 2. 2. Дата - пример структурного объекта:
(а) его представление в виде дерева; (б) запись на Прологе.
Тогда объекты, приведенные на рис. 2.3, можно представить следующими прологовскими термами:
Р1 = точка( 1, 1)
P2 = точка( 2, 3)
S = отрезок( P1, P2) =
отрезок( точка( 1, 1), точка( 2, 3) )
Т = треугольник( точка( 4, 2), точка( 6, 4),
точка( 7, 1) )

Рис. 2. 3. Простые геометрические объекты.
Соответствующее представление этих объектов в виде деревьев приводится на рис. 2.4. Функтор, служащий
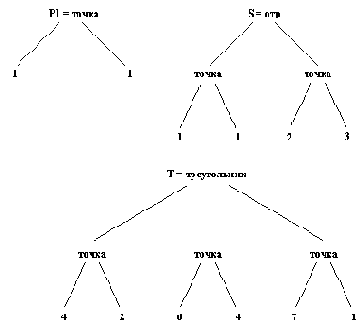
Рис. 2. 4. Представление объектов с рис. 2.3 в виде деревьев.
корнем дерева, называется главным функтором терма.
Если бы в такой же программе фигурировали точки трехмерного пространства, то можно было бы для их представления использовать другой функтор, скажем точка3:
точка3( X, Y, Z)
Можно, однако, воспользоваться одним и тем же именем точка одновременно и для точек двумерного и трехмерного пространств и написать, например, так:
точка( XI, Y1) и точка ( X, Y, Z)
Если одно и то же имя появляется в программе в двух различных смыслах, как в вышеупомянутом примере с точкой, то пролог-система будет различать их по числу аргументов и интерпретировать это имя как два функтора: один - двухаргументный; второй - трех. Это возможно потому, что каждый функтор определяется двумя параметрами:
(1) именем, синтаксис которого совпадает с синтаксисом атомов;
(2) арностью - т. е. числом аргументов.
Как уже объяснялось, все структурные объекты в Прологе - это деревья, представленные в программе термами. Рассмотрим еще два примера, чтобы показать, насколько удобно сложные объекты данных представляются с помощью прологовских термов. На рис. 2.5 показана древовидная структура, соответствующая арифметическому выражению
(а + в)*(с - 5)
В соответствии с введенным к настоящему моменту синтаксисом, такое выражение, используя символы *, + и - в качестве функторов, можно записать следующим образом:
*( +( а, в), -( с, 5) )

Рис. 2. 5. Древовидная структура, соответствующая арифметическому
выражению (а + w)*(s - 5).
Это, конечно, совершенно правильный прологовский терм, однако это не та форма, которую нам хотелось бы иметь, при записи арифметических выражений. Хотелось бы применять обычную инфиксную запись, принятую в математике. На самом деле Пролог допускает использование инфиксной нотации, при которой символы *, + и - записываются как инфиксные операторы. Детали того, как программист может определять свои собственные операторы, мы приведем в гл. 3.
В качестве последнего примера рассмотрим некоторые простые электрические цепи, изображенные на рис. 2.6. В правой части рисунка помещены древовидные представления этих цепей. Атомы r1, r2, r3 и r4 - имена резисторов. Функторы пар и посл обозначают соответственно параллельное и последовательное соединение резисторов.Вот соответствующие прологовские термы:
посл( r1, r2)
пар( r1, r2)
паp( rl, пap( r2, r3) )
пар( r1, посл( пар( r2, r3), r4) )
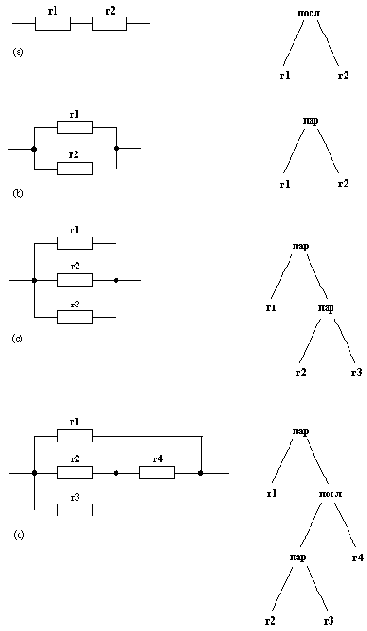
Рис. 2. 6. Некоторые простые электрические цепи и их представление: (а) последовательное соединение резисторов rl и r2; (b) параллельное соединение двух резисторов; (с) параллельное соединение трех резисторов; (d) параллельное соединение r1 и еще одной цепи.
СВЕДЕНИЕ ЗАДАЧ К ПОДЗАДАЧАМ И / ИЛИ-ГРАФЫ
Представление в виде И / ИЛИ-графов наиболее хорошо приспособлено для задач, которые естественным образом разбиваются на взаимно независимые подзадачи. Примерами таких задач могут служить поиск маршрута, символическое интегрирование, а также игровые задачи, доказательство теорем и т.п. В этой главе мы разработаем программы для поиска в И / ИЛИ-графах, в том числе программу поиска с предпочтением, управляемого эвристиками.
double_line();Связь с файлами
До сих пор мы применяли только один метод связи пользователя с программой - пользователь задает программе вопросы, а программа ему отвечает, конкретизируя переменные. Такой механизм связи прост и практичен и, несмотря на свою простоту, обеспечивает ввод и вывод информации. Однако он обладает слишком малой гибкостью и поэтому часто не совсем удобен. В следующих случаях требуется расширение этого основного механизма связи: ввод данных в форме, отличной от вопроса - например, в виде предложений, написанных на английском языке вывод информации в произвольном формате обмен информацией с произвольным файлом, а не только с пользовательским терминалом
Встроенные предикаты, предназначенные для этого расширения, отличаются в разных реализациях Пролога. Мы изучим здесь простой и удобный набор таких

Рис. 6. 1. Связь между пролог-программой и различными файлами.
предикатов, применяемый во многих реализациях. Однако за деталями и специфическими особенностями следует, конечно, обращаться к руководствам по конкретным пролог-системам.
Рассмотрим вначале вопрос о том, как обмениваться информацией с файлами, а затем - как можно вводить и выводить данные в разных форматах.
На рис. 6.1 показана общая ситуация, в которой пролог-программа взаимодействует с несколькими файлами. Она может, в принципе, считывать данные из нескольких входных файлов, называемых также входными потоками, и выводить данные в несколько выходных файлов, называемых выходными потоками. Информация, поступающая с пользовательского терминала, рассматривается просто как еще один входной поток. Аналогично информация, выводимая на этот терминал, рассматривается как один из выходных потоков. На оба этих "псевдофайла" ссылаются с помощью имени user (пользователь). Имена остальных файлов программист должен выбирать в соответствии с правилами именования файлов, принятыми в используемой компьютерной системе.
В каждый момент выполнения пролог-программы лишь два файла являются "активными": один для ввода, другой - для вывода.
Эти два файла называются текущим входным потоком и текущим выходным потоком соответственно. В начальный момент эти два потока соответствуют терминалу. Текущий входной поток может быть заменен на другой файл ИмяФайла посредством цели
see( ИмяФайла)
( Смотри(ИмяФайла) )
Такая цель всегда успешна (если только с файлом ИмяФайла
все в порядке), а в качестве побочного эффекта происходит переключение ввода с предыдущего входного потока на файл ИмяФайла. Поэтому типичным примером использования предиката see является следующая последовательность целей, которая считывает информацию из файла файл1, а затем переключается обратно на терминал:
. . .
see( файл1),
читать_из_файла( Информация),
see( user),
( user - пользователь)
. . .
Текущий выходной поток может быть изменен при помощи цели вида
tell( ИмяФайла)
( сообщить( ИмяФайла) )
Следующая последовательность целей выводит некоторую информацию в файл3, а после этого перенаправляет последующий вывод обратно на терминал:
. . .
tell( файл3),
записать_в_файл( Информация),
tell( user),
. . .
Цель
seen
( конец чтения)
закрывает текущий входной файл. Цель
told
( конец записи)
закрывает текущий выходной файл.
Файлы могут обрабатываться только последовательно. В этом смысле все файлы ведут себя так же, как терминал. Каждый запрос на чтение из входного файла приводит к чтению в текущей позиции текущего входного потока. После этого чтения текущая позиция, естественно, будет перемещена на следующий, еще не прочитанный элемент данных. Следующий запрос на чтение приведет к считыванию, начиная с этой новой текущей позиции. Если запрос на чтение делается в конце файла, то в качестве ответа на такой запрос выдается атом end_of_file (конец файла). Считанную один раз информацию считать вторично невозможно.
Запись производится точно так же, каждый запрос на вывод информации приведет к тому, что она будет присоединена в концу текущего выходного потока. Невозможно сдвинуться назад и переписать часть файла.
Все файлы являются "текстовыми", т. е. файлами, состоящими из символов. Символы - это буквы, цифры и специальные знаки. О некоторых из них говорят, что они непечатаемые, поскольку, будучи выведенными на терминал, они не появляются на экране. Однако их присутствие может сказаться каким-либо другим образом, например появятся пробелы или пустые строки.
Существуют два основных способа, с помощью которых файлы рассматриваются в Прологе в зависимости от формы записанной в них информации.
Один способ - рассматривать символ как основной элемент файла. Соответственно один запрос на ввод или вывод приведет к чтению или записи одного символа. Для этой цели предназначены встроенные предикаты get, get0 и put
(получить, получить0 и выдать).
Другой способ рассматривать файл - считать, что в качестве основных элементов построения файла используются более крупные единицы текста. Такой естественной более крупной единицей является прологовский терм. Поэтому каждый запрос на ввод/вывод такого типа приведет к переносу целого терма из текущего входного потока или в текущий выходной поток соответственно. Предикатами для переноса термов являются предикаты read и write
(читать и писать). В этом случае информация в файле должна, конечно, по форме соответствовать синтаксису термов.
Очевидно, что выбор формы организации файла зависит от задачи. Всякий раз, когда особенности задачи допускают естественное представление информации в соответствии с синтаксисом термов, следует предпочесть файлы, состоящие из термов. Тогда появится возможность за одно обращение и вводу или выводу пересылать целые осмысленные фрагменты информации. С другой стороны, существуют задачи, природа которых диктует иную организацию файлов. Примером такого рода задачи является обработка предложений естественного языка, скажем, для организации диалога между системой и пользователем на английском языке. В таких случаях файлы следует рассматривать как последовательности символов, которые не укладываются в синтаксис термов.
Назад | Содержание
| Вперёд
Табличная организация длинных процедур
Длинные процедуры допустимы, если они имеют регулярную структуру. Обычно эта структура представляет собой множество фактов, соответствующее определению какого-либо отношения в табличной форме. Преимущества такой организации длинной процедуры состоят в том, что: Ее структуру легко понять. Ее удобно совершенствовать: улучшать ее можно, просто добавляя новые факты. Ее легко проверять и модифицировать (просто заменяя отдельные факты, независимо от остальных).
8. 3. 3. Комментирование
Программные комментарии должны объяснять в первую очередь, для чего программа предназначена и как ею пользоваться, и только затем - подробности используемого метода решения и другие программные детали. Главная цель комментариев - обеспечить пользователю возможность применять программу, понимать ее и, может быть, модифицировать. Комментарии должны содержать в наиболее краткой форме всю необходимую для этого информацию. Недостаточное комментирование - распространенная ошибка, однако, программу можно и перенасытить комментариями. Объяснения деталей, которые и так ясны из самого текста программы, являются ненужной перегрузкой.
Длинные фрагменты комментариев следует располагать перед текстом, к которому они относятся, в то время как короткие комментарии должны быть вкраплены в сам текст. Информация, которую в самом общем случае следует включать в комментарии, должна схватывать следующие вопросы: Что программа делает, как ею пользоваться (например, какую цель следует активизировать и каков вид ожидаемых результатов), примеры ее применения. Какие предикаты относятся к верхнему уровню? Как представлены основные понятия (объекты)? Время выполнения и требования по объему памяти. Каковы ограничения на программу? Использует ли она какие-либо средства, связанные с конкретной операционной системой? Каков смысл предикатов программы? Каковы их аргументы? Какие аргументы являются "входными" и какие - "выходными", если это известно? (В момент запуска предиката входные аргументы имеют полностью определенные значения, не содержащие не конкретизированных переменных.) Алгоритмические и реализационные детали.
