Арифметические действия
Арифметические действия
Пролог рассчитан главным образом на обработку символьной информации, при которой потребность в арифметических вычислениях относительно мала. Поэтому и средства для таких вычислений довольно просты. Для осуществления основных арифметических действий можно воспользоваться несколькими предопределенными операторами.
+ сложение
- вычитание
* умножение
/ деление
mod модуль, остаток от целочисленного деления
Заметьте, что это как раз тот исключительный случай. когда оператор может и в самом деле произвести некоторую операцию. Но даже и в этом случае требуется дополнительное указание на выполнение действия. Пролог-система знает, как выполнять вычисления, предписываемые такими операторами, но этого недостаточно для их непосредственного использования. Следующий вопрос - наивная попытка произвести арифметическое действие:
?- Х = 1 + 2.
Пролог-система "спокойно" ответит
Х = 1 + 2
а не X = 3, как, возможно, ожидалось. Причина этого проста: выражение 1 + 2 обозначает лишь прологовский терм, в котором + является функтором, а 1 и 2 - его аргументами. В вышеприведенной цели нет ничего, что могло бы заставить систему выполнить операцию сложения. Для этого в Прологе существует специальный оператор is (есть). Этот оператор заставит систему выполнить вычисление. Таким образом, чтобы правильно активизировать арифметическую операцию, надо написать:
?- Х is 1 + 2.
Вот теперь ответ будет
Х = 3
Сложение здесь выполняется специальной процедурой, связанной с оператором +. Мы будем называть такие процедуры встроенными.
В Прологе не существует общепринятой нотации для записи арифметических действий, поэтому в разных реализациях она может слегка различаться. Например, оператор '/' может в одних реализациях обозначать целочисленное деление, а в других - вещественное. В данной книге под '/' мы подразумеваем вещественное деление, для целочисленного же будем использовать оператор div. В соответствии с этим, на вопрос
?- Х is 3/2,
Y is 3 div 2.
ответ должен быть такой:
Х = 1.5
Y = 1
Левым аргументом оператора is является простой объект. Правый аргумент - арифметическое выражение, составленное с помощью арифметических операторов, чисел и переменных. Поскольку оператор is запускает арифметические вычисления, к моменту начала вычисления этой цели все ее переменные должны быть уже конкретизированы какими-либо числами. Приоритеты этих предопределенных арифметических операторов (см. рис. 3.8) выбраны с таким расчетом, чтобы операторы применялись к аргументам в том порядке, который принят в математике. Чтобы изменить обычный порядок вычислений, применяются скобки (тоже, как в математике). Заметьте, что +, -, *, / и div определены, как yfx, что определяет порядок их выполнения слева направо. Например,
Х is 5 - 2 - 1
понимается как
X is (5 - 2) - 1
Арифметические операции используются также и при сравнении числовых величин. Мы можем, например, проверить, что больше - 10000 или результат умножения 277 на 37, с помощью цели
?- 277 * 37 > 10000.
yes
(да)
Заметьте, что точно так же, как и is, оператор '>' вызывает выполнение вычислений.
Предположим, у нас есть программа, в которую входит отношение рожд, связывающее имя человека с годом его рождения. Тогда имена людей, родившихся между 1950 и 1960 годами включительно, можно получить при помощи такого вопроса:
?- рожд( Имя, Год),
Год >= 1950,
Год <= 1960.
Ниже перечислены операторы сравнения:
Х > Y Х больше Y
Х < Y Х меньше Y
Х >= Y Х больше или равен Y
Х =< Y Х меньше или равен Y
Х =:= Y величины Х и Y совпадают (равны)
Х =\= Y величины Х и Y не равны
Обратите внимание на разницу между операторами сравнения '=' и '=:=', например, в таких целях как X = Y и Х =:= Y. Первая цель вызовет сопоставление объектов Х и Y, и, если Х и Y сопоставимы, возможно, приведет к конкретизации каких-либо переменных в этих объектах. Никаких вычислений при этом производиться не будет. С другой стороны, Х =:= Y вызовет арифметическое вычисление и не может привести к конкретизации переменных. Это различие можно проиллюстрировать следующими примерами:
?- 1 + 2 =:= 2 + 1.
yes
>- 1 + 2 = 2 + 1.
no
?- 1 + А = В + 2.
А = 2
В = 1
Давайте рассмотрим использование арифметических операций на двух простых примерах. В первом примере ищется наибольший общий делитель; во втором - определяется количество элементов в некотором списке.
Если заданы два целых числа Х и Y, то их наибольший общий делитель Д можно найти, руководствуясь следующими тремя правилами:
(1) Если Х и Y равны, то Д равен X.
(2) Если Х > Y, то Д равен наибольшему общему делителю Х разности Y - X.
(3) Если Y < X, то формулировка аналогична правилу (2), если Х и Y поменять в нем местами.
На примере легко убедиться, что эти правила действительно позволяют найти наибольший общий делитель. Выбрав, скажем, Х = 20 и Y = 25, мы, руководствуясь приведенными выше правилами, после серии вычитаний получим Д = 5.
Эти правила легко сформулировать в виде прологовской программы, определив трехаргументное отношение, скажем
нод( X , Y, Д)
Тогда наши три правила можно выразить тремя предложениями так:
нод( X, X, X).
нод( X, Y, Д) :-
Х < Y,
Y1 is Y - X,
нод( X, Y1, Д),
нод( X, Y, Д) :-
Y < X,
нод( Y, X, Д).
