дерево д, построенное как...
(а) Дерево Д, построенное как результат достижения целей: внутри( 5, Д), внутри( 3, Д), внутри( 8, Д). (b) Дерево, полученное при другом порядке целей: внутри( 5, Д), внутри( 3, Д), внутри( 8, Д).
Здесь уместно сделать несколько замечаний относительно эффективности поиска в справочниках. Вообще говоря, поиск элемента в справочнике эффективнее, чем поиск в списке. Но насколько? Пусть n - число элементов множества. Если множество представлено списком, то ожидаемое время поиска будет пропорционально его длине n. В среднем нам придется просмотреть примерно половину списка. Если множество представлено двоичным деревом, то время поиска будет пропорционально глубине дерева. Глубина дерева - это длина самого длинного пути между корнем и листом дерева. Однако следует помнить, что глубина дерева зависит от его формы.
Мы говорим, что дерево (приближенно) сбалансировано, если для каждой вершины дерева соответствующие два поддерева содержат примерно равное число элементов. Если дерево хорошо сбалансировано, то его глубина пропорциональна log n. В этом случае мы говорим, что дерево имеет логарифмическую сложность. Сбалансированный справочник лучше списка настолько же, насколько log n меньше n. К сожалению, это верно только для приближенно сбалансированного дерева. Если происходит разбалансировка дерева, то производительность падает. В случае полностью разбалансированных деревьев, дерево фактически превращается в список. Глубина дерева в этом случае равна n, а производительность поиска оказывается столь же низкой, как и в случае списка. В связи с этим мы всегда заинтересованы в том, чтобы справочники были сбалансированы. Методы достижения этой цели мы обсудим в гл. 10.
граф. (b) направленный граф. Каждой дуге приписана ее стоимость.
(а) Граф. (b) Направленный граф. Каждой дуге приписана ее стоимость.
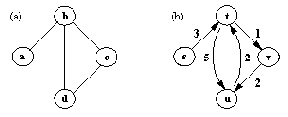
Для представления направленного графа (рис. 9.18), применив функторы диграф и д (для дуг), получим
G2 = диграф( [s, t, u, v],
[д( s, t, 3), д( t, v, 1), д( t, u, 5), д( u, t, 2),
д( v, u, 2) ] )
Если каждая вершина графа соединена ребром еще по крайней мере с одной вершиной, то в представлении графа можно опустить множество вершин, поскольку оно неявным образом содержится в списке ребер.
Еще один способ представления графа - связать с каждой вершиной список смежных с ней вершин. В этом случае граф превращается в список пар, каждая из которых состоит из вершины- плюс ее список смежности. Наши графы (рис. 9.18), например, можно представить как
G1 = [ a->[b1, b->[a, c, d], c->[b, d], d->[b, c] ]
G2 = [s->[t/3], t->[u/5, v/l], u->[t/2], v->[u/2]]
Здесь символы '->' и '/' - инфиксные операторы.
Какой из способов представления окажется более удобным, зависит от конкретного приложения, а также от того, какие операции имеется в виду выполнять над графами. Вот типичные операции: найти путь между двумя заданными вершинами; найти подграф, обладающий некоторыми заданными свойствами.
Примером последней операции может служить построение основного дерева графа. В последующих разделах, мы рассмотрим некоторые простые программы для поиска пути в графе и построения основного дерева.
Поиск пути в графе2. Поиск пути в графе
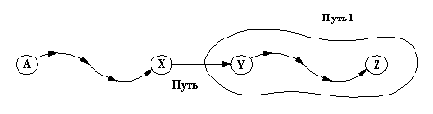
Пусть G - граф, а А и Z - две его вершины. Определим отношение
путь( А, Z, G, Р)
где Р - ациклический путь между А и Z в графе G. Если G - граф, показанный в левой части рис. 9.18, то верно:
путь( a, d, G, [a, b, d] )
путь( а, d, G, [a, b, c, d] )
Поскольку путь не должен содержать циклов, любая вершина может присутствовать в пути не более одного раза. Вот один из методов поиска пути:
line();Для того, чтобы найти ациклический путь Р между А и Z в графе G, необходимо:
Если А = Z , то положить Р = [А], иначе найти ациклический путь Р1 из произвольной вершины Y в Z, а затем найти путь из А в Y, не содержащий вершин из Р1.