Назад | Содержание | Вперёд
Трудности с отсечением и отрицанием
Используя отсечение, мы кое-что выиграли, но не совсем даром. Преимущества и недостатки применения отсечения были показаны на примерах из предыдущих разделов. Давайте подытожим сначала преимущества:
(1) При помощи отсечения часто можно повысить эффективность программы. Идея состоит в том, чтобы прямо сказать пролог-системе: не пробуй остальные альтернативы, так как они все равно обречены на неудачу.
(2) Применяя отсечение, можно описать взаимоисключающие правила, поэтому есть возможность запрограммировать утверждение:
если условие Р, то
решение Q,
иначе решение R
Выразительность языка при этом повышается.
Ограничения на использование отсечения проистекают из того, что есть опасность потерять такое важное для нас соответствие между декларативным и процедурным смыслами программы. Если в программе нет отсечений, то мы можем менять местами порядок предложений и целей, что повлияет только на ее эффективность, но не на декларативный смысл. Если же отсечения в ней присутствуют, то изменение порядка предложений может повлиять на ее декларативный смысл. Это значит, что программа с измененным порядком, возможно, будет давать результаты, отличные от результатов исходной программы. Вот пример, демонстрирующий этот факт:
р :- а, b.
р :- с.
Декларативный смысл программы: р истинно тогда и только тогда, когда истинны одновременно и а, и b или истинно с. Это можно записать в виде такой логической формулы:
р <===> (а & b) U с
Можно поменять порядок этих двух предложений, но декларативный смысл останется прежним. Введем теперь отсечение
p :- а, !, b.
р :- с.
Декларативный смысл станет теперь таким:
р <===> (а & b) U ( ~а & с)
Если предложения поменять местами
р :- с.
р :- а, !, b.
декларативный смысл станет таким:
р <===> с U ( а & b)
Важным моментом здесь является то, что при использовании отсечения требуется уделять больше внимания процедурным аспектам. К несчастью, эта дополнительная трудность повышает вероятность ошибок программирования.
В наших примерах из предыдущего раздела мы видели, что удаление отсечений из программы может привести к изменению ее декларативного смысла. Но были также в такие случаи, когда отсечение на него не влияло. Использование отсечений последнего типа требует меньшей осторожности, и поэтому такие отсечения иногда называют "зелеными отсечениями". С точки зрения наглядности программы такие отсечения "невинны" и их использование вполне приемлемо. При чтении программы их можно просто игнорировать.
Напротив, отсечения, влияющие на декларативный смысл, называются "красными". Красные отсечения -это такие отсечения, которые делают программу трудной для понимания, и их нужно применять с особой осторожностью.
Отсечение часто используется в комбинации со специальной целью fail. В частности, мы определили отрицание какой-либо цели (not), как ее неуспех. Определенное таким образом отрицание представляет собой просто особый (более ограниченный) вид отсечения. Из соображений ясности программ мы предпочтем пользоваться not вместо комбинации отсечение - неуспех (всюду, где возможно), поскольку отрицание является понятием более высокого уровня, чем отсечение - неуспех.
Следует заметить, что использование оператора not также может приводить к неприятностям, и его тоже следует применять с осторожностью. Трудность заключается в том, что тот оператор not, который был нами определен, не в точности соответствует отрицанию в математике.
Если спросить
?- not человек( мэри).
система, возможно, ответит "да". Не следует понимать этот ответ как "мэри не человек". Что в действительности пролог-система хочет сказать своим "да", так это то, что программе не хватает информации для доказательства утверждения "Мэри - человек". Это происходит потому, что при обработке цели not система не пытается доказать истинность этой цели впрямую. Вместо этого она пытается доказать противоположное утверждение, и если такое противоположное утверждение доказать не удается, система считает, что цель not - успешна. Такое рассуждение основано на так называемом предположении о замкнутости мира. В соответствии с этим постулатом мир замкнут в том смысле, что все в нем существующее либо указано в программе, либо может быть из нее выведено. И наоборот - если что-либо не содержится в программе (или не может быть из нее выведено), то оно не истинно и, следовательно, истинно его отрицание. Это обстоятельство требует особого внимания, поскольку мы обычно не считаем мир замкнутым: если в программе явно не сказано, что
человек( мэри)
то мы этим обычно вовсе не хотим сказать, что Мэри не человек.
Дальнейшее изучение опасных аспектов использования not проведем на таком примере:
r( а).
g( b).
р( X) :- not r( X).
Если спросить теперь
?- g( X), р( Х).
система ответит
Х = b
Если же задать тот же вопрос, но в такой форме
?- р( X), g( X).
система ответит
nо (нет)
Читателю предлагается проследить работу программы по шагам, чтобы понять, почему получились разные ответы.Основная разница между вопросами состоит в том, что переменная Х к моменту вычисления р( X) в первом случае была уже конкретизирована, в то время как во втором случае этого еще не произошло.
Мы детально обсудили аспекты применения отсечения, которое неявно присутствует в not. При этом нами руководило желание предупредить пользователей о соблюдении необходимой осторожности, а вовсе не желание убедить их совсем не пользоваться этим оператором. Отсечение полезно, а часто и необходимо. А что касается трудностей Пролога, порождаемых отсечением, то подобные неудобства часто возникают и при программировании на других языках.
Удаление элемента
Удаление элемента Х из списка L можно запрограммировать в виде отношения
удалить( X, L, L1)
где L1 совпадает со списком L, у которого удален элемент X. Отношение удалить можно определить аналогично отношению принадлежности. Имеем снова два случая:
(1) Если Х является головой списка, тогда результатом удаления будет хвост этого списка.
(2) Если Х находится в хвосте списка, тогда его нужно удалить оттуда.
удалить( X, [X | Хвост], Хвост).
удалить( X, [Y | Хвост], [ Y | Хвост1] ) :-
удалить( X, Хвост, Хвост1).
как и принадлежит, отношение удалить по природе своей недетерминировано. Если в списке встречается несколько вхождений элемента X, то удалить сможет исключить их все при помощи возвратов. Конечно, вычисление по каждой альтернативе будет удалять лишь одно вхождение X, оставляя остальные в неприкосновенности. Например:
?- удалить( а, [а, b, а, а], L].
L = [b, а, а];
L = [а, b, а];
L = [а, b, а];
nо (нет)
При попытке исключить элемент, не содержащийся в списке, отношение удалить потерпит неудачу.
Отношение удалить можно использовать в обратном направлении для того, чтобы добавлять элементы в список, вставляя их в произвольные места. Например, если мы хотим во все возможные места списка [1, 2, 3] вставить атом а, то мы можем это сделать, задав вопрос: "Каким должен быть список L, чтобы после удаления из него элемента а получился список [1, 2, 3]?"
?- удалить( а, L, [1, 2, 3] ).
L = [а, 1, 2, 3];
L = [1, а, 2, 3];
L = [1, 2, а, 3];
L = [1, 2, 3, а];
nо (нет)
Вообще операция по внесению Х в произвольное место некоторого списка Список, дающее в результате БольшийСписок, может быть определена предложением:
внести( X, Список, БольшийСписок) :-
удалить( X, БольшийСписок, Список).
В принадлежит1 мы изящно реализовали отношение принадлежности через конк. Для проверки на принадлежность можно также использовать и удалить. Идея простая: некоторый Х принадлежит списку Список, если Х можно из него удалить:
принадлежит2( X, Список) :-
удалить( X, Список, _ ).
УПРАВЛЕНИЕ ПЕРЕБОРОМ
Мы уже видели, что программист может управлять процессом вычислений по программе, располагая ее предложения и цели в том или ином порядке. В данной главе мы рассмотрим еще одно средство управления, получившее название "отсечение" (cut) и предназначенное для ограничения автоматического перебора.
double_line();и такое определение? Сможете ли
1. 6. Рассмотрим другой вариант отношения предок:
предок( X, Z) :-
родитель( X, Z).
предок( X, Z) :-
родитель( Y, Z).
предок( X, Y).
Верно ли и такое определение? Сможете ли Вы изменить диаграмму на рис. 1.7 таким образом, чтобы она соответствовала новому определению?
Посмотреть ответ
1. 7. Постарайтесь понять, как пролог-система, используя программу, приведенную на рис. 1.8, выводит ответы на указанные ниже вопросы. Попытайтесь нарисовать соответствующие диаграммы вывода по типу тех, что изображены на рис.1.9 -1.11. Будут ли встречаться возвраты при выводе ответов на какие-либо из этих вопросов?
(a) ?- родитель( пам, боб).
(b) ?- мать( пам, боб).
(с) ?- родительродителя( пам, энн).
(d) ?- родительродителя( боб, джим).
Посмотреть ответ
Назад | Содержание | Вперёд
10. 3. Определите отношение
avl( Дер)
для проверки того, является ли Дер AVL-деревом, т.е. верно ли, что любые два его поддерева, подсоединенные к одной и той же вершине, отличаются по глубине не более чем на 1. Двоичные
line(); % Вставление элемента в AVL-справочник
доб_аvl( nil/0, X, д( nil/0, X, nil/0)/1).
% Добавить Х к пустому дереву
доб_аvl( д( L, Y, R)/Ну, X, НовДер) :-
% Добавить Х к непустому дереву
больше( Y, X),
доб_аvl( L, X, д( L1, Z, L2)/ _ ),
% Добавить к левому поддереву
соединить( L1, Z, L2, Y, R, НовДер).
% Сформировать новое дерево
доб_avl( д( L, Y, R)/Ну, X, НовДер) :-
больше( X, Y),
12. 1. Определите отношения после, цель и h для задачи поиска маршрута рис. 12.2. Посмотрите, как наш алгоритм поиска с предпочтением будет вести себя при решении этой задачи.
Назад | Содержание | Вперёд
12. 2. Введите в программу поиска с предпочтением, приведенную на рис. 12.3, подсчет числа вершин, порожденных в процессе поиска. Один из простых способов это сделать - хранить текущее число вершин в виде факта, устанавливаемого при помощи assert. Всегда, когда порождаются новые вершины, уточнять это значение при помощи retract и assert. Проведите эксперименты с различными эвристическими функциями задачи "игра в восемь" с целью оценить их эвристическую силу. Используйте для этого вычисленное количество порожденных вершин.
Назад | Содержание | Вперёд
13. 4. Напишите процедуру
отобр2( РешДер)
для отображения решающего дерева, найденного программой и_или рис. 13.12. Формат отображения пусть будет аналогичен тому, что применялся в процедуре отобр (рис. 13.8), так что процедуру отобр2 можно получить, внеся в отобр изменения, связанные с другим представлением деревьев. Другая полезная модификация - заменить в отобр цель write( Верш) на процедуру, определяемую пользователем
печверш( Верш, H)
которая выведет Верш в удобной для пользователя форме, а также конкретизирует Н в соответствии с количеством символов, необходимом для представления Верш в этой форме. В дальнейшем Н будет использоваться как величина отступа для поддеревьев.
14. 3. База знаний может, в принципе, содержать циклы. Например:
прав1: если бутылка_пуста то джон_пьян.
прав2: если джон_пьян то бутылка_пуста.
Работая с подобной базой знаний, наша процедура рассмотреть может зациклиться на обработке одних и тех же целей. Внесите в процедуру рассмотреть изменения, предотвращающие зацикливание. Используйте для этого объект Трасса. Однако соблюдайте осторожность: если текущая цель сопоставима с одной из предыдущих целей, то такую ситуацию следует рассматривать как цикл только в том случае, когда текущая цель имеет большую, степень общности, чем предыдущая.
Назад | Содержание | Вперёд
2. 9. Рассмотрите программу на рис. 2.10 и по типу того, как это сделано на рис. 2.10, проследите процесс вычисления пролог-системой вопроса
?- большой( X), темный( X).
Сравните свое описание шагов вычисления с описанием на рис. 2.10, где вычислялся, по существу, тот же вопрос, но с другой последовательностью целей:
?- темный( X), большой( X).
В каком из этих двух случаев системе приходится производить большую работу для нахождения ответа?
Посмотреть ответ
Назад | Содержание | Вперёд
2. 10. Что будет, если пролог-системе задать такой вопрос:
?- Х = f( X).
Успешным или неуспешным будет здесь сопоставление? По определению унификации в логике, сопоставление должно быть неуспешным, а что будет в соответствии с нашим определением сопоставления из раздела 2.2? Попробуйте объяснить, почему многие реализации Пролога отвечают на вышеприведенный вопрос так:
X = f(f(f(f(f(f(f(f(f(f(f(f(f(f(f( ...
Посмотреть ответ
4. 3. Завершите определение отношения nребенок, определив отношение
n_элемент( N, Список, X)
которое выполняется, если Х является N-м элементом списка Список.