Разумеется, с таким же успехом можно последнюю цель в третьем предложении заменить двумя:
X1 is Х - Y,
нод( X1, Y, Д)
В нашем следующем примере требуется произвести некоторый подсчет, для чего, как правило, необходимы арифметические действия. Примером такой задачи может служить вычисление длины какого-либо списка; иначе говоря, подсчет числа его элементов. Определим процедуру
длина( Список, N)
которая будет подсчитывать элементы списка Список и конкретизировать N полученным числом. Как и раньше, когда речь шла о списках, полезно рассмотреть два случая:
(1) Если список пуст, то его длина равна 0.
(2) Если он не пуст, то Список = [Голова1 | Хвост] и его длина равна 1 плюс длина хвоста Хвост.
Эти два случая соответствуют следующей программе:
длина( [ ], 0).
длина( [ _ | Хвост], N) :-
длина( Хвост, N1),
N is 1 + N1.
Применить процедуру длина можно так:
?- длина( [a, b, [c, d], e], N).
N = 4
Заметим, что во втором предложении этой процедуры две цели его тела нельзя поменять местами. Причина этого состоит в том, что переменная N1 должна быть конкретизирована до того, как начнет вычисляться цель
N is 1 + N1
Таким образом мы видим, что введение встроенной процедуры is привело нас к примеру отношения, чувствительного к порядку обработки предложений и целей. Очевидно, что процедурные соображения для подобных отношений играют жизненно важную роль.
Интересно посмотреть, что произойдет, если мы попытаемся запрограммировать отношение длина без использования is. Попытка может быть такой:
длина1( [ ], 0).
длина1( [ _ | Хвост], N) :-
длина1( Хвост, N1),
N = 1 + N1.
Теперь уже цель
?- длина1( [a, b, [c, d], e], N).
породит ответ:
N = 1+(1+(1+(1+0)))
Сложение ни разу в действительности не запускалось и поэтому ни разу не было выполнено. Но в процедуре длина1, в отличие от процедуры длина, мы можем поменять местами цели во втором предложении:
длина1( _ | Хвост], N) :-
N = 1 + N1,
длина1( Хвост, N1).
Такая версия длина1 будет давать те же результаты, что и исходная. Ее можно записать короче:
длина1( [ _ | Хвост], 1 + N) :-
длина1( Хвост, N).
и она и в этом случае будет давать те же результаты. С помощью длина1, впрочем, тоже можно вычислять количество элементов списка:
?- длина( [а, b, с], N), Длина is N.
N = 1+(1+(l+0))
Длина = 3
Итак:
Для выполнения арифметических действий используются встроенные процедуры.
Арифметические операции необходимо явно запускать при помощи встроенной процедуры is. Встроенные процедуры связаны также с предопределенными операторами +, -, *, /, div и mod.
К моменту выполнения операций все их аргументы должны быть конкретизированы числами.
Значения арифметических выражений можно сравнивать с помощью таких операторов, как <, =< и т.д. Эти операторы вычисляют значения своих аргументов.
Две интерпретации выражения а-b-с...
Две интерпретации выражения а-b-с в предположении, что '-' имеет приоритет 500. Если тип '-' есть yfx, то интерпретация 2 неверна, так как приоритет b-с не выше, чем приоритет '-'.

Между 'х' и 'у' есть разница. Для ее объяснения нам потребуется ввести понятие приоритета аргумента. Если аргумент заключен в скобки или не имеет структуры (является простым объектом), тогда его приоритет равен 0; если же он структурный, тогда его приоритет равен приоритету его главного функтора. С помощью 'х' обозначается аргумент, чей приоритет должен быть строго выше приоритета оператора (т. е. его номер строго меньше номера приоритета оператора); с помощью 'у' обозначается аргумент, чей приоритет выше или равен приоритету оператора.
Такие правила помогают избежать неоднозначности при обработке выражений, в которых встречаются операторы с одинаковым приоритетом. Например, выражение
а-b-с
обычно понимается как (а-b)-с , а не как а-(b-с). Чтобы обеспечить такую обычную интерпретацию, оператор '-' следует определять как yfx. На рис. 3.7 показано, каким образом исключается вторая интерпретация.
В качестве еще одного примера рассмотрим оператор not (логическое отрицание "не"). Если not oпределён как fy, тогда выражение
not not р
записано верно; однако, если not определен как fx, оно некорректно, потому что аргументом первого not является структура not p, которая имеет тот же приоритет, что и not. В этом случае выражение следует писать со скобками:
not (not р)
line();:- ор( 1200, xfx, ':-').
:- ор( 1200, fx, [:-, ?-] ).
:- op( 1100, xfy, ';').
:- ор( 1000, xfy, ',').
:- op( 700, xfx, [=, is, <, >, =<, >=, ==, =\=, \==, =:=]).
:- op( 500, yfx, [+, -] ).
:- op( 500, fx, [+, -, not] ).
:- op( 400, yfx, [*, /, div] ).
:- op( 300, xfx, mod).
line();
Списки, операторы, арифметика
Глава 3
СПИСКИ, ОПЕРАТОРЫ, АРИФМЕТИКА
В этой главе мы будем изучать специальные способы представления списков. Список - один из самых простых и полезных типов структур. Мы рассмотрим также некоторые программы для выполнения типовых операций над списками и, кроме того, покажем, как можно просто записывать арифметические выражения и операторы, что во многих случаях позволит улучшить "читабельность" программ. Базовый Пролог (глава 2), расширенный этими тремя добавлениями, станет удобной основой для составления интересных программ.
double_line();Интерпретация терма ~(а & в) <===> ~a v ~в
Интерпретация терма ~(А & В) <===> ~A v ~В

Подытожим:
Наглядность программы часто можно улучшить, использовав операторную нотацию. Операторы бывают инфиксные, префиксные и постфиксные.
В принципе, с оператором не связываются никакие действия над данными, за исключением особых случаев. Определение оператора не содержит описания каких-либо действий, оно лишь вводит новый способ записи. Операторы, как и функторы, лишь связывают компоненты в единую структуру.