line();В этой формулировке неявно предполагается, что существует еще одно отношение, соответствующее поиску пути со следующий ограничением: путь не должен проходить через вершины из некоторого подмножества (в данном случае Р1) множества всех вершин графа. В связи с этим мы определим ещё одну процедуру:
путь1( А, Р1, G, Р)
Аргументы в соответствии с рис. 9.19 имеют следующий смысл: А - некоторая вершина,
обычное изображение дерева. (b) то же дерево,
(а) Обычное изображение дерева. (b) То же дерево,
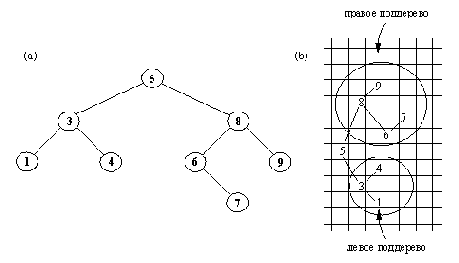
отпечатанное процедурой отобр (дуги добавлены для ясности).
Давайте определим процедуру
отобр( Т)
так, чтобы она отображала дерево в форме, показанной на рис. 9.16. Принцип работы этой процедуры:
line();Для того, чтобы отобразить непустое дерево Т, необходимо:
(1) отобразить правое поддерево дерева Т с отступом вправо на расстояние Н;
(2) отпечатать корень дерева Т;
(3) отобразить левое поддерево дерева Т с отступом вправо на расстояние Н.
line();Величина отступа Н, которую можно выбирать по желанию, - это дополнительный параметр при отображении деревьев. Введем процедуру
отобр2( Т, Н)
печатающую дерево Т с отступом на Н пробелов от левого края листа. Связь между процедурами отобр и отобр2 такова:
отобр( Т) :- отобр2( Т, 0).
На рис. 9.17 показана программа целиком. В этой программе предусмотрен сдвиг на 2 позиции для каждого уровня дерева. Описанный принцип отображения можно легко приспособить для деревьев других типов.
line(); отобр( Т) :-
отобр2( Т, 0).
отобр2( nil, _ ).
отобр2( дер( L, X, R), Отступ) :-
Отступ2 is Отступ + 2,
отобр2( R, Отступ2),
tab( Отступ), write( X), nl,
отобр( L, Отступ2).
Более эффективная реализация процедуры быстрсорт
Более эффективная реализация процедуры быстрсорт
с использованием разностного представления списков. Отношение
разбиение( Х, Спис, Меньш, Больш) определено, как на рис. 9.2.
быстрсорт2. Здесь, как и раньше, процедура быстрсорт использует обычное представление списков, но в действительности сортировку выполняет более эффективная процедура быстрсорт2, использующая разностное представление. Эти две процедуры связаны между собой, соотношением
быстрсорт( L, S) :-
быстрсорт2( L, S-[ ] ).
Быстрая сортировка.
Быстрая сортировка.
становится тривиальной операцией после применения разностного представления списков, введенного в гл. 8. Для того, чтобы использовать эту идею в нашей процедуре сортировки, нужно представить встречающиеся в ней списки в форме пар вида A-Z следующим образом:
УпорМеньш
имеет вид A1-Z1
УпорБольш имеет вид A2-Z2
Тогда конкатенации списков
УпорМеньш и [ Х | УпорБольш]
будет соответствовать конкатенация пар
A1-Z1 и [ Х | A2]-Z2
В результате мы получим
А1-Z2, причем Z1 = [ Х | А2]
Пустой список представляется парой Z-Z. Систематически вводя изменения в программу рис. 9.2, мы получим более эффективный способ реализации процедуры быстрсорт, показанный на рис. 9.3 под именем
line(); быстрсорт( Спис, УпорСпис) :-
быстрсорт2( Спис, УпорСпис-[ ] ).
быстрсорт2( [ ], Z-Z).
быстрсорт2( [X | Хвост], A1-Z2) :-
разбиение( X, Хвост, Меньш, Больш),
быстрсорт2( Меньш, А1-[Х | A2] ),
быстрсорт2( Больш, A2-Z2).
Двоичное дерево.
Двоичное дерево.