Посмотреть ответ
Назад | Содержание | Вперёд
4. 6. При поиске решения программа, приведенная на рис. 4.7, проверяет различные значения Y-координат ферзей. В каком месте программы задается порядок перебора альтернативных вариантов? Как можно без труда модифицировать программу, чтобы этот порядок изменился? Поэкспериментируйте с разными порядками, имея в виду выяснить, как порядок перебора альтернатив влияет на эффективность программы.
4. 7. Пусть поля доски представлены парами своих координат в виде X/Y, где как X, так и Y принимают значения от 1 до 8.
(а) Определите отношение ходконя( Поле1, Поле2), соответствующее ходу коня на шахматной доске. Считайте, что Поле1 имеет всегда конкретизированные координаты, в то время, как координаты поля Поле2 могут и не быть конкретизированы. Например:
?- ходконя( 1/1, S).
S = 3/2;
S = 2/3;
no (нет)
(b) Определите отношение путьконя( Путь), где Путь - список полей, представляющих соответствующую правилам игры последовательность ходов коня по пустой доске.
(с) Используя отношение путьконя, напишите вопрос для нахождения любого пути, состоящего из 4-х ходов, и начинающегося с поля 2/1, а заканчивающегося на противоположном крае доски (Y= 8). Этот путь должен еще проходить после второго хода через поле 5/4.
Посмотреть ответ
6. 3. Обобщите процедуру сжатие на случай запятых. Все пробелы, стоящие непосредственно перед запятой, нужно убрать, а после каждой запятой нужно поместить единственный пробел.
Назад | Содержание | Вперёд
9. 14. Наша процедура изображает дерево, ориентируя его необычным образом: корень находится слева, а листья - справа. Напишите (более сложную) процедуру для отображения дерева, ориентированного обычным образом, т.е. с корнем наверху и листьями внизу.
Посмотреть ответ
Назад | Содержание | Вперёд
9. 15. Рассмотрите остовные деревья в случае, когда каждому ребру графа приписана его стоимость. Пусть стоимость остовного дерева определена как сумма стоимостей составляющих его ребер. Напишите программу построения для заданного графа его остовного дерева минимальной стоимости.
у которого есть сестра, имеет
1. 3. Оттранслируйте следующие утверждения в правила на Прологе:
(a) Всякий, кто имеет ребенка, - счастлив (введите одноаргументное отношение счастлив).
(b) Всякий X, имеющий ребенка, у которого есть сестра, имеет двух детей (введите новое отношение иметьдвухдетей).
Посмотреть ответ
1. 4. Определите отношение внук, используя отношение родитель. Указание: оно будет похоже на отношение родительродителя (см. рис. 1.3).
Посмотреть ответ
1. 5. Определите отношение тетя( X, Y) через отношение родитель и сестра. Для облегчения работы можно сначала изобразить отношение тетя в виде диаграммы по типу тех, что изображены на рис. 1.3.
Посмотреть ответ
1. 1. Считая, что отношение родитель определено так же, как и раньше в данном разделе (см. рис. 1.1), найдите, какими будут ответы пролог-системы на следующие вопросы:
(a) ? - родитель ( джим, X).
(b) ? - родитель( X, джим).
(c) ? - родитель( пам,Х), родитель( Х, пат).
(d) ? - родитель( пам, X), родитель( Х, Y),
родитель( Y, джим).
Посмотреть ответ
1. 2. Сформулируйте на Прологе следующие вопросы об отношении родитель:
(a) Кто родитель Пат?
(b) Есть ли у Лиз ребенок?
(c) Кто является родителем родителя Пат?
Посмотреть ответ
Назад | Содержание | Вперёд
11. 1. Напишите процедуру поиска в глубину (с обнаружением циклов)
вглубину1( ПутьКандидат, Решение)
отыскивающую решающий путь Решение как продолжение пути ПутьКандидат. Оба пути представляйте списками вершин, расположенных в обратном порядке так, что целевая вершина окажется в голове списка Решение.
Посмотреть ответ
11. 2. Напишите процедуру поиска в глубину, сочетающую в себе обнаружение циклов с ограничением глубины, используя рис. 11.7 и 11.8.
11. 3. Проведите эксперимент по применению программы поиска в глубину к задаче планирования в "мире кубиков" (рис. 11.1).
11. 4. Напишите процедуру
отобр( Ситуация)
для отображения состояния задачи "перестановки кубиков". Пусть Ситуация - это список столбиков, а столбик, в свою очередь, - список кубиков. Цель
отобр( [ [a], [e, d], [с, b] ] )
должна отпечатать соответствующую ситуацию, например так:
е с
a d b
================
Назад | Содержание | Вперёд
11. 5. Перепишите программу поиска в ширину рис. 11.10, используя разностное представление для списка путей-кандидатов и покажите, что в результате получится программа, приведенная на рис. 11.11. Зачем в программу рис. 11.11 включена цель
Пути \== Z
Проверьте, что случится при поиске в пространстве состояний рис. 11.9, если эту цель опустить. Различие в выполнении программы, возникнет только при попытке найти новые решения в ситуации, когда не осталось больше ни одного решения.
11. 6. Как программы настоящего раздела можно использовать для поиска, начинающегося от стартового множества вершин, вместо одной стартовой вершины?
Посмотреть ответ
11. 7. Как программы этой главы можно использовать для поиска в обратном направлении, т.е. от целевой вершины к стартовой вершине (или к одной из стартовых вершин, если их несколько). Указание: переопределите отношение после. В каких ситуациях обратный поиск будет иметь преимущества перед прямым поиском?
11. 8. Иногда выгодно сделать поиск двунаправленным, т. е. продвигаться одновременно с двух сторон от стартовой и целевой вершин. Поиск заканчивается, когда оба пути "встречаются". Определите пространство поиска (отношение после) и целевое отношение для заданного графа таким образом, чтобы наши процедуры поиска в действительности выполняли двунаправленный поиск.
11. 9. Проведите эксперименты с различными методами поиска применительно к задаче планирования в "мире кубиков".
Назад | Содержание | Вперёд
10. 1. Определите отношение
внутри( Эдем, Дер)
для поиска элемента Элем в 2-3 справочнике Дер.
Посмотреть ответ
10. 2. Введите в программу рис. 10. 6 изменения для устранения лишних возвратов (определите отношения встав2 и соединить).
line(); % Отображение 2-3 справочников
отобр(Д) :- 15
отобр( Д, 0). --
отобр( nil, _ ). 15
13. 1. Закончите составление программы поиска в глубину (с ограничением) для И / ИЛИ-графов, намеченную в настоящем разделе.
13. 2. Определите на Прологе И / ИЛИ-пространство для задачи "ханойская башня" и примените к нему процедуры поиска настоящего раздела.
13. 3. Рассмотрите какую-нибудь простую детерминированную игру двух лиц с полной информацией и дайте определение ее И / ИЛИ-представления. Используйте программу поиска в И / ИЛИ-графах для построения выигрывающих стратегий в форме И / ИЛИ-деревьев.
Назад | Содержание | Вперёд
14. 1. Рассмотрите "если-то"-правила рис. 14.2-14.4 и транслируйте их в нашу систему обозначений для правил. Предложите расширение нотации, чтобы, при необходимости, можно было работать с оценками уверенности.
line(); % Небольшая база знаний для локализации неисправностей в
% электрической схеме
% Если прибор включен, но не работает, и предохранитель цел,
% то прибор неисправен.
правило_поломки:
если
вкл( Прибор) и
прибор( Прибор) и
не работает( Прибор) и
соед( Прибор, Предохр) и
доказано( цел( Предохр) )
2. 1. Какие из следующих выражений представляют собой правильные объекты в смысле Пролога? Что это за объекты (атомы, числа, переменные, структуры)?
(а) Диана
(b) диана
(с) 'Диана'
(d) _диана
(e) 'Диана едет на юг'
(f) едет( диана, юг)
(g) 45
(h) 5( X, Y)
(i) +( север, запад)
(j) три( Черные( Кошки) )
Посмотреть ответ
2. 2. Предложите представление для прямоугольников, квадратов и окружностей в виде структурных объектов Пролога. Используйте подход, аналогичный приведенному на рис. 2.4. Например, прямоугольник можно представить четырьмя точками (а может быть, только тремя точками). Напишите несколько термов конкретных объектов такого типа с использованием предложенного вами представления.
Назад | Содержание | Вперёд
2. 3. Будут ли следующие операции сопоставления успешными или неуспешными? Если они будут успешными, то какова будет результирующая конкретизация переменных?
(а) точка( А, В) = точка( 1, 2)
(b) точка( А, В) = точка( X, Y, Z)
(c) плюс( 2, 2) = 4
(d) +( 2, D)= +( Е, 2)
(е) треугольник( точка( -1, 0), Р2, Р3) =
треугольник( Р1, точка( 1, 0), точка( 0, Y)
Результирующая конкретизация определяет семейство треугольников. Как бы Вы описали это семейство?
Посмотреть ответ
2. 4 Используя представление отрезков, применявшееся в данной разделе, напишите терм, соответствующий любому отрезку на вертикальной прямой x = 5.
Посмотреть ответ
2. 5. Предположим, что прямоугольник представлен термом прямоугольник( P1, P2, P3, Р4), где Р - вершины прямоугольника, положительно упорядоченные. Определите отношение
регулярный( R)
которое имеет место, если R - прямоугольник с вертикальными и горизонтальными сторонами.
Посмотреть ответ
Назад | Содержание | Вперёд
2. 6. Рассмотрим следующую программу:
f( 1, один).
f( s(1), два).
f( s(s(1)), три).
f( s(s(s(X))), N) :-
f(X, N).
Как пролог- система ответит на следующие вопросы? Там, где возможны несколько ответов, приведите по крайней мере два.
(a) ?- f( s( 1), A).
(b) ?- f( s(s(1)), два).
(c) ?- f( s(s(s(s(s(s(1)))))), С).
(d) ?- f( D, три).
Посмотреть ответ
2. 7. В следующей программе говорится, что два человека являются родственниками, если
(a) один является предком другого, или
(b) у них есть общий предок, или
(c) у них есть общий потомок.
родственники( X, Y) :-
предок( X, Y).
родственники( X, Y) :-
предок( Y, X).
родственники( X, Y) :-
% X и Y имеют общего предка
предок( Z, X),
предок( Z, Y).
родственники( X, Y) :-
% X и Y имеют общего потомка
предок( X, Z),
предок( Y, Z).
Сможете ли вы сократить эту программу, используя запись с точками с запятой?
Посмотреть ответ
2. 8. Перепишите следующую программу, не пользуясь точками с запятой.
преобразовать( Число, Слово) :-
Число = 1, Слово = один;
Число = 2, Слово = два;
Число = 3, Слово = три.
Посмотреть ответ
Назад | Содержание | Вперёд
3. 12. Если принять такие определения
:- ор( 300, xfy, играет_в).
:- ор( 200, xfy, и).
то два следующих терма представляют собой синтаксически правильные объекты:
Tepмl = джимми играет_в футбол и сквош
Терм1 = сьюзан играет_в теннис и баскетбол и волейбол
Как эти термы интерпретируются пролог-системой? Каковы их главные функторы и какова их структура?
Посмотреть ответ
3. 13. Предложите подходящее определение операторов ("работает", "в", "нашем"), чтобы можно было писать предложения типа:
диана работает секретарем в нашем отделе.
а затем спрашивать:
?- Кто работает секретарем в нашем отделе.
Кто = диана
?- диана работает Кем.
Кем = секретарем в нашем отдела
Посмотреть ответ
3. 14. Рассмотрим программу:
t( 0+1, 1+0).
t( X+0+1, X+1+0).
t( X+1+1, Z) :-
t( X+1, X1),
t( X1+1, Z).
Как данная программа будет отвечать на ниже перечисленные вопросы, если '+' "- это (как обычно) инфиксный оператор типа yfx?
(a) ?- t( 0+1, А).
(b) ?- t( 0+1+1, В).
(с) ?- t( 1+0+1+1+1, С).
(d) ?- t( D, 1+1+1+0).
Посмотреть ответ
3. 15. В предыдущем разделе отношения между списка ми мы записывали так:
принадлежит( Элемент, Список),
3. 16. Определите отношение
mах( X, Y, Мах)
так, чтобы Мах равнялось наибольшому из двух чисел Х и Y.
Посмотреть ответ
3. 17. Определите предикат
максспис( Список, Мах)
так, чтобы Мах равнялось наибольшему из чисел, входящих в Список.
Посмотреть ответ
3. 18. Определите предикат
сумспис( Список, Сумма)
так, чтобы Сумма равнялось сумме чисел, входящих в Список.