Программист может вводить свои собственные операторы. Каждый оператор определяется своим именем, приоритетом и типом.
Номер приоритета - это целое число из некоторого диапазона, скажем, между 1 и 1200. Оператор с самым больший номером приоритета соответствует главному функтору выражения, в котором этот оператор встретился. Операторы с меньшими номерами приоритетов связывают свои аргументы сильнее других операторов.
Тип оператора зависит от двух условий: (1) его расположения относительно своих аргументов, (2) приоритета его аргументов по сравнению с его собственным. В спецификаторах, таких, как xfy, х обозначает аргумент, чей номер приоритета строго меньше номера приоритета оператора; у
- аргумент с номером приоритета, меньшим или равным номеру приоритета оператора.
Конкатенация списков.
Конкатенация списков.

Составленную программу можно теперь использовать для сцепления заданных списков, например:
?- конк( [a, b, с], [1, 2, 3], L ).
L = [a, b, c, 1, 2, 3]
?- конк( [а, [b, с], d], [а, [ ], b], L ).
L = [a, [b, c], d, а, [ ], b]
Хотя программа для конк выглядит довольно просто, она обладает большой гибкостью и ее можно использовать многими другими способами. Например, ее можно применять как бы в обратном направлении для разбиения заданного списка на две части:
?- конк( L1, L2, [а, b, с] ).
L1 = [ ]
L2 = [а, b, c];
L1 = [а]
L2 = [b, с];
L1 = [а, b]
L2 = [c];
L1 = [а, b, с]
L2 = [ ];
no (нет)
Список [а, b, с] разбивается на два списка четырьмя способами, и все они были обнаружены нашей программой при помощи механизма автоматического перебора.
Нашу программу можно также применить для поиска в списке комбинации элементов, отвечающей некоторому условию, задаваемому в виде шаблона или образца. Например, можно найти все месяцы, предшествующие данному, и все месяцы, следующие за ним, сформулировав такую цель:
?- конк( До, [май | После ],
[янв, фев, март, апр, май, июнь,
июль, авг, сент, окт, ноябрь, дек]).
До = [янв, фев, март, апр]
После = [июнь, июль, авг, сент, окт, ноябрь, дек].
Далее мы сможем найти месяц, непосредственно предшествующий маю, и месяц, непосредственно следующий за ним, задав вопрос:
?- конк( _, [Месяц1, май, Месяц2 | _ ],
[янв, февр, март, апр, май, июнь,
июль, авг, сент, окт, ноябрь, дек]).
Месяц1 = апр
Месяц2 = июнь
Более того, мы сможем, например, удалить из некоторого списка L1 все, что следует за тремя последовательными вхождениями элемента z в L1 вместе с этими тремя z. Например, это можно сделать так:
?- L1 = [a, b, z, z, c, z, z, z, d, e],
конк( L2, [z, z, z | _ ], L1).
L1 = [a, b, z, z, c, z, z, z, d, e]
L2 = [a, b, z, z, c]
Мы уже запрограммировали отношение принадлежности. Однако, используя конк, можно было бы определить это отношение следующим эквивалентным способом:
принадлежит1( X, L) :-
конк( L1, [X | L2], L).
Множество предопределенных операторов.
Множество предопределенных операторов.
Для удобства некоторые операторы в пролог-системах определены заранее, чтобы ими можно было пользоваться сразу, без какого-либо определения их в программе. Набор таких операторов и их приоритеты зависят от реализации. Мы будем предполагать, что множество этих "стандартных" операторов ведет себя так, как если бы оно было определено с помощью предложений, приведенных на рис. 3.8. Как видно из того же рисунка, несколько операторов могут быть определены в одном предложении, если только они все имеют одинаковый приоритет и тип. В этом случае имена операторов записываются в виде списка. Использование операторов может значительно повысить наглядность, "читабельность" программы. Для примера предположим, что мы пишем программу для обработки булевских выражений. В такой программе мы, возможно, захотим записать утверждение одной из теорем де Моргана, которое в математических обозначениях записывается так:
~ (А & В) <===> ~А v ~В
Приведем один из способов записи этого утверждения в виде прологовского предложения:
эквивалентно( not( и( А, В)), или( not( A, not( B))).
Однако хорошим стилем программирования было бы попытаться сохранить по возможности больше сходства между видом записи исходной задачи и видом, используемом в программе ее решения. В нашем примере этого можно достичь почти в полной мере, применив операторы. Подходящее множество операторов для наших целей можно определить так:
:- ор( 800, xfx, <===>).
:- ор( 700, xfy, v).
:- ор( 600, хfу, &).
:- ор( 500, fy, ~).
Теперь правило де Моргана можно записать в виде следующего факта:
~(А & В) <===> ~А v ~В.
В соответствии с нашими определениями операторов этот терм понимается так, как это показано на рис. 3.9.
Некоторые операции над списками
Некоторые операции над списками
Списки можно применять для представления множеств, хотя и существует некоторое различие между этими понятиями: порядок элементов множества не существенен, в то время как для списка этот порядок имеет значение; кроме того, один н тот же объект может встретиться в списке несколько раз. Однако наиболее часто используемые операции над списками аналогичны операциям над множествами. Среди них проверка, является ли некоторый объект элементом списка, что соответствует проверке объекта на принадлежность множеству; конкатенация (сцепление) двух списков, что соответствует объединению множеств; добавление нового объекта в список или удаление некоторого объекта из него.
В оставшейся части раздела мы покажем программы, реализующие эти и некоторые другие операции над списками.