Существует более эффективный и более привычный способ представления двоичных деревьев: нам нужен специальный символ для обозначения пустого дерева и функтор для построения непустого дерева из трех компонент ( корня и двух поддеревьев). Относительно функтора и специального символа сделаем следующий выбор: Пусть атом nil представляет пустое дерево. В качестве функтора примем дер, так что дерево с корнем X, левым поддеревом L и правым поддеревом R будет иметь вид терма дер( L, X, R) (см. рис. 9.5).
В этом представлении дерево рис. 9.4 выглядит как
дер( дер( nil, b, nil), a,
дер( дер( nil, d, nil), с, nil) ).
Теперь рассмотрим отношение принадлежности, которое будем обозначать внутри. Цель
внутри( X, Т)
истинна, если Х есть вершина дерева Т. Отношение внутри можно определить при помощи следующих правил:
line();Х есть вершина дерева Т, если корень дерева Т совпадает с X, или Х - это вершина из левого поддерева, или Х - это вершина из правого поддерева. line();
Двоичные справочники: добавление и удаление элемента
Двоичные справочники: добавление и удаление элемента
Если мы имеем дело с динамически изменяемым множеством элементов данных, то нам может понадобиться внести в него новый элемент или удалить из него один из старых. В связи с этим набор основных операций, выполняемых над множеством S, таков:
внутри( X, S) % Х содержится в S
добавить( S, X, S1) % Добавить Х к S, результат - S1
удалить( S, X, S1) % Удалить Х из S, результат - S1
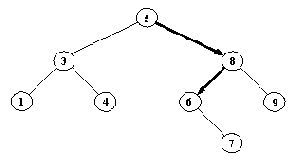
Двоичный справочник. Элемент 6 найден после прохода по отмеченному пути 5-->8-->6.
Двоичный справочник. Элемент 6 найден после прохода по отмеченному пути 5-->8-->6.
Будем говорить, что непустое дерево дер( Лев, X, Прав) упорядочено слева направо, если
(1) все вершины левого поддерева Лев меньше X;
(2) все вершины правого поддерева Прав больше X;
(3) оба поддерева упорядочены.
Будем называть такое двоичное дерево двоичным справочником. Пример показан на рис. 9.6.
Преимущество упорядочивания состоит в том, что для поиска некоторого объекта в двоичном справочнике всегда достаточно просмотреть не более одного поддерева. Экономия при поиске объекта Х достигается за счет того, что, сравнив Х с корнем, мы можем сразу же отбросить одно из поддеревьев. Например, пусть мы ищем элемент 6 в дереве, изображенной на рис. 9.6. Мы начинаем с корня 5, сравниваем 6 с 5, получаем 6 > 5. Поскольку все элементы данных в левом поддереве должны быть меньше, чем 5, единственная область, в которой еще осталась возможность найти элемент 6, - это правое поддерево. Продолжаем поиск в правом поддереве, переходя к вершине 8, и т.д.
Общий метод поиска в двоичном справочнике состоит в следующем:
line();Для того, чтобы найти элемент Х в справочнике Д, необходимо: если Х - это корень справочника Д, то считать, что Х уже найден, иначе если Х меньше, чем корень, то искать Х в левом поддереве, иначе искать Х в правом поддереве; если справочник Д пуст, то поиск терпит неудачу. line();
Эти правила запрограммированы в виде процедуры, показанной на рис. 9.7. Отношение больше( X, Y), означает, что Х больше, чем Y. Если элементы, хранимые в дереве, - это числа, то под "больше, чем" имеется в виду просто Х > Y.
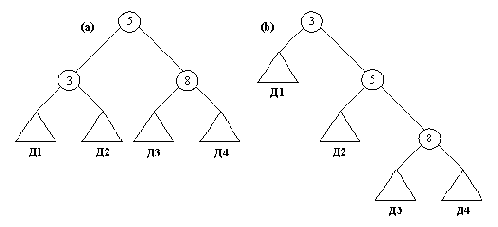
Существует способ использовать процедуру внутри также и для построения двоичного справочника. Например, справочник Д, содержащий элементы 5, 3, 8, будет построен при помощи следующей последовательности целей:
?- внутри( 5, Д), внутри( 3, Д), внутри( 8, Д).
Д = дер( дер( Д1, 3, Д2), 5, дер( Д3, 8, Д4) ).