Посмотреть ответ
3. 19. Определите предикат
упорядоченный( Список)
который принимает значение истина, если Список представляет собой упорядоченный список чисел. Например: упорядоченный [1, 5, 6, 6, 9, 12] ).
Посмотреть ответ
3. 20. Определите предикат
подсумма( Множ, Сумма, ПодМнож)
где Множ это список чисел, Подмнож подмножество этих чисел, а сумма чисел из ПодМнож равна Сумма. Например:
?- подсумма( [1, 2. 5. 3. 2], 5, ПМ).
ПМ = [1, 2, 2];
ПМ = [2, 3];
ПМ = [5];
. . .
Посмотреть ответ
3. 21. Определите процедуру
между( Nl, N2, X)
которая, с помощью перебора, порождает все целые числа X, отвечающие условию Nl <=X <=N2.
Посмотреть ответ
3. 22. Определите операторы 'если', 'то', 'иначе' и ':=" таким образом, чтобы следующее выражение стало правильным термом:
если Х > Y то Z := Х иначе Z := Y
Выберите приоритеты так, чтобы 'если' стал главным функтором. Затем определите отношение 'если' так, чтобы оно стало как бы маленьким интерпретатором выражений типа 'если-то-иначе'.
3. 1. (а) Используя отношение конк, напишите цель, соответствующую вычеркиванию трех последних элементов списка L, результат - новый список L1. Указание: L - конкатенация L1 и трехэлементного списка.
(b) Напишите последовательность целей для порождения списка L2, получающегося из списка L вычеркиванием его трех первых и трех последних элементов.
Посмотреть ответ
3. 2. Определите отношение
последний( Элемент, Список)
так, чтобы Элемент являлся последним элементом списка Список. Напишите два варианта определения: (а) с использованием отношения конк, (b) без использования этого отношения.
Посмотреть ответ
3. 3. Определите два предиката
четнаядлина( Список) и нечетнаядлина( Список)
таким образом, чтобы они были истинными, если их аргументом является список четной или нечетной длины соответственно. Например, список [а, b, с, d] имеет четную длину, a [a, b, c] - нечетную.
Посмотреть ответ
3. 4. Определите отношение
обращение( Список, ОбращенныйСписок),
которое обращает списки. Например,
обращение( [a, b, c, d], [d, c, b, a] ).
Посмотреть ответ
3. 5. Определите предикат
палиндром( Список).
Список называется палиндромом, если он читается одинаково, как слева направо, так и справа налево. Например, [м, а, д, а, м].
Посмотреть ответ
3. 6. Определите отношение
сдвиг( Список1, Список2)
таким образом, чтобы Список2 представлял собой Список1, "циклически сдвинутый" влево на один символ. Например,
?- сдвиг( [1, 2, 3, 4, 5], L1),
сдвиг1( LI, L2)
дает
L1 = [2, 3, 4, 5, 1]
L2 = [3, 4, 5, 1, 2]
Посмотреть ответ
3. 7. Определите отношение
перевод( Список1, Список2)
для перевода списка чисел от 0 до 9 в список соответствующих слов. Например,
перевод( [3, 5, 1, 3], [три, пять, один, три] )
Используйте в качестве вспомогательных следующие отношения:
означает( 0, нуль).
означает( 1, один).
означает( 2, два).
4. 1. Напишите вопросы для поиска в базе данных о семьях.
(а) семей без детей;
(b) всех работающих детей;
(с) семей, где жена работает, а муж нет,
(d) всех детей, разница в возрасте родителей которых составляет не менее 15 лет.
Посмотреть ответ
4. 2. Определите отношение
близнецы( Ребенок1, Ребенок2)
для поиска всех близнецов в базе данных о семьях.
Посмотреть ответ
Назад | Содержание | Вперёд
4. 4. Почему не могло возникнуть зацикливание модели исходного автомата на рис. 4.3, когда в его графе переходов не было "спонтанного цикла"?
Посмотреть ответ
4. 5. Зацикливание при вычислении допускается можно предотвратить, например, таким способом: подсчитывать число переходов, сделанных к настоящему моменту. При этом модель должна будет искать пути только некоторой ограниченной длины. Модифицируйте так отношение допускается. Указание: добавьте третий аргумент - максимально допустимое число переходов:
допускается( Состояние, Цепочка, Макс_переходов)
Посмотреть ответ
Назад | Содержание | Вперёд
5. 1. Пусть есть программа:
р( 1).
р( 2) :- !.
р( 3).
Напишите все ответы пролог-системы на следующие вопросы:
(a) ?- р( X).
(b) ?- р( X), p(Y).
(c) ?- р( X), !, p(Y).
Посмотреть ответ
5. 2. Следующие отношения распределяют числа на три класса - положительные, нуль и отрицательные:
класс( Число, положительные) :- Число > 0.
класс( 0, нуль).
класс( Число, отрицательные) :- Число < 0.
Сделайте эту процедуру более эффективной при помощи отсечений.
Посмотреть ответ
5. 3. Определите процедуру
разбить( Числа, Положительные, Отрицательные)
которая разбивает список чисел на два списка: список, содержащий положительные числа (и нуль), и список отрицательных чисел. Например,
разбить( [3, -1, 0, 5, -2], [3, 0, 5], [-1, -2] )
Предложите две версии: одну с отсечением, другую - без.
Посмотреть ответ
Назад | Содержание | Вперёд
6. 1. Пусть f - файл термов. Определите процедуру
найтитерм( Терм)
которая выводит на терминал новый терм из f, сопоставимый с Терм'ом.
Посмотреть ответ
6. 2. Пусть f - файл термов. Напишите процедуру
найтивсетермы( Терм)
которая выводит на экран все термы из f, сопоставимые с Tepм'ом. Обеспечьте при этом, чтобы во время поиска Терм не конкретизировался (это могло бы помешать ему сопоставиться с другими термами дальше по файлу).
Посмотреть ответ
Назад | Содержание | Вперёд
5. 4. Даны два списка Кандидаты и Исключенные, напишите последовательность целей (используя принадлежит и not), которая, при помощи перебора, найдет все элементы списка Кандидаты, не входящие в список Исключенные.
Посмотреть ответ
5.5. Определите отношение, выполняющее вычитание множеств:
line(); решение( [ ]).
решение( [X/Y | Остальные] ) :-
решение( Остальные),
принадлежит( Y, [1, 2, 3, 4, 5, 6, 7, 8] ),
not бьет( X/Y, Остальные).
бьет( X/Y, Остальные) :-
принадлежит( X1/Y1, Остальные),
( Y1 = Y;
Y1 is Y + X1 - X;
Y1 is Y - X1 + X ).
принадлежит( А, [А | L] ).
принадлежит( А, [В | L] ) :-
принадлежит( А, L).
% Шаблон решения
шаблон( [1/Y1, 2/Y2, 3/Y3, 4/Y4, 5/Y5, 6/Y6, 7/Y7, 8/Y8]).
line(); Рис. 5. 3. Еще одна программа для решения задачи о восьми ферзях.
разность( Множ1, Множ2, Разность)
6. 4. Определите отношение
начинается( Атом, Символ)
для проверки, начинается ли Атом с символа Символ.
Посмотреть ответ
6. 5. Определите процедуру plural, которая преобразует английские существительные из единственного числа во множественное, добавляя к слову окончание s. Например:
?- plural( table, X).
Х = tables
Посмотреть ответ
6. 6. Напишите процедуру
поиск( Ключслово, Предложение)
которая при каждом вызове находит в текущем входном файле предложение, содержащее заданное ключевое слово Ключслово. Предложение в своей исходной форме должно быть представлено в виде последовательности символов или в виде атома (процедуру читпредложение из данного раздела можно соответственно модифицировать).
Назад | Содержание | Вперёд
7. 1. Напишите процедуру упростить для упрощения алгебраических сумм, в которых участвуют числа и символы (строчные буквы). Пусть эта процедура переупорядочивает слагаемые так, чтобы символы предшествовали числам. Вот примеры ее использования:
?- упростить( 1 + 1 + а, Е).
Е = а + 2
?- упростить( l + a + 4 + 2 + b + с, E).
Е = а + b + с + 7
?- упростить( 3 + х + х, Е).
Е = 2*х + 3
7. 2. Определите процедуру
добавить( Элемент, Список)
для добавления нового элемента в список. Предполагается, что все элементы, хранящиеся в списке, - атомы. Список состоит из всех хранящихся в нем элементов, а за ними следует хвост, который не конкретизирован и служит для принятия новых элементов. Пусть, например, в списке уже хранятся а, b и с, тогда
Список = [а, b, с | Хвост]
где Хвост - переменная. Цель
добавить( d, Список)
вызовет конкретизацию
Xвoст = [d | НовыйХвост] и
Список = [а, b, с, d | НовыйХвост]
Таким способом структура может наращиваться, включая в себя новые элементы. Определите также соответствующее отношение принадлежности.
Посмотреть ответ
Назад | Содержание | Вперёд
7. 3. Определите предикат конкрет(Терм) так, чтобы он принимал значение истина, когда в Tepм'e нет ни одной неконкретизированной переменной.
7. 4. Процедура подставить из данного раздела производит, при наличии разных вариантов, лишь самую "внешнюю" подстановку.
Модифицируйте эту процедуру так, чтобы она находила все возможные варианты при помощи автоматического перебора. Например:
?- подставить( a+b, f( A+B), новый, НовыйТерм).
А = а
В = b
НовыйТерм = f( новый);
А = а+b
В = а+b
НовыйТерм = f( новый + новый)
Наша исходная версия нашла бы только первый из этих двух ответов.
7. 5. Определите отношение
включает( Tepмl, Терм2)
которое выполняется, если Терм1 является более общим, чем Терм2. Например:
?- включает( X, с).
yes
?- включает( g( X), g( t( Y))).
yes
?- включает f( X,X), f( a,b)).
no
Назад | Содержание | Вперёд
7. 6. (а) Напишите вопрос к пролог-системе, который удаляет из базы данных всю таблицу произв.
(b) Измените этот вопрос так, чтобы он удалил из таблицы только те строки, в которых произведение равно 0.
7. 7. Определите отношение
копия( Терм, Копия)
которое порождает такую копию Терм'а Копия, в которой все переменные переименованы. Это легко сделать, используя assert и retract.
Назад | Содержание | Вперёд
7. 8. Используя bagof, определите отношение
множподмножеств( Мн, Подмн)
для вычисления множества всех подмножеств данного множества (все множества представлены списками).
7. 9. Используя bagof, определите отношение
копия( Терм, Копия)
чтобы Копия представляла собой Терм, в котором все переменные переименованы.
8. 1. Все показанные ниже процедуры подсп1, подсп2 и подсп3 реализуют отношение взятия подсписка. Отношение подсп1 имеет в значительной мере процедурное определение, тогда как подсп2 и подсп3 написаны в декларативном стиле. Изучите поведение этих процедур на примерах нескольких списков, обращая внимание на эффективность работы. Две из них ведут себя одинаково и имеют одинаковую эффективность. Какие? Почему оставшаяся процедура менее эффективна?
подсп1( Спис, Подспис) :-
начало( Спис, Подспис).
подсп1( [ _ | Хвост], Подспис) :-
% Подспис - подсписок хвоста
подсп1( Хвост, Подспис).
начало( _, [ ]).
начало( [X | Спис1], [X | Спис2] ) :-
начало( Спис1, Спис2).
подсп2( Спис, Подспис) :-
конк( Спис1, Спис2, Спис),
конк( Спис3, Подспис, Cпис1).
подсп3( Спис, Подспис) :-
конк( Спис1, Спис2, Спис),
конк( Подспис, _, Спис2).
8. 2. Определите отношение
добавить_в_конец( Список, Элемент, НовыйСписок)
добавляющее Элемент в конец списка Список; результат - НовыйСписок. Оба списка представляйте разностными парами.
Посмотреть ответ
8. 3. Определите отношение
обратить( Список, ОбращенныйСписок)
где оба списка представлены разностными парами.
Посмотреть ответ
8. 4. Перепищите процедуру собрать из разд. 8.5.2, используя разностное представление списков, чтобы конкатенация выполнялась эффективнее.
9. 1. Определите отношение
список( Объект)
для распознавания случаев, когда Объект является стандартным прологовским списком.
Посмотреть ответ
9. 2. Определите отношение принадлежности к списку, используя систему обозначений, введенную в этой разделе: "затем - ничего_не_делать".