Принадлежность к списку1. Принадлежность к списку
Мы представим отношение принадлежности как
принадлежит( X, L)
где Х - объект, а L - список. Цель принадлежит( X, L) истинна, если элемент Х встречается в L. Например, верно что
принадлежит( b, [а, b, с] )
и, наоборот, не верно, что
принадлежит b, [а, [b, с] ] )
но
принадлежит [b, с], [а, [b, с]] )
истинно. Составление программы для отношения принадлежности может быть основано на следующих соображениях:
(1) Х есть голова L, либо
(2) Х принадлежит хвосту L.
Это можно записать в виде двух предложений, первое из которых есть простой факт, а второе - правило:
принадлежит( X, [X | Хвост ] ).
принадлежит ( X, [Голова | Хвост ] ) :-
принадлежит( X, Хвост).
2. Сцепление ( конкатенация)
Для сцепления списков мы определим отношение
конк( L1, L2, L3)
Здесь L1 и L2 - два списка, a L3 - список, получаемый при их сцеплении. Например,
конк( [а, b], [c, d], [a, b, c, d] )
истинно, а
конк( [а, b], [c, d], [a, b, a, c, d] )
ложно. Определение отношения конк, как и раньше, содержит два случая в зависимости от вида первого аргумента L1:
(1) Если первый аргумент пуст, тогда второй и третий аргументы представляют собой один и тот же список (назовем его L), что выражается в виде следующего прологовского факта:
конк( [ ], L, L ).
(2) Если первый аргумент отношения конк не пуст, то он имеет голову и хвост в выглядит так:
[X | L1]
На рис. 3.2 показано, как производится сцепление списка [X | L1] с произвольным списком L2. Результат сцепления - список [X | L3], где L3 получен после сцепления списков L1 и L2. На прологе это можно записать следующим образом:
конк( [X | L1, L2, [X | L3]):-
конк( L1, L2, L3).
Один из способов построения перестановки списка [x | l].
Один из способов построения перестановки списка [X | L].

Программа для отношения перестановка в свою очередь опять может основываться на рассмотрении двух случаев в зависимости от вида первого списка:
(1) Если первый список пуст, то и второй список должен быть пустым.
(2) Если первый список не пуст, тогда он имеет вид [Х | L], и перестановку такого списка можно построить так, как Это показано на рис. 3.5: вначале получить список L1 - перестановку L, а затем внести Х в произвольную позицию L1.
Два прологовских предложения, соответствующих этим двум случаям, таковы:
перестановка( [ ], [ ]).
перестановка( [X | L ], Р) :-
перестановка( L, L1),
внести( X, L1, Р).
Другой вариант этой программы мог бы предусматривать удаление элемента Х из первого списка, перестановку оставшейся его части - получение списка Р, а затем добавление Х в начало списка Р. Соответствующая программа такова:
перестановка2( [ ], [ ]).
перестановка2( L, [X | Р] ) :-
удалить( X, L, L1),
перестановка2( L1, Р).
Поучительно проделать несколько экспериментов с нашей программой перестановки. Ее нормальное использование могло бы быть примерно таким:
?- перестановка( [красный, голубой, зеленый], Р).
Как и предполагалось, будут построены все шесть перестановок:
Р = [ красный, голубой, зеленый];
Р = [ красный, зеленый, голубой];
Р = [ голубой, красный, зеленый];
Р = [ голубой, зеленый, красный];
Р = [ зеленый, красный, голубой];
Р = [ зеленый, голубой, красный];
nо (нет)
Приведем другой вариант использования процедуры перестановка:
?- перестановка( L, [а, b, с] ).
Наша первая версия, перестановка, произведет успешную конкретизацию L всеми шестью перестановками. Если пользователь потребует новых решений, он никогда не получит ответ "нет", поскольку программа войдет в бесконечный цикл, пытаясь отыскать новые несуществующие перестановки. Вторая версия, перестановка2, в этой ситуации найдет только первую (идентичную) перестановку, а затем сразу зациклится. Следовательно, при использовании этих отношений требуется соблюдать осторожность.
Операторная запись (нотация)
Операторная запись (нотация)
В математике мы привыкли записывать выражения в таком виде:
2*a + b*с
где + и * - это операторы, а 2, а, b, с - аргументы. В частности, + и * называют инфиксными операторами, поскольку они появляются между своими аргументами. Такие выражения могут быть представлены в виде деревьев, как это сделано на рис. 3.6, и записаны как прологовские термы с + и * в качестве функторов:
+( *( 2, а), *( b, с) )
Отношения принадлежит и подсписок.
Отношения принадлежит и подсписок.

Его можно сформулировать так:
S является подсписком L, если
(1) L можно разбить на два списка L1 и L2 и
(2) L2 можно разбить на два списка S и L3.
Как мы видели раньше, отношение конк можно использовать для разбиения списков. Поэтому вышеприведенную формулировку можно выразить на Прологе так:
подсписок( S, L) :-
конк( L1, L2, L),
конк( S, L3, L2).
Ясно, что процедуру подсписок можно гибко использовать различными способами. Хотя она предназначалась для проверки, является ли какой-либо список подсписком другого, ее можно использовать, например, для нахождения всех подсписков данного списка:
?- подсписок( S, [а, b, с] ).
S = [ ];
S = [a];
S = [а, b];
S = [а, b, с];
S = [b];
. . .
6. Перестановки
Иногда бывает полезно построить все перестановки некоторого заданного списка. Для этого мы определим отношение перестановка с двумя аргументами. Аргументы - это два списка, один из которых является перестановкой другого. Мы намереваемся порождать перестановки списка с помощью механизма автоматического перебора, используя процедуру перестановка, подобно тому, как это делается в следующем примере:
?- перестановка( [а, b, с], Р).
Р = [а, b, с];
Р = [а, с, b];
Р = [b, а, с];
. . .
Представление списка [энн, теннис, том, лыжи] в виде дерева.
Представление списка [энн, теннис, том, лыжи] в виде дерева.
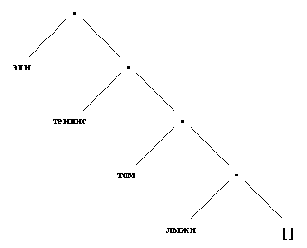
Приведенный пример также напоминает вам о том, что элементами списка могут быть любые объекты, в частности тоже списки.
На практике часто бывает удобным трактовать хвост списка как самостоятельный объект. Например, пусть
L = [а, b, с]
Тогда можно написать:
Хвост = [b, с] и L = .(а, Хвост)
Для того, чтобы выразить это при помощи квадратных скобок, в Прологе предусмотрено еще одно расширение нотации для представления списка, а именно вертикальная черта, отделяющая голову от хвоста:
L = [а | Хвост]
На самом деле вертикальная черта имеет более общий смысл: мы можем перечислить любое количество элементов списка, затем поставить символ " | ", а после этого - список остальных элементов. Так, только что рассмотренный пример можно представить следующими различными способами:
[а, b, с] = [а | [b, с]] = [a, b | [c]] = [a, b, c | [ ]]
Подытожим:
Список - это структура данных, которая либо пуста, либо состоит из двух частей: головы и хвоста. Хвост в свою очередь сам является списком.
Список рассматривается в Прологе как специальный частный случай двоичного дерева. Для повышения наглядности программ в Прологе предусматриваются специальные средства для списковой нотации, позволяющие представлять списки в виде
[ Элемент1, Элемент2, ... ]
или
[ Голова | Хвост ]
или
[ Элемент1, Элемент2, ... | Остальные]
Представление списков
Представление списков
Список - это простая структура данных, широко используемая в нечисловом программировании. Список - это последовательность, составленная из произвольного числа элементов, например энн, теннис, том, лыжи. На Прологе это записывается так:
[ энн, теннис, том, лыжи ]
Однако таково лишь внешнее представление списков. Как мы уже видели в гл. 2, все структурные объекты Пролога - это деревья. Списки не являются исключением из этого правила.
Каким образом можно представить список в виде стандартного прологовского объекта? Мы должны рассмотреть два случая: пустой список и не пустой список. В первом случае список записывается как атом [ ]. Во втором случае список следует рассматривать как структуру состоящую из двух частей:
(1) первый элемент, называемый головой списка;
(2) остальная часть списка, называемая хвостом.
Например, для списка
[ энн, теннис, том, лыжи ]
энн - это голова, а хвостом является список
[ теннис, том, лыжи ]
В общем случае, головой может быть что угодно (любой прологовский объект, например, дерево или переменная); хвост же должен быть списком. Голова соединяется с хвостом при помощи специального функтора. Выбор этого функтора зависит от конкретной реализации Пролога; мы будем считать, что это точка:
.( Голова, Хвост)
Поскольку Хвост - это список, он либо пуст, либо имеет свои собственную голову и хвост. Таким образом, выбранного способа представления списков достаточно для представления списков любой длины. Наш список представляется следующим образом:
.( энн, .( теннис, .( том, .( лыжи, [ ] ) ) ) )
На рис. 3.1 изображена соответствующая древовидная структура. Заметим, что показанный выше пример содержит пустой список [ ]. Дело в том, что самый последний хвост является одноэлементным списком:
[ лыжи ]
Хвост этого списка пуст
[ лыжи ] = .( лыжи, [ ] )
Рассмотренный пример показывает, как общий принцип структуризации объектов данных можно применить к спискам любой длины. Из нашего примера также видно, что такой примитивный способ представления в случае большой глубины вложенности подэлементов в хвостовой части списка может привести к довольно запутанным выражениям. Вот почему в Прологе предусматривается более лаконичный способ изображения списков, при котором они записываются как последовательности элементов, заключенные в квадратные скобки. Программист может использовать оба способа, но представление с квадратными скобками, конечно, в большинстве случаев пользуется предпочтением. Мы, однако, всегда будем помнить, что это всего лишь косметическое улучшение и что во внутреннем представлении наши списки выглядят как деревья. При выводе же они автоматически преобразуются в более лаконичную форму представления. Так, например, возможен следующий диалог:
?- Список1 = [а, b, с],
Список2 = (a, .(b, .(c,[ ]) ) ).
Список1 = [а, b, с]
Список2 = [а, b, с]
?- Увлечения1 = .( теннис, .(музыка, [ ] ) ),
Увлечения2 = [лыжи, еда],
L = [энн, Увлечения1, том, Увлечения2].
Увлечения1 = [теннис, музыка]
Увлечения2 = [лыжи, еда]
L = [энн, [теннис, музыка], том, [лыжи, еда]]
Представление выражения 2*а+b*с в виде дерева.
Представление выражения 2*а+b*с в виде дерева.

Поскольку мы обычно предпочитаем записывать такие выражения в привычной инфиксной форме операторов, Пролог обеспечивает такое удобство. Поэтому наше выражение, записанное просто как
2*а + b*с
будет воспринято правильно. Однако это лишь внешнее представление объекта, которое будет автоматически преобразовано в обычную форму прологовских термов. Такой терм выводится пользователю снова в своей внешней инфиксной форме.