Посмотреть ответ
9. 3. Определите отношение
преобр( СтандСпис, Спис)
для преобразования списков из стандартного представления в систему "затем-ничего_не_делать". Например:
преобр( [а, b], а затем b затем ничего_не_делать)
Посмотреть ответ
9. 4. Обобщите отношение преобр на случай произвольного альтернативного представления списков. Конкретное представление задается символом, обозначающим пустой список, и функтором для соединения головы с хвостом. В отношении преобр придется добавить два новых аргумента:
преобр( СтандСпис, Спис, Функтор, ПустСпис)
Примеры применения этого отношения:
?- пpeoбp( [а, b], L, затем, ничего_не_делать).
L = а затем b затем ничего_не_делать
?- преобр( [а, b, с], L, +, 0).
L = а+(b+(с+0) )
Посмотреть ответ
9. 5. Напишите процедуру слияния двух упорядоченных списков в один третий список. Например:
?- слить( [2, 5, 6, 6, 8], [1, 3, 5, 9], L).
L = [1, 2, 3, 5, 5, 6, 6, 8, 9]
9. 6. Программы сортировки, показанные на рис. 9.2 и 9.3, отличаются друг от друга способом представления списков. Первая из них использует обычное представление, в то время как вторая - разностное представление. Преобразование из одного представления в другое очевидно и может быть автоматизировано. Введите в программу рис. 9.2 необходимые изменения, чтобы преобразовать ее в программу рис. 9.3.
9. 7. Наша программа быстрсорт в случае, когда исходный список уже упорядочен или почти упорядочен, работает очень неэффективно. Проанализируйте причины этого явления.
9. 8. Существует еще одна хорошая идея относительно механизма сортировки списков, позволяющая избавиться от недостатков программы быстрсорт, а именно: разбить список на два меньших списка, отсортировать их, а затем слить вместе. Итак, для того, чтобы отсортировать список L, необходимо разбить L на два списка L1 и L2 примерно одинаковой длины; произвести сортировку списков L1 и L2,получив списки S1 и S2; слить списки S1 и S2, завершив на этом сортировку списка L. Реализуйте этот принцип сортировки и сравните его эффективность с эффективностью программы быстрсорт.
Посмотреть ответ
Назад | Содержание | Вперёд
9. 9. Определите предикаты
двдерево( Объект)
справочник( Объект)
распознающие, является ли Объект двоичным деревом или двоичным справочником соответственно. Используйте обозначения, введенные в данном разделе.
Посмотреть ответ
9. 10. Определите процедуру
глубина( ДвДерево, Глубина)
вычисляющую глубину двоичного дерева в предположении, что глубина пустого дерева равна 0, а глубина одноэлементного дерева равна 1.
Посмотреть ответ
9. 11. Определите отношение
линеаризация( Дерево, Список)
соответствующее "выстраиванию" всех вершин дерева в список.
Посмотреть ответ
9. 12. Определите отношение
максэлемент( Д, Элемент)
таким образом, чтобы переменная Элемент приняла значение наибольшего из элементов, хранящихся в дереве Д.
Посмотреть ответ
9. 13. Внесите изменения в процедуру
внутри( Элемент, ДвСправочник)
добавив в нее третий аргумент Путь таким образом, чтобы можно было бы получить путь между корнем справочника и указанным элементом.
Посмотреть ответ
Назад | Содержание | Вперёд
Усовершенствование процедуры ответпольз
Один из недостатков нашей процедуры ответпольз, который хорошо виден из приведенного выше диалога, - это появление на выходе системы имен, генерируемых пролог-системой, что выглядит довольно неуклюже. Символы, подобные _17, следовало бы заменить на более осмысленные слова.
Другой, более серьезный дефект этой версии процедуры ответпольз состоит в следующем. Если мы еще раз обратимся к ответпольз, задав ту же самую цель, то пользователю придется повторно вводить все варианты решений. Поэтому, если наша экспертная система придет в процессе рассуждений к рассмотрению той же самой цели второй раз, то, вместо того, чтобы использовать информацию, уже полученную от пользователя, она проведет с пользователем в точности тот же самый скучный диалог.
Давайте исправим эти два дефекта. Во-первых, улучшение внешнего вида запросов системы будет основано на введении стандартного формата для каждой "запрашиваемой" цели. Для этого в отношение можно_спросить мы добавим второй аргумент, который и будет задавать этот формат, как видно из следующего примера:
можно_спросить(Х ест Y, 'Животное' ест 'Что-то').
При передаче запроса пользователю каждая переменная вопроса должна быть заменена на ключевое слово, взятое из формата, например:
?- ответпольз( X ест Y, [ ], Ответ).
Это правда: Животное ест Что-то?
да.
Животное = питер.
Что-то = мясо.
Ответ = правда
X = питер
Y = мясо
В улучшенной версии процедуры ответпольз, показанной на рис. 14.11, такое форматирование запросов выполняется процедурой
формат( Цель, ВнешФормат, Вопрос, Перем0, Перем )
Здесь Цель - утверждение, которое нужно форматировать. ВнешФормат определяет внешний формат этого утверждения, задаваемый отношением
можно_спросить( Цель, ВнешФормат)
Вопрос - это Цель, отформатированная в соответствии с ВнешФормат. Перем - список переменных, входящих в Цель, вместе с соответствующими ключевыми словами (как указано в ВнешФормат), причем список Перем получается из списка Перем0 добавлением новых переменных. Например:
?- формат( X передает документы Y,
'Кто' передает 'Что' 'Кому',
Вопрос, [ ], Перем).
Вопрос = 'Кто' передает документы 'Кому',
Перем = [ Х/'Кто', Y/'Кому'].
Второе усовершенствование, состоящее в устранении повторных вопросов к пользователю, будет более трудным. Во-первых, все ответы пользователя следует запоминать, с тем чтобы их можно было отыскать в памяти в более поздний момент времени. Для этого достаточно сделать ответы пользователя элементами некоторого отношения и применить assert, например
assert( сказано( мери передает документы друзьям, правда) ).
В ситуации, когда имеется несколько решений, предложенных пользователем для одной и той же цели, в память относительно нее будет записано несколько фактов. Здесь возникает одно осложнение. Допустим, что в нескольких местах программы встречаются различные варианты некоторой цели (отличающиеся именованием переменных). Например:
( X имеет Y) и % Первый вариант - Цель1
. . .
( X1 имеет Y1) и % Второй вариант - Цель2
. . .
Допустим также, что пользователя просят (через механизм возвратов) предложить несколько решений для Цель1. Затем процесс рассуждений продвигается вплоть до Цель2. Так как у нас уже есть несколько решений для Цель1, мы захотим, чтобы система автоматически применила их и к Цель2 (поскольку очевидно, что они удовлетворяют Цель2). Теперь предположим, что система пытается применить эти решения к Цель2, но ни одно из них не удовлетворяет некоторой другой цели, расположенной ниже. Система делает возврат к Цель2 и просит пользователя предложить новые решения. Если пользователь введет еще несколько решений, то их также придется запомнить. И если система в дальнейшем сделает возврат к Цель1, то эти новые решения надо будет применить к Цель1.
Для того, чтобы правильным образом использовать информацию, вводимую пользователем по запросам из разных точек программы, мы будем снабжать каждую такую информацию специальным индексом. Таким образом, факты, запоминаемые системой, будут иметь вид
сказано( Цель, Истинность, Индекс)
где Индекс - это значение счетчика, ответов пользователя. Процедура
ответпольз( Цель, Трасса, Ответ)
теперь должна будет отслеживать число решений, уже порожденных механизмом возвратов к моменту обращения к этой процедуре. Это можно сделать при помощи другого варианта процедуры ответпольз с четырьмя аргументами:
ответпольз( Цель, Трасса, Ответ, N)
где N - некоторое целое число. Такое обращение к ответпольз должно порождать решения для Цель с индексами, начиная с N и далее. Обращение
ответпольз( Цель, Трасса, Ответ)
соответствует получению всех решений, индексируемых, начиная с 1, поэтому мы имеем следующее соотношение:
ответпольз( Цель, Трасса, Ответ) :-
ответпольз( Цель, Трасса, Ответ, 1).
Принцип работы процедуры
ответпольз( Цель, Трасса, Ответ, N)
таков: сначала получить решения для Цель, отыскивая в памяти все уже известные решения с индексами, начиная с N и далее. Когда все старые решения исчерпаются, начать задавать вопросы пользователю относительно утверждения Цель, записывая полученные таким образом новые решения в память при помощи assert и индексируя их должным образом при помощи целых чисел. Когда пользователь сообщит, что больше нет решений, записать в память факт
конец_ответов( Цель)
Если пользователь с самого начала скажет, что решений нет вообще, то записать факт
сказано( Цель, ложь, Индекс)
Находя в памяти те или иные решения, процедура ответпольз должна правильно интерпретировать подобную информацию.
Однако существует еще одна трудность. Пользователь может, оставляя некоторые переменные неконкретизированными, указывать общие решения. Если найдено положительное решение, более общее, чем Цель, или столь же общее, как Цель, то нет смысла продолжать задавать вопросы об утверждении Цель, поскольку мы уже имеем более общее решение. Аналогичным образом следует поступить, если обнаружен факт
сказано( Цель, ложь, _ )
Программа ответпольз, показанная на рис. 14.11, учитывает все вышеприведенные соображения. В нее введен новый аргумент Копия (копия утверждения Цель), который используется в нескольких случаях сопоставлений вместо Цель, с тем чтобы оставить в неприкосновенности переменные утверждения Цель. Эта программа использует также два вспомогательных отношения.
Одно из них
конкретный( Терм)
истинно, если Терм не содержит переменных. Другое
конкретизация( Терм, Терм1)
означает, что Терм1 есть некоторая конкретизация (частный случай) терма Терм, т. е. Терм - это утверждение не менее общее, чем Терм1. Например:
конкретизация( X передает информацию Y,
мэри передает информацию Z)
Обе процедуры основаны на еще одной процедуре:
нумпер( Терм, N, М)
Эта процедура "нумерует" переменные, содержащиеся в Терм, заменяя каждую из них на некоторый специальный новый терм таким образом, чтобы эти "нумерующие" термы соответствовали числам от N до М-1, Например, пусть эти термы имеют вид
пер/0, пер/1, пер/2, ...
тогда в результате обращения к системе
?- Терм - f( X, t( a,Y, X) ), нумпер( Терм, 5, М).
мы получим
Терм = f( пер/5, t( а, пер/6, пер/5) )
М = 7
Отношение, подобное нумпер, часто входит в состав пролог-системы в качестве встроенной процедуры. Если это не так, то его можно реализовать программно следующим способом:
нумпер( Терм, N, Nплюс1) :-
var( Терм), !, % Переменная ?
Терм = пер/N,
Nплюс1 is N + 1.
line(); % Процедура
%
% ответпольз( Цель, Трасса, Ответ)
%
% порождает, используя механизм возвратов, все решения
% для целевого утверждения Цель, которые указал пользователь.
% Трасса - это цепочка целей-предков и правил,
% используемая для объяснения типа "почему".
ответпольз( Цель, Трасса, Ответ) :-
можно_спросить( Цель, _ ), % Можно спросить ?
копия( Цель, Копия), % Переименование переменных
ответпольз( Цель, Копия, Трасса, Ответ, 1).
% Не спрашивать второй раз относительно конкретизированной цели
ответпольз( Цель, _, _, _, N) :-
N > 1, % Повторный вопрос?
конкретный( Цель), !, % Больше не спрашивать
fail.
% Известен ли ответ для всех конкретизации утверждения Цель?
ответпольз( Цель, Копия, _, Ответ, _ ) :-
сказано( Копия, Ответ, _ ),
конкретизация( Копия, Цель), !. % Ответ известен
% Найти все известные решения для Цель с индексами, начиная с N
ответпольз( Цель, _, _, правда, N) :-
сказано( Цель, правда, М),
М >= N.
% Все уже сказано об утверждении Цель?
ответпольз( Цель, Копия, _, Ответ, _) :-
конец_ответов( Копия),
конкретизация( Копия, Цель), !, % Уже все сказано
fail.
% Попросить пользователя дать (еще) решения
ответпольз( Цель, _, Трасса, Ответ, N) :-
спросить_польз( Цель, Трасса, Ответ, N).
спросить_польз( Цель, Трасса, Ответ, N) :-
можно спросить( Цель, ВнешФормат),
формат( Цель, ВнешФормат, Вопрос, [ ], Перем),
% Получить формат вопроса
спросить( Цель, Вопрос, Перем, Трасса, Ответ, N).