Выражения рассматриваются Прологом просто как дополнительный способ записи, при котором не вводятся какие-либо новые принципы структуризации объектов данных. Если мы напишем а + b, Пролог поймет эту запись, как если бы написали +(а, b). Для того, чтобы Пролог правильно воспринимал выражения типа а + b*с, он должен знать, что * связывает сильнее, чем +. Будем говорить, что + имеет более низкий приоритет, чем *. Поэтому верная интерпретация выражений зависит от приоритетов операторов. Например, выражение а + b*с, в принципе можно понимать и как
+( а, *( b, с) )
и как
Общее правило состоит в том, что оператор с самым низким приоритетом расценивается как главный функтор терма. Если мы хотим, чтобы выражения, содержащие + и *, понимались в соответствии с обычными соглашениями, то + должен иметь более низкий приоритет, чем *. Тогда выражение а + b*с означает то же, что и а + (b*с). Если имеется в виду другая интерпретация, то это надо указать явно с помощью скобок, например ( а+b)*с.
Программист может вводить свои собственные операторы. Так, например, можно определить атомы имеет и поддерживает в качестве инфиксных операторов, а затем записывать в программе факты вида:
питер имеет информацию.
пол поддерживает стол.
Эти факты в точности эквивалентны следующим:
имеет( питер, информацию).
поддерживает( пол, стол).
Программист определяет новые операторы, вводя в программу особый вид предложений, которые иногда называют директивами. Такие предложения играют роль определений новых операторов. Определение оператора должно появиться в программе раньше, чем любое выражение, использующее этот оператор. Например, оператор имеет можно определить директивой
:- ор( 600, xfx, имеет).
Такая запись сообщит Прологу, что мы хотим использовать "имеет" в качестве оператора с приоритетом 600 и типом 'xfx', обозначающий одну из разновидностей инфиксного оператора. Форма спецификатора 'xfx' указывает на то, что оператор, обозначенный через 'f', располагается между аргументами, обозначенными через 'х'.
Обратите внимание на то, что определения операторов не содержат описания каких-либо операций или действий. В соответствии с принципами языка ни с одним оператором не связывается каких-либо операций над данными (за исключением особых, редких случаев). Операторы обычно используются так же, как и функторы, только для объединения объектов в структуры и не вызывают действия над данными, хотя само слово "оператор", казалось бы, должно подразумевать какое-то действие.
Имена операторов это атомы, а их приоритеты - точнее, номера их приоритетов - должны находиться в некотором диапазоне, зависящем от реализации. Мы будем считать, что этот диапазон располагается в пределах от 1 до 1200.(Чем выше приоритет, тем меньше его номер. - Прим. перев.)
Существуют три группы типов операторов, обозначаемые спецификаторами, похожими на xfx:
(1) инфиксные операторы трех типов:
xfx xfy yfx
(2) префиксные операторы двух типов:
fx fy
(3) постфиксные операторы двух типов:
хf yf
Спецификаторы выбраны с таким расчетом, чтобы нагляднее отразить структуру выражения, в котором 'f' соответствует оператору, а 'х' и 'у' представляют его аргументы. Расположение 'f' между аргументами указывает на то, что оператор инфиксный. Префиксные и постфиксные спецификаторы содержат только один аргумент, который, соответственно, либо следует за оператором, либо предшествует ему.
Процедура принадлежит1 находит элемент в заданном
Процедура принадлежит1 находит элемент в заданном

списке, производя по нему последовательный поиск.
В этом предложении сказано: "X принадлежит L, если список L можно разбить на два списка таким образом, чтобы элемент Х являлся головой второго из них. Разумеется, принадлежит1 определяет то же самое отношение, что и принадлежит. Мы использовали другое имя только для того, чтобы различать таким образом две разные реализации этого отношения, Заметим, что, используя анонимную переменную, можно записать вышеприведенное предложение так:
принадлежит1( X, L) :-
конк( _, [X | _ ], L).
Интересно сравнить между собой эти две реализации отношения принадлежности. Принадлежит имеет довольно очевидный процедурный смысл:
Для проверки, является ли Х элементом списка L, нужно
(1) сначала проверить, не совпадает ли голова списка L с X, а затем
(2) проверить, не принадлежит ли Х хвосту списка L.
С другой стороны, принадлежит1, наоборот, имеет очевидный декларативный смысл, но его процедурный смысл не столь очевиден.
Интересным упражнением было бы следующее: выяснить, как в действительности принадлежит1 что-либо вычисляет. Некоторое представление об этом мы получим, рассмотрев запись всех шагов вычисления ответа на вопрос:
?- принадлежит1( b, [а, b, с] ).
На рис. 3.3 приведена эта запись. Из нее можно заключить, что принадлежит1 ведет себя точно так же, как и принадлежит. Он просматривает список элемент за элементом до тех пор, пока не найдет нужный или пока не кончится список.
часто используемая структура. Он либо
Резюме
Список - часто используемая структура. Он либо пуст, либо состоит из головы и хвоста, который в свою очередь также является списком. Для списков в Прологе имеется специальная нотация. В данной главе рассмотрены следующие операции над списками: принадлежность к списку, конкатенация, добавление элемента, удаление элемента, удаление подсписка. Операторная запись позволяет программисту приспособить синтаксис программ к своим конкретным нуждам. С помощью операторов можно значительно повысить наглядность программ. Новые операторы определяются с помощью директивы ор, в которой указываются его имя, тип и приоритет. Как правило, с оператором не связывается никакой операции; оператор это просто синтаксическое удобство, обеспечивающее альтернативный способ записи термов. Арифметические операции выполняются с помощью встроенных процедур. Вычисление арифметических выражений запускается процедурой is, а также предикатами сравнения <, =< и т.д. Понятия, введенные в данной главе:
список, голова списка, хвост списка
списковая нотация
операторы, операторная нотация
инфиксные, префиксные и постфиксные
операторы
приоритет операторов
арифметические встроенные процедуры
Используя отношение конк, напишите цель,
Упражнения
(а) Используя отношение конк, напишите цель, соответствующую вычеркиванию трех последних элементов списка L, результат - новый список L1. Указание: L - конкатенация L1 и трехэлементного списка.
(b) Напишите последовательность целей для порождения списка L2, получающегося из списка L вычеркиванием его трех первых и трех последних элементов.
Посмотреть ответ
Определите отношение
последний( Элемент, Список)
так, чтобы Элемент являлся последним элементом списка Список. Напишите два варианта определения: (а) с использованием отношения конк, (b) без использования этого отношения.
Посмотреть ответ
Добавление элемента
3. Добавление элемента
Наиболее простой способ добавить элемент в список - это вставить его в самое начало так, чтобы он стал его новой головой. Если Х - это новый элемент, а список, в который Х добавляется - L, тогда результирующий список - это просто
[X | L]
Таким образом, для того, чтобы добавить новый элемент в начало списка, не надо использовать никакой процедуры. Тем не менее, если мы хотим определить такую процедуру в явном виде, то ее можно представить в форме такого факта:
добавить( X, L, [X | L] ).
Удаление элемента
4. Удаление элемента
Удаление элемента Х из списка L можно запрограммировать в виде отношения
удалить( X, L, L1)
где L1 совпадает со списком L, у которого удален элемент X. Отношение удалить можно определить аналогично отношению принадлежности. Имеем снова два случая:
(1) Если Х является головой списка, тогда результатом удаления будет хвост этого списка.
(2) Если Х находится в хвосте списка, тогда его нужно удалить оттуда.
удалить( X, [X | Хвост], Хвост).
удалить( X, [Y | Хвост], [ Y | Хвост1] ) :-
удалить( X, Хвост, Хвост1).
как и принадлежит, отношение удалить по природе своей недетерминировано. Если в списке встречается несколько вхождений элемента X, то удалить сможет исключить их все при помощи возвратов. Конечно, вычисление по каждой альтернативе будет удалять лишь одно вхождение X, оставляя остальные в неприкосновенности. Например:
?- удалить( а, [а, b, а, а], L].
L = [b, а, а];
L = [а, b, а];
L = [а, b, а];
nо (нет)
При попытке исключить элемент, не содержащийся в списке, отношение удалить потерпит неудачу.
Отношение удалить можно использовать в обратном направлении для того, чтобы добавлять элементы в список, вставляя их в произвольные места. Например, если мы хотим во все возможные места списка [1, 2, 3] вставить атом а, то мы можем это сделать, задав вопрос: "Каким должен быть список L, чтобы после удаления из него элемента а получился список [1, 2, 3]?"
?- удалить( а, L, [1, 2, 3] ).
L = [а, 1, 2, 3];
L = [1, а, 2, 3];
L = [1, 2, а, 3];
L = [1, 2, 3, а];
nо (нет)
Вообще операция по внесению Х в произвольное место некоторого списка Список, дающее в результате БольшийСписок, может быть определена предложением:
внести( X, Список, БольшийСписок) :-
удалить( X, БольшийСписок, Список).
В принадлежит1 мы изящно реализовали отношение принадлежности через конк. Для проверки на принадлежность можно также использовать и удалить. Идея простая: некоторый Х принадлежит списку Список, если Х можно из него удалить:
принадлежит2( X, Список) :-
удалить( X, Список, _ ).
Подсписок
5. Подсписок
Рассмотрим теперь отношение подсписок. Это отношение имеет два аргумента - список L и список S, такой, что S содержится в L в качестве подсписка. Так отношение
подсписок( [c, d, e], [a, b, c, d, e, f] )
имеет место, а отношение
подсписок( [c, e], [a, b, c, d, e, f] )
нет. Пролог-программа для отношения подсписок может основываться на той же идее, что и принадлежит1, только на этот раз отношение более общо (см. рис. 3.4).
таким образом, чтобы они были
Упражнения
Определите два предиката
четнаядлина( Список) и нечетнаядлина( Список)
таким образом, чтобы они были истинными, если их аргументом является список четной или нечетной длины соответственно. Например, список [а, b, с, d] имеет четную длину, a [a, b, c] - нечетную.
Посмотреть ответ
Определите отношение
обращение( Список, ОбращенныйСписок),
которое обращает списки. Например,
обращение( [a, b, c, d], [d, c, b, a] ).
Посмотреть ответ
Определите предикат
палиндром( Список).
Список называется палиндромом, если он читается одинаково, как слева направо, так и справа налево. Например, [м, а, д, а, м].
Посмотреть ответ
Определите отношение
сдвиг( Список1, Список2)
таким образом, чтобы Список2 представлял собой Список1, "циклически сдвинутый" влево на один символ. Например,
?- сдвиг( [1, 2, 3, 4, 5], L1),
сдвиг1( LI, L2)
дает
L1 = [2, 3, 4, 5, 1]
L2 = [3, 4, 5, 1, 2]
Посмотреть ответ
Определите отношение
перевод( Список1, Список2)
для перевода списка чисел от 0 до 9 в список соответствующих слов. Например,
перевод( [3, 5, 1, 3], [три, пять, один, три] )
Используйте в качестве вспомогательных следующие отношения:
означает( 0, нуль).
означает( 1, один).
означает( 2, два).
. . .
Посмотреть ответ
Определите отношение
подмножество( Множество, Подмножество)
где Множество и Подмножество - два списка представляющие два множества. Желательно иметь возможность использовать это отношение не только для проверки включения одного множества в другое, но и для порождения всех возможных подмножеств заданного множества. Например:
?- подмножество( [а, b, с], S ).
S = [a, b, c];
S = [b, c];
S = [c];
S = [ ];
S = [a, c];
S = [a];
. . .