спросить( Цель, Вопрос, Перем, Трасса, Ответ, N) :-
nl,
( Перем = [ ], !, % Сформулировать вопрос
write( ' Это правда: ');
write( 'Есть (еще) решения для :' )),
write( Вопрос), write( '?'),
принять( Ответ1), !, % Ответ1 - да/нет/почему
обработать( Ответ1, Цель, Вопрос, Перем,
Трасса, Ответ, N).
обработать( почему, Цель, Вопрос, Перем,
Трасса, Ответ, N):-
выд_трассу( Трасса),
спросить( Цель, Вопрос, Перем, Трасса, Ответ, N).
обработать( да, Цель,_, Перем, Трасса, правда, N) :-
след_индекс( Инд),
% Получить новый индекс для "сказано"
Инд1 is Инд + 1,
( запрос_перем( Перем),
assertz( сказано( Цель, правда, Инд) );
% Запись решения
копия( Цель, Копия), % Копирование цели
ответпольз( Цель, Копия, Трасса, Ответ, Инд1) ).
% Есть еще решения?
обработать( нет, Цель, _, _, _, ложь, N) :-
копия( Цель, Копия),
сказано( Копия, правда, _), !,
% 'нет' означает, больше нет решений
assertz( конец_ответов( Цель) ),
% Отметить конец ответов
fail;
след_индекс( Инд),
% Следующий свободный индекс для "сказано"
assertz( сказано( Цель, ложь, Инд) ).
% 'нет' означает нет ни одного решения
формат( Пер, Имя, Имя, Перем, [Пер/Имя | Перем]) :-
var( Пер), !.
формат( Атом, Имя, Атом, Перем, Перем) :-
atomic( Атом), !,
atomic( Имя).
формат( Цель, Форм, Вопрос, Перем0, Перем) :-
Цель =.. [Функтор | Apг1],
Форм =.. [Функтор | Форм1],
формвсе( Apг1, Форм1, Арг2, Перем0, Перем),
Вопрос =.. [Функтор | Арг2].
формвсе( [ ], [ ], [ ], Перем, Перем).
формвсе( [Х | СпХ], [Ф | СпФ], [В | СпВ], Перем0, Перем) :-
формвсе( СпХ, СпФ, СпВ, Перем0, Перем1),
формат( X, Ф, В, Перем1, Перем).
запрос_перем( [ ]).
запрос_перем( [Переменная/Имя | Переменные]) :-
nl, write( Имя), write( '='),
read( Переменная),
запрос_перем( Переменные).
выд_трассу( [ ]) :-
nl, write( ' Это был ваш вопрос'), nl.
выд_трассу( [Цель по Прав | Трасса] ) :-
nl, write( 'Чтобы проверить по' ),
write( Прав), write( ', что'),
write( Цель),
выд_трассу( Трасса).
конкретный( Терм) :-
нумпер( Терм, 0, 0). % Нет переменных в Терм'е
% конкретизация( Т1, Т2) означает, что Т2 - конкретизация Т1,
% т.е. терм Т1 - более общий, чем Т2, или той же степени
% общности, что и Т2
конкретизация( Терм, Терм1) :-
% Терм1 - частный случай Терм 'а
копия( Терм1, Терм2),
% Копия Терм1 с новыми переменными
нумпер( Терм2, 0, _), !,
Терм = Терм2. % Успех, если Терм1 - частный случай Терм2
копия( Терм, НовТерм) :-
% Копия Терм' а с новыми переменными
asserta( copy( Терм) ),
retract( сору( НовТерм) ), !.
посл_индекс( 0). % Начальный индекс для "сказано"
след_индекс( Инд) :- % Следующий индекс для "сказано"
retract( посл_индекс( ПослИнд) ), !,
Инд is ПослИнд + 1,
assert( посл_индекс( Инд) ).
line(); Рис. 14. 11. Оболочка экспертной системы: Вопросы к пользователю
и ответы на вопросы "почему".
нумпер( Терм, N, М) :-
Терм =.. [Функтор | Аргументы], % Структура или атом
нумарг( Аргументы, N, M).
% Пронумеровать переменные в аргументах
нумарг( [ ], N, N) :- !.
нумарг( [X | Спис], N, M) :-
нумпер( X, N, N1),
нумарг( Спис, N1, М).
УСОВЕРШЕНСТВОВАННЫЕ МЕТОДЫ ПРЕДСТАВЛЕНИЯ МНОЖЕСТВ ДЕРЕВЬЯМИ
В данной главе мы рассмотрим усовершенствованные методы представления множеств при помощи деревьев. Основная идея состоит в том, чтобы поддерживать сбалансированности или приближенную сбалансированность дерева, с тем чтобы избежать вырождения его в список. Механизмы балансировки деревьев гарантируют, даже в худшем случае, относительно быстрый доступ к элементам данных, хранящихся в дереве, при логарифмическом порядке времени доступа. В этой главе изложено два таких механизма: двоично-троичные (кратко, 2-3) деревья и AVL-деревья. (Для изучения остальных глав понимание данной главы не обязательно.)
double_line();Варианты программы, полученые путем переупорядочивания предложений и целей
Уже в примерах программ гл. 1 существовала скрытая опасность зацикливания. Определение отношения предок в этой главе было таким:
предок( X, Z) :-
родитель( X, Z).
предок( X, Z) :-
родитель( X, Y),
предок( Y, Z).
Проанализируем некоторые варианты этой программы. Ясно, что все варианты будут иметь одинаковую декларативную семантику, но разные процедурные семантики.
В соответствии с декларативной семантикой Пролога мы можем, не меняя декларативного смысла, изменить
(1) порядок предложений в программе и
(2) порядок целей в телах предложений.
Процедура предок состоит из двух предложений, и одно из них содержит в своем теле две цели. Возможны, поэтому, четыре варианта данной программы, все с одинаковым декларативным смыслом. Эти четыре варианта можно получить, если
(1) поменять местами оба предложения и
(2) поменять местами цели в каждом из этих двух последовательностей предложений.
Соответствующие процедуры, названные пред1, пред2, пред3 и пред4, показаны на рис. 2.16.
Есть существенная разница в поведении этих четырех декларативно эквивалентных процедур. Чтобы это продемонстрировать, будем считать, отношение родитель определенным так, как показано на рис. 1.1 гл. 1. и посмотрим, что произойдет, если мы спросим, является ли Том предком Пат, используя все четыре варианта отношения предок:
?- пред1( том, пат).
да
?- пред2( том, пат).
да
?- пред3( том, пат).
да
?- пред4( том, пат).
line();
% Четыре версии программы предок
% Исходная версия
пред1( X, Z) :-
родитель( X, Z).
пред1( X, Z) :-
родитель( X, Y),
пред1( Y, Z).
% Вариант а: изменение порядка предложений в исходной версии
пред2( X, Z) :-
родитель( X, Y),
пред2( Y, Z).
пред2( X, Z) :-
родитель( X, Z).
% Вариант b: изменение порядка целей во втором предложении
% исходной версии
пред3( X, Z) :-
родитель( X, Z).
пред3( X, Z) :-
пред3( X, Y),
родитель( Y, Z).
% Вариант с: изменение порядка предложений и целей в исходной
% версии
пред4( X, Z) :-
пред4( X, Y),
родитель( Y, Z).
пред4( X, Z):-
родитель( X, Z).
line();
Рис. 2. 16. Четыре версии программы предок.
В последнем случае пролог-система не сможет найти ответа. И выведет на терминал сообщение: "Не хватает памяти".
На рис. 1.11 гл. 1 были показаны все шаги вычислений по пред1 (в главе 1 она называлась предок), предпринятые для ответа на этот вопрос. На рис 2.17 показаны соответствующие вычисления по пред2, пред3
и пред4. На рис. 2.17 (с) ясно видно, что работа пред4 - бесперспективна, а рис. 2.17(а) показывает, что пред2 довольно неэффективна по сравнению с пред1: пред2
производит значительно больший перебор и делает больше возвратов по фамильному дереву.
Такое сравнение должно напомнить нам об общем практическом правиле при решении задач: обычно бывает полезным прежде всего попробовать самое простое соображение.
В нашем случае все версии отношения предок основаны на двух соображениях:
более простое - нужно проверить, не удовлетворяют ли два аргумента отношения предок
отношению родитель;
более сложное - найти кого-либо "между" этими двумя людьми (кого-либо, кто связан с ними отношениями родитель и предок).
Из всех четырех вариантов отношения предок, пред1 использует наиболее простое соображение в первую очередь. В противоположность этому пред4 всегда сначала пробует использовать самое сложное. Пред2
и пред3 находятся между этими двумя крайностями. Даже без детального изучения процессов вычислений ясно, что пред1
следует предпочесть просто на основании правила "самое простое пробуй в первую очередь".
Наши четыре варианта процедуры предок
можно далее сравнить, рассмотрев вопрос: "На какие типы вопросов может отвечать тот или иной конкретный вариант и на какие не может?" Оказывается, пред1 и пред2 оба способны найти ответ на любой вид вопроса относительно предков; пред4 никогда не находит ответа, а пред3 иногда может найти, иногда нет. Вот пример вопроса, на который пред4
ответить не может:
?- пред3( лиз, джим).
Такой вопрос тоже вводит систему в бесконечную рекурсию. Следовательно и пред3 нельзя признать верным с точки зрения процедурного смысла.

Рис. 2. 17. Поведение трех вариантов формулировки отношения
предок при ответе на вопрос, является ли Том предком Пат?
ВВОД И ВЫВОД
В этой главе мы рассмотрим некоторые встроенные средства для записи данных в файл и считывания их из файла. Такие средства можно также применять и для форматирования объектов данных программы, чтобы получить желаемую форму их внешнего представления. Одновременно мы рассмотрим и средства синтеза и декомпозиции атомов.
double_line();Ввод программ: consult, reconsult
Передавать программы пролог-системе можно при помощи двух встроенных предикатов: consult и reconsult. Чтобы система считала программу из файла F, нужно поставить цель
?- consult( F).
В результате все предложения программы, содержащейся в F, будут использованы пролог-системой при ответе на дальнейшие вопросы пользователя. Если позже в том же сеансе произойдет "консультация" с другим файлом, предложения этого нового файла будут просто добавлены в конец текущего множества предложений.
Для того, чтобы запустить программу, не обязательно записывать ее в файл, а затем "консультироваться" с ним. Вместо чтения файла система может принимать программу прямо с терминала, который соответствует псевдофайлу user. Добиться этого можно так:
?- consult( user).
После этого система будет ожидать ввода предложений программы с терминала.
В некоторых пролог - системах применяется сокращенная запись для чтения программ из файлов. Файлы, из которых предстоит чтение, просто помещаются в список и этот список используется в качестве цели. Например:
?- [файл1, файл2, файл3].
Это в точности эквивалентно следующим трем целям:
?- соnsult( файл1), соnsult( файл2), соnsult( файл3).
Встроенный предикат reconsult аналогичен consult. Цель
?- reconsult( F).
даст тот же эффект, что и consult( F) с одним исключением. Если в F есть предложения, касающиеся отношений, которые уже были определены ранее, старые определения заменяются на новые из F. Разница между consult и reconsult в том, что consult всегда добавляет новые предложения, в то время как reconsult переопределяет ранее введенные определения. Однако reconsult не произведет никакого эффекта на те отношения, о которых в F ничего не сказано.
Следует еще раз заметить, что детали "консультирования" с файлами зависят от конкретной реализации Пролога. Это замечание касается и большинства остальных встроенных процедур.
Вычисление максимума
Процедуру нахождения наибольшего из двух чисел можно запрограммировать в виде отношения
mах( X, Y, Мах)
где Мах = X, если Х больше или равен Y, и Мах есть Y, если Х меньше Y. Это соответствует двум таким предложениям:
mах( X, Y, X) :- Х >= Y.
max( X, Y, Y) :- Х < Y.
Эти правила являются взаимно исключающими. Если выполняется первое, второе обязательно потерпит неудачу. Если неудачу терпит первое, второе обязательно должно выполниться. Поэтому возможна более экономная формулировка, использующая понятие "иначе":
если Х >= Y, то Мах = X,
иначе Мах = Y.
На Прологе это записывается при помощи отсечения:
mах( X, Y, X) :- Х >= Y, !.
mах( X, Y, Y).
Выполнимость совета
Мы говорим, что элементарный совет выполним в данной позиции, если игрок может форсированным образом достигнуть главной цели, указанной в совете, при условии, что:
(1) ни разу не нарушается цель-поддержка;
(2) все ходы игрока удовлетворяют наложенным на них ограничениям;
(3) противнику разрешено делать только те ходы, которые предусмотрены соответствующими ограничениями.