Посмотреть ответ
Определите отношение
разбиениесписка( Список, Список1, Список2)
так, чтобы оно распределяло элементы списка между двумя списками Список1 и Список2 и чтобы эти списки были примерно одинаковой длины. Например:
разбиениесписка( [а, b, с, d, e], [a, с, е], [b, d]).
Посмотреть ответ
3. 10. Перепишите программу об обезьяне и бананах из главы 2 таким образом, чтобы отношение
можетзавладеть( Состояние, Действия)
давало не только положительный или отрицательный ответ, но и порождало последовательность действий обезьяны, приводящую ее к успеху. Пусть Действия будет такой последовательностью, представленной в виде списка ходов:
Действия = [ перейти( дверь, окно),
передвинуть( окно, середина),
залезть, схватить ]
Посмотреть ответ
3. 11. Определите отношение
линеаризация( Список, ЛинейныйСписок)
где Список может быть списком списков, а ЛинейныйСписок - это тот же список, но "выровненный" таким образом, что элементы его подсписков составляют один линейный список. Например:
? - линеаризация( [а, d, [с, d], [ ], [[[е]]], f, L).
L = [a, b, c, d, e, f]
Посмотреть ответ
то два следующих терма представляют
Упражнения
3. 12. Если принять такие определения
:- ор( 300, xfy, играет_в).
:- ор( 200, xfy, и).
то два следующих терма представляют собой синтаксически правильные объекты:
Tepмl = джимми играет_в футбол и сквош
Терм1 = сьюзан играет_в теннис и баскетбол и волейбол
Как эти термы интерпретируются пролог-системой? Каковы их главные функторы и какова их структура?
Посмотреть ответ
3. 13. Предложите подходящее определение операторов ("работает", "в", "нашем"), чтобы можно было писать предложения типа:
диана работает секретарем в нашем отделе.
а затем спрашивать:
?- Кто работает секретарем в нашем отделе.
Кто = диана
?- диана работает Кем.
Кем = секретарем в нашем отдела
Посмотреть ответ
3. 14. Рассмотрим программу:
t( 0+1, 1+0).
t( X+0+1, X+1+0).
t( X+1+1, Z) :-
t( X+1, X1),
t( X1+1, Z).
Как данная программа будет отвечать на ниже перечисленные вопросы, если '+' "- это (как обычно) инфиксный оператор типа yfx?
(a) ?- t( 0+1, А).
(b) ?- t( 0+1+1, В).
(с) ?- t( 1+0+1+1+1, С).
(d) ?- t( D, 1+1+1+0).
Посмотреть ответ
3. 15. В предыдущем разделе отношения между списка ми мы записывали так:
принадлежит( Элемент, Список),
конк( Список1, Список2, Список3),
удалить( Элемент, Список, НовыйСписок), . . .
Предположим, что более предпочтительной для нас является следующая форма записи:
Элемент входит_в Список,
конкатенация_списков Список1 и Список2
дает Список3,
удаление_элемента Элемент из_списка Список
дает НовыйСписок, ...
Определите операторы "входит_в", "конкатенация_списков", "и" и т.д. таким образом, чтобы обеспечить эту возможность. Переопределите также и соответствующие процедуры.
Посмотреть ответ
чтобы Мах равнялось наибольшому из
Упражнения
3. 16. Определите отношение
mах( X, Y, Мах)
так, чтобы Мах равнялось наибольшому из двух чисел Х и Y.
Посмотреть ответ
3. 17. Определите предикат
максспис( Список, Мах)
так, чтобы Мах равнялось наибольшему из чисел, входящих в Список.
Посмотреть ответ
3. 18. Определите предикат
сумспис( Список, Сумма)
так, чтобы Сумма равнялось сумме чисел, входящих в Список.
Посмотреть ответ
3. 19. Определите предикат
упорядоченный( Список)
который принимает значение истина, если Список представляет собой упорядоченный список чисел. Например: упорядоченный [1, 5, 6, 6, 9, 12] ).
Посмотреть ответ
3. 20. Определите предикат
подсумма( Множ, Сумма, ПодМнож)
где Множ это список чисел, Подмнож подмножество этих чисел, а сумма чисел из ПодМнож равна Сумма. Например:
?- подсумма( [1, 3. 2], 5, ПМ).
ПМ = [1, 2, 2];
ПМ = [2, 3];
ПМ = [5];
. . .
Посмотреть ответ
3. 21. Определите процедуру
между( Nl, N2, X)
которая, с помощью перебора, порождает все целые числа X, отвечающие условию Nl <=X <=N2.
Посмотреть ответ
3. 22. Определите операторы 'если', 'то', 'иначе' и ':=" таким образом, чтобы следующее выражение стало правильным термом:
если Х > Y то Z := Х иначе Z := Y
Выберите приоритеты так, чтобы 'если' стал главным функтором. Затем определите отношение 'если' так, чтобы оно стало как бы маленьким интерпретатором выражений типа 'если-то-иначе'. Например, такого
если Вел1 > Вел2 то Перем := Вел3
иначе Перем := Вел4
где Вел1, Вел2, Вел3 и Вел4 - числовые величины (или переменные, конкретизированные числами), а Перем - переменная. Смысл отношения 'если' таков: если значение Вел1 больше значения Вел2, тогда Перем конкретизируется значением Вел3, в противном случае - значением Вел4. Приведем пример использования такого интерпретатора:
?- Х = 2, Y = 3,
Вел2 is 2*X,
Вел4 is 4*X,
Если Y>Вел2 то Z:=Y иначе Z:=Вел4.
Если Z > 5 то W := 1 иначе W :=0.
Х = 2
Y = 3
Z = 8
W = 1
Вел2 = 4
Вел4 = 8
Посмотреть ответ