С выполнимостью элементарного совета связано понятие форсированного дерева. Форсированное дерево задает детальную стратегию, которая гарантирует достижение главной цели при выполнении всех ограничений, содержащихся в элементарном совете. Таким образом, форсированное дерево указывает, как именно должен ходить игрок при любых ответах противника. Более точно, форсированное дерево Т для заданной позиции Р и элементарного совета А есть такое поддерево дерева игры, что корень дерева Т - позиция Р; все позиции из Т удовлетворяют цели-поддержке; все терминальные позиции из Т удовлетворяют главной цели (что, однако, неверно ни для одной внутренней вершины); для каждой внутренней позиции игрока в дереве Т указан только один ход, причем он удовлетворяет ограничениям на ходы игрока; из каждой внутренней позиции противника исходят все ходы противника (удовлетворяющие соответствующим ограничениям).
Каждый элементарный совет можно рассматривать как описание некоторой небольшой специальной игры, имеющей следующие правила. Участникам игры разрешено ходить в пределах ограничений, наложенных на их ходы; позиция, не удовлетворяющая цели-поддержке, считается выигрышем "противника". Нетерминальная позиция считается выигранной с точки зрения игрока, если данный элементарный совет в ней выполним. Таким образом, для того, чтобы выиграть в зтой игре, игрок должен следовать стратегии, задаваемой форсированным деревом.
Вывод списков
Кроме стандартного прологовского формата для списков существуют несколько других естественных форм их внешнего представления, которые в некоторых ситуациях являются более предпочтительными. Следующая процедура
вывспис( L)
выводит список L так, что каждый его элемент занимает отдельную строку:
вывспис( [ ]).
вывспис( [X | L) :-
write( X), n1.
вывспис( L).
Если у нас есть список списков, то одной из естественных форм его выводе является такая, при которой все элементы каждого списка записываются на отдельной строке. Для этого мы определим процедуру вывспис2. Вот пример ее использования:
?- вывспис2( [ [а, b, с], [d, e, f], [g, h, i] ] ).
а b с
d e f
g h i
Процедура, выполняющая эту работу, такова:
вывспис2( [ ]).
вывспис2( [L | LL] ) :-
строка( L), n1,
вывспис1( LL).
строка( [ ]).
строка( [X | L] ) :-
write( X), tab( 1),
строка( L).
Список целых чисел иногда удобно представить в виде диаграммы.
Следующая процедура диагр
выводит список в такой форме (предполагается, что числа списка заключены между 0 и 80). Пример ее использования:
?- диагр( [3, 4, 6, 5] ).
***
****
******
*****
Процедуру диагр
можно определить так:
диагр( [N | L]) :-
звездочки( N), n1,
диагр( L).
звеэдочки( N) :-
N > 0,
write( *),
Nl is N - 1,
звездочки( Nl).
звездочки( N) :-
N =< 80.
Задача классификации объектов
Предположим, что у нас есть база данных, содержащая результаты теннисных партий, сыгранных членами некоторого клуба. Подбор пар противников для каждой партия не подчинялся какой-либо системе, просто каждый игрок встречался с несколькими противниками. Результаты представлены в программе в виде фактов, таких как
победил( том, джон).
победил( энн, том).
победил( пат, джим).
Мы хотим определить
отношение класс( Игрок, Категория)
которое распределяет игроков по категориям. У нас будет три категории:
победитель - любой игрок, победивший во всех сыгранных им играх
боец - любой игрок, в некоторых играх победивший, а в некоторых проигравший
спортсмен - любой игрок, проигравший во всех сыгранных им партиях
Например, если в нашем распоряжении есть лишь приведенные выше результаты, то ясно, что Энн и Пат - победители. Том - боец и Джим - спортсмен.
Легко сформулировать правило для бойца:
Х - боец, если существует некоторый Y, такой, что Х победил
Y, и
существует некоторый Z, такой, что Z победил
X.
Теперь правило для победителя:
Х - победитель, если
X победил некоторого Y и
Х не был побежден никем.
Эта формулировка содержит отрицание "не", которое нельзя впрямую выразить при помощи тех возможностей Пролога, которыми мы располагаем к настоящему моменту. Поэтому оказывается, что формулировка отношения победитель
должна быть более хитрой. Та же проблема возникает и при формулировке правил для отношения спортсмен. Эту проблему можно обойти, объединив определения отношений победитель
и боец и использовав связку "иначе".
Вот такая формулировка:
Если Х победил кого-либо и Х был кем-то
побежден,
то Х - боец,
иначе, если Х победил кого-либо,
то Х - победитель,
иначе, если Х был кем-то побежден,
то Х - спортсмен.
Такую формулировку можно сразу перевести на Пролог. Взаимные исключения трех альтернативных категорий выражаются при помощи отсечений:
класс( X, боец) :-
победил( X, _ ),
победил( _, X), !.
класс( X, победитель) :-
победил( X, _ ), !.
класс( X, спортсмен) :-
победил( _, X).
Заметьте, что использование отсечения в предложении для категории победитель
не обязательно, что связано с особенностями наших трех классов.
Задача о ханойской башне
Задача о ханойской башне (рис. 13.6) - это еще один классический пример эффективного применения метода разбиения задачи на подзадачи и построения И / ИЛИ-графа. Для простоты мы рассмотрим упрощенную версию этой задачи, когда в ней участвует только три диска:
Имеется три колышка 1, 2 и 3 и три диска а, b и с (а - наименьший из них, а с - наибольший). Первоначально все диски находятся на колышке 1. Задача состоит в том, чтобы переложить все диски на колышек 3. На каждом шагу можно перекладывать только один диск, причем никогда нельзя помещать больший диск на меньший.
Эту задачу можно рассматривать как задачу достижения следующих трех целей:
(1) Диск а
- на колышек 3.
(2) Диск b
- на колышек 3.
(3) Диск с
- на колышек 3.
Беда в том, что эти цели не независимы. Например, можно сразу переложить диск а на колышек 3, и первая цель будет достигнута. Но тогда две другие цели станут недостижимыми (если только мы не отменим первое наше действие). К счастью, существует такой удобный порядок достижения этих целей, из которого можно легко вывести искомое решение.
Рис. 13. 6. Задача о ханойской башне
Порядок этот можно установить при помощи следующего рассуждения: самая трудная цель - это цель 3 (диск с - на колышек 3), потому что на диск с наложено больше всего ограничений. В подобных ситуациях часто срабатывает хорошая идея: пытаться достичь первой самую трудную цель. Этот принцип основан на следующей логике: поскольку другие цели достигнуть легче (на них меньше ограничений), можно надеяться на то, что их достижение возможно без отмены действий на достижение самой трудной цели.
Применительно к нашей задаче это означает, что необходимо придерживаться следующей стратегии:
Первой достигнуть цель "диск с - на колышек 3",
а затем - все остальные.
Но первая цель не может быть достигнута сразу, так как в начальной ситуации диск с двигать нельзя. Следовательно, сначала мы должны подготовить этот ход, и наша стратегия принимает такой вид
(1) Обеспечить возможность перемещения диска с с 1 на 3.
(2) Переложить с с 1 на 3.
(3) Достигнуть остальные цели (а на 3 и b на 3).
Переложить c с 1 на 3 возможно только в том случае, если диск а и b оба надеты на колышек 2. Таким образом наша исходная задача перемещения а, b и с с 1 на 3 сводится к следующим трем подзадачам:
Для того, чтобы переложить a, b и с с 1 на 3, необходимо
(1) переложить а и b с 1 на 2, и
(2) переложить с с 1 на 3, и
(1) переложить а и b с 2 на 3.
Задача 2 тривиальна (она решается за один шаг). Остальные две подзадачи можно решать независимо от задачи 2, так как диски а и b можно двигать, не обращая внимание на положение диска с. Для решения задач 1 и 3 можно применить тот же самый принцип разбиения (на этот раз диск b будет самым "трудным"). В соответствии с этим принципом задача 1 сводится к трем тривиальным подзадачам:
Для того, чтобы переложить а и b с 1 на 2, необходимо:
(1) переложить а с 1 на 3, и
(2) переложить b с 1 на 2, и
(1) переложить а с 3 на 2.
Задача о восьми ферзях
Эта задача состоит в отыскании такой расстановки восьми ферзей на пустой шахматной доске, в которой ни один из ферзей не находится под боем другого. Решение мы запрограммируем в виде унарного отношения:
решение( Поз)
которое истинно тогда и только тогда, когда Поз изображает позицию, в которой восемь ферзей не бьют друг друга. Будет интересно сравнить различные идеи, лежащие в основе программирования этой задачи. Поэтому мы приведем три программы, основанные на слегка различающихся ее представлениях.
4. 5. 1. Программа 1
Вначале нужно выбрать способ представления позиции на доске. Один из наиболее естественных способов - представить позицию в виде списка из восьми элементов, каждый из которых соответствует одному из ферзей. Каждый такой элемент будет описывать то поле доски, на которой стоит соответствующий ферзь. Далее, каждое поле доски можно описать с помощью пары координат ( Х и Y), где каждая координата - целое число от 1 до 8. В программе мы будем записывать такую пару в виде
Х / Y
где оператор "/" обозначает, конечно, не деление, а служит лишь для объединения координат поля в один элемент списка. На рис. 4.6 показано одно из решений задачи о восьми ферзях и его запись в виде списка.
После того. как мы выбрали такое представление, задача свелась к нахождению списка вида:
[Xl/Yl, X2/Y2, X3/Y3, X4/Y4, X5/Y5, X6/Y6, X7/Y7, X8/Y8]
удовлетворяющего требованию отсутствия нападений. Наша процедура решение должна будет найти подходящую конкретизацию переменных X1, Y1, Х2, Y2, ..., Х8, Y8. Поскольку мы знаем, что все ферзи должны находиться на разных вертикалях во избежание нападений по вертикальным линиям, мы можем сразу же ограничить перебор, чтобы облегчать поиск решения. Можно поэтому сразу зафиксировать Х-координаты так, чтобы список, изображающий решение, удовлетворял следующему, более конкретному шаблону:
[1/Y1, 2/Y2, 3/Y3, 4/Y4, 5/Y5, 6/Y6, 7/Y7, 8/Y8]

Рис. 4. 6. Решение задачи о восьми ферзях. Эта позиция может быть
представлена в виде списка [1/4, 2/2, 3/7, 4/3, 5/6, 6/8, 7/5, 8/1].
Нас интересует решение для доске размером 8х8. Однако, как это часто бывает в программировании, ключ к решению легче найти, рассмотрев более общую постановку задачи. Как это ни парадоксально, но часто оказывается, что решение более общей задачи легче сформулировать, чем решение более частной, исходной задачи; после этого исходная задача решается просто как частный случай общей задачи.
Основная часть работы при таком подходе ложится на нахождение правильного обобщения исходной задачи. В нашем случае хорошей является идея обобщать задачу в отношении количества ферзей (количества вертикалей в списке), разрешив количеству ферзей принимать любое значение, включая нуль. Тогда отношение решение можно сформулировать, рассмотрев два случая:
Случай 1. Список ферзей пуст. Пустой список без сомнения является решением, поскольку нападений в этом случае нет.
Случай 2. Список ферзей не пуст. Тогда он выглядит так:
[ X/Y | Остальные ]
В случае 2 первый ферзь находится на поле Х / Y, а остальные - на полях, указанных в списке Остальные. Если мы хотим, чтобы это было решением, то должны выполняться следующие условия:
(1) Ферзи, перечисленные в списке Остальные, не должны бить друг друга; т. е. список Остальные сам должен быть решением.
(2) Х и Y должны быть целыми числами от 1 до 8.
(3) Ферзь, стоящий на поле X / Y, не должен бить ни одного ферзя из списка Остальные.
Чтобы запрограммировать первое условие, можно воспользоваться самим отношением решение. Второе условие можно сформулировать так: Y должен принадлежать списку целых чисел от 1 до 8.
т. е. [1, 2, 3, 4, 5, 6, 7, 8]. С другой стороны, о координате Х можно не беспокоиться, поскольку список-решение должен соответствовать шаблону, у которого Х-координаты уже определены. Поэтому Х гарантированно получит правильное значение от 1 до 8. Третье условие можно обеспечить с помощью нового отношения небьет. Все это можно записать на Прологе так:
решение( [X/Y | Остальные] ) :-
решение( Остальные),
принадлежит( Y, [1, 2, 3, 4, 5, 6, 7, 8] ),
небьет( X/Y, Остальные).
Осталось определить отношение небьет:
небьет( Ф, Фспис)
И снова его описание можно разбить на два случая:
(1) Если список Фспис пуст, то отношение, конечно, выполнено, потому что некого бить (нет ферзя, на которого можно было бы напасть).
(2) Если Фспис не пуст, то он имеет форму
[Ф1 | Фспис1]
и должны выполняться два условия:
(а) ферзь на поле Ф не должен бить ферзя на поле Ф1 и
(b) ферзь на поле Ф не должен бить ни одного ферзя из списка Фспис1.
Выразить требование, чтобы ферзь, находящийся на некотором поле, не бил другое поле, довольно просто: эти поля не должны находиться на одной и той же горизонтали, вертикали или диагонали: Наш шаблон решения гарантирует, что все ферзи находятся на разных вертикалях, поэтому остается только обеспечить, чтобы Y-координаты ферзей были различны и ферзи не находились на одной диагонали, т.е. расстояние между полями по направлению Х не должно равняться расстоянию между ними по Y. На рис. 4.7 приведен полный текст программы.
Чтобы облегчить ее использование, необходимо добавить список-шаблон. Это можно сделать в запросе на генерацию решений. Итак:
?- шаблон( S), решение( S).
line(); решение( [ ] ).
решение( [X/Y | Остальные ] ) :-
% Первый ферзь на поле X/Y,
% остальные ферзи на полях из списка Остальные
решение( Остальные),
принадлежит Y, [1, 2, 3, 4, 5, 6, 7, 8] ),
небьет( X/Y | Остальные).
% Первый ферзь не бьет остальных
небьет( _, [ ]). % Некого бить
небьет( X/Y, [X1/Y1 | Остальные] ) :-
Y =\= Y1, % Разные Y-координаты
Y1-Y =\= X1-X % Разные диагонали
Y1-Y =\= X-X1,
небьет( X/Y, Остальные).
принадлежит( X, [X | L] ).
принадлежит( X, [Y | L] ) :-
принадлежит( X, L).
% Шаблон решения
шаблон( [1/Y1, 2/Y2, 3/Y3, 4/Y4, 5/Y5, 6/Y6, 7/Y7, 8/Y8]).
line(); Рис. 4. 7. Программа1 для задачи о восьми ферзях.
Система будет генерировать решения в таком виде:
S = [1/4, 2/2, 3/7, 4/3, 5/6, 6/8, 7/5, 8/1];
S = [1/5, 2/2, 3/4, 4/7, 5/3, 6/8, 7/6, 8/1];
S = [1/3, 2/5, 3/2, 4/8, 5/6, 6/4, 7/7, 8/1].
. . .
Заключительные замечания
Нашу оболочку экспертной системы можно развивать в целом ряде направлений. В данный момент уместно сделать несколько критических замечаний и высказать предложения по усовершенствованию нашей программы.
В нашей программе, являющейся упрощенной реализацией, не уделено достаточного внимания вопросам эффективности. В более эффективной реализации потребовалось бы использовать более сложные структуры данных, ввести индексирование или иерархическую структуризацию множества правил и т.п.
Наша процедура рассмотреть подвержена зацикливанию в тех случаях, когда в правилах базы знаний "циклически" упоминается одна и та же цель. Этот недостаток легко исправить, предусмотрев в рассмотреть соответствующий контроль, т. е. проверку, не является ли текущая цель частным случаем некоторой цели, уже введенной в состав объекта Трасса.
Наше объяснение типа "как" выводит дерево доказательства целиком. В случае больших деревьев, удобнее было бы вывести только верхнюю часть дерева, а затем дать пользователю возможность "гулять" по остальной части дерева по своему желанию. Тогда пользователь смог бы просматривать дерево выборочным образом, используя команды, такие как "Вниз по ветви 1", "Вниз по ветви 2", .... "Вверх ", "Достаточно".
В объяснениях типа "как" и "почему" наша оболочка ссылается на правила, указывая их имена, и не показывает их в явном виде. Необходимо, чтобы во время консультационного сеанса пользователь мог, по желанию, запрашивать те или иные правила и получать их явные изображения.
Известно, что придать диалогу с пользователем естественный характер при помощи умелой постановки вопросов - сложная задача. Наш способ ее решения работает только в определенных пределах и во многих случаях приводит к самым разным проблемам, например:
Это правда: сьюзен летает?
нет.
Это правда: сьюзен летает хорошо?
Замечания о взаимосвязи между Прологом и логикой
Пролог восходит к математической логике, поэтому его синтаксис и семантику можно наиболее точно описать при помощи логики. Так часто и поступают при обучении этому языку. Однако такой подход к ознакомлению с Прологом предполагает знание читателем определенных понятий математической логики. С другой стороны, знание этих понятий явно необязательно для того, чтобы понять и использовать Пролог в качестве инструмента для практического программирования, а цель данной книги - научить именно этому. Для тех же читателей, которые особенно заинтересуются взаимосвязями между Прологом и логикой, мы сейчас перечислим основные из них, а также приведем некоторые подходящие источники.
Синтаксис Пролога - это синтаксис предложений логики предикатов первого порядка, записанных в так называемой форме предложений (форме, при которой кванторы не выписываются явно), а точнее, в виде частного случая таких предложений - в виде формул Хорна (предложений, имеющих самое большее один положительный литерал). Клоксин и Меллиш (1981 г.) приводят пролог-программу, которая преобразует предложения исчисления предикатов первого порядка в форму предложений. Процедурный смысл Пролога основывается на принципе резолюций, применяющемся для автоматического доказательства теорем, который был предложен Робинсоном в его классической статье (1965 г.). В Прологе используется особая стратегия доказательства теоремы методом резолюций, носящая название SLD. Введение в исчисление предикатов первого порядка и доказательство теорем, основанное на методе резолюций, можно найти у Нильсона (1981 г.). Математические вопросы, касающиеся свойств процедурной семантики Пролога в их связи с логикой, проанализированы Ллойдом (1984 г.).
Сопоставление в Прологе соответствует некоторому действию в логике, называемому унификацией. Мы, однако, избегаем слова "унификация", так как по соображениям эффективности внести в большинстве пролог-систем сопоставление реализовано таким образом, что оно не полностью соответствует унификации (см. упражнение 2.10). Тем не менее, с практической точки зрения, такая приближенная унификация вполне допустима.
Замечания относительно поиска в графах, оптимальности к сложности
Сейчас уместно сделать ряд замечаний относительно программ поиска, разработанных к настоящему моменту: во-первых, о поиске в графах, во-вторых, об оптимальности полученных решений и, в-третьих, о сложности поиска.
Приведенные примеры могли создать ложное впечатление, что наши программы поиска в ширину способны работать только в пространствах состояний, являющихся деревьями, а не графами общего вида. На самом деле, тот факт, что в одной из версий множество путей-кандидатов представлялось деревом, совсем не означает, что и само пространство состояний должно было быть деревом. Когда поиск проводится в графе, граф фактически разворачивается в дерево, причем некоторые пути, возможно, дублируются в разных частях этого дерева (см. рис. 11.14).
Наши программы поиска в ширину порождают решающие пути один за другим в порядке увеличения их
Рис. 11. 14. (а) Пространство состояний; а - стартовая вершина.
(b) Дерево всех возможных ациклических путей, ведущих из а,
порожденное программой поиска в ширину.
длин - самые короткие решения идут первыми. Это является важным обстоятельством, если нам необходима оптимальность (в отношении длины решения). Стратегия поиска в ширину гарантирует получение кратчайшего решения первым. Разумеется, это неверно для поиска в глубину.
Наши программы, однако, не учитывают стоимости, приписанные дугам в пространстве состояний. Если критерием оптимальности является минимум стоимости решающего пути (а не его длина), то в этом случае поиска в ширину недостаточно. Поиск с предпочтением из гл. 12 будет направлен на оптимизацию стоимости.
Еще одна типичная проблема, связанная с задачей поиска, - это проблема комбинаторной сложности. Для нетривиальных предметных областей число альтернатив столь велико, что проблема сложности часто принимает критический характер. Легко понять, почему это происходит: если каждая вершина имеет b преемников, то число путей длины l, ведущих из стартовой вершины, равно bl ( в предположении, что циклов нет). Таким образом, вместе с увеличением длин путей наблюдается экспоненциальный рост объема множества путей-кандидатов, что приводит к ситуации, называемой комбинаторным взрывом. Стратегии поиска в глубину и ширину недостаточно "умны" для борьбы с такой степенью комбинаторной сложности: отсутствие селективности приводит к тому, что все пути рассматриваются как одинаково перспективные.
По-видимому, более изощренные процедуры поиска должны использовать какую-либо информацию, отражающую специфику данной задачи, с тем чтобы на каждой стадии поиска принимать решения о наиболее перспективных путях поиска. В результате процесс будет продвигаться к целевой вершине, обходя бесполезные пути. Информация, относящаяся к конкретной решаемой задаче и используемая для управления поиском, называется эвристикой. Про алгоритмы, использующие эвристики, говорят, что они руководствуются эвристиками: они выполняют эвристический поиск. Один из таких методов изложен в следующей главе.
Замечания в некоторых альтернативных способах представления списков
В главе 3 была введена специальная система обозначений для списков (специальная прологовская нотация), которую мы и использовали в последующем изложении. Разумеется, это был всего лишь один из способов представления списков на Прологе. Список - это, в самом общем смысле, структура, которая либо пуста, либо состоит из головы и хвоста, причем хвост должен быть сам списком.
Поэтому для представления этой структуры нам необходимо иметь всего лишь два языковых средства: специальный символ, обозначающий пустой список, и функтор для соединения головы с хвостом. Мы могли бы, например, выбрать
ничего_не_делать
в качестве символа, обозначающего пустой список, и атом
затем
в качестве инфиксного оператора для построения списка по заданным голове и хвосту. Этот оператор мы можем объявить в программе, например, так:
:- ор( 500, xfy, затем).
Список
[ войти, сесть, поужинать]
можно было бы тогда записать как
войти затем сесть затем поужинать
затем ничего_не_делать
Важно заметить, что на соответствующем уровне абстракции специальная прологовская нотация и всевозможные альтернативные способы обозначения списков сводятся, фактически, к одному и тому же представлению. В связи с этим типовые операции над списками, такие как
принадлежит ( X, L)
конк( L1, L2, L3)
удалить( X, L1, L2)
запрограммированные нами в специальной прологовской нотации, легко поддаются перепрограммированию в различные системы обозначений, выбранные пользователем. Например, отношение конк транслируется на язык "затем - ничего_не_делать" следующим образом. Определение, которое мы использовали до сих пор, имеет вид
конк( [ ], L, L).
конк( [X | L1], L2, [X | L3] ) :-
конк( L1, L2, L3).
В новой системе обозначений оно превращается в
конк( ничего_не_делать, L, L).
конк( Х затем L1, L2, Х затем L3) :-
конк(L1, L2, L3).
Этот пример показывает, как легко наши определения отношений над списками обобщаются на весь класс структур этого типа. Решение о том, какой именно способ записи списков будет использоваться в той или иной программе, следует принимать в соответствии с тем смыслом, который мы придаем списку в каждом конкретном случае. Если, например, список - это просто множество элементов, то наиболее удобна обычная прологовская нотация, поскольку в ней непосредственно выражается то, что программист имел в виду. С другой стороны, некоторые типы выражений также можно трактовать как своего рода списки. Например, для конъюнктов в исчислении высказываний подошло бы следующее спископодобное представление: истина соответствует пустому списку, & - оператор для соединения головы с хвостом, определяемый, например, как
:- ор( 300, xfy, &) Конъюнкция членов а, b, и с выглядела бы тогда как
а & b & с & истина
Все приведенные примеры базируются, по существу, на одной и той же структуре, представляющей список. Однако в гл. 8 мы рассмотрели существенно другой способ, влияющий на эффективность вычислений. Уловка состояла в том, что список представлялся в виде пары списков, являясь их "разностью". Было показано, что такое представление приводит к очень эффективной реализации отношения конкатенации.
Материал настоящего раздела проливает свет и на то различие, которое существует между применением операторов в математике и применением их в Прологе. В математике с каждым оператором всегда связано некоторое действие, в то время как в Прологе операторы используются просто для представления структур.
Знания о типовых ситуациях и механизм "советов"
В этом разделе рассматривается метод представления знаний о конкретной игре с использованием семейства Языков Советов. Языки Советов (Advice Languages) дают возможность пользователю декларативным способом описывать, какие идеи следует использовать в тех или иных типовых ситуациях. Идеи формулируются в терминах целей и средств, необходимых для их достижения. Интерпретатор Языка Советов определяет при помощи перебора, какая идея "работает" в данной ситуации.