Переменные Д1, Д2, Д3 и Д4 соответствуют четырем неопределенным поддеревьям. Какими бы они ни были, все равно дерево Д будет содержать заданные элементы 3, 5 и 8. Структура построенного дерева зависит от того порядка, в котором указываются цели (рис. 9.8).
line();внутри( X, дер( _, X, _ ).
внутри( X, дер( Лев, Корень, Прав) ) :-
больше( Корень, X),
% Корень больше, чем Х
внутри( X, Лев).
% Поиск в левом поддереве
внутри( X, дер( Лев, Корень, Прав) ) :-
больше( X, Корень),
% Х больше, чем корень
внутри( X, Прав).
% Поиск в правом поддереве
Графы
Графы
Представление графов
1. Представление графов
Графы используются во многих приложениях, например для представления отношений, ситуаций или структур задач. Граф определяется как множество вершин вместе с множеством ребер, причем каждое ребро задается парой вершин. Если ребра направлены, то их также называют дугами. Дуги задаются упорядоченными парами. Такие графы называются направленными. Ребрам можно приписывать стоимости, имена или метки произвольного вида, в зависимости от конкретного приложения. На рис. 6.18 показаны примеры графов.
В Прологе графы можно представлять различными способами. Один из них - каждое ребро записывать в виде отдельного предложения. Например, графы, показанные иа рис. 9.18, можно представить в виде следующего множества предложений:
связь( а, b).
связь( b, с).
. . .
дуга( s, t, 3).
дуга( t, v, 1).
дуга( u, t, 2).
. . .
Другой способ - весь граф представлять как один объект. В этом случае графу соответствует пара множеств - множество вершин и множество ребер. Каждое множество можно задавать при помощи списка, каждое ребро - парой вершин. Для объединения двух множеств в пару будем применять функтор граф, а для записи ребра - функтор р. Тогда (ненаправленный) граф рис. 9.18 примет вид:
G1 = граф( [a, b, c, d],
[р( а, b), р( b, d), р( b, с), p( c, d)] )
Литература
Литература
В этой главе мы занимались такими важными темами, как сортировка и работа со структурами данных для представления множеств. Общее описание структур данных, а также алгоритмов, запрограммированных в данной главе, можно найти, например, в Aho, Hopcroft and Ullman (1974, 1983) или Baase (1978). В литературе рассматривается также поведение этих алгоритмов, особенно их временная сложность. Хороший и краткий обзор соответствующих алгоритмов и результатов их математического анализа можно найти в Gonnet (1984).
Прологовская программа для внесения нового элемента на произвольный уровень дерева (раздел 9.3) была впервые показана автору М. Ван Эмденом (при личном общении).
Aho А. V., Hopcroft J. Е. and Ullman J. D. (1974). The Design and Analysis of Computer Algorithms. Addison-Wesley. [Имеется перевод: Ахо А., Хопкрофт Дж. Построение и анализ вычислительных алгоритмов. Пер. с англ. - М-: Мир, 1979.]
Aho А. V., Hopcroft J. Е. and Ullman J. D. (1983). Data Structures and Algorithms. Addison-Wesley.
Baase S. (1978). Computer Algorithms. Addison-Wesley.
Gonnet G. H. (1984). Handbook of Algorithms and Data Structures. Addison-Wesley.
Отображение деревьев
Отображение деревьев
Так же, как и любые объекты данных в Прологе, двоичное дерево Т может быть непосредственно выведено на печать при помощи встроенной процедуры write. Однако цель
write( Т)
хотя и отпечатает всю информацию, содержащуюся в дереве, но действительная структура дерева никак при этом не будет выражена графически. Довольно утомительная работа - пытаться представить себе структуру дерева, рассматривая прологовский терм, которым она представлена. Поэтому во многих случаях желательно иметь возможность отпечатать дерево в такой форме, которая графически соответствует его структуре.
Существует относительно простой способ это сделать. Уловка состоит в том, чтобы изображать дерево растущим слева направо, а не сверху вниз, как обычно. Дерево нужно повернуть влево таким образом, чтобы корень стал его крайним слева элементом, а листья сдвинулись вправо (рис. 9.16).
Отображение двоичного дерева.
Отображение двоичного дерева.
Поиск элемента х в двоичном справочнике.
Поиск элемента Х в двоичном справочнике.
Поиск пути в графе: путь - путь между а и z в графе граф стоимостью ст.
Поиск пути в графе: Путь - путь между А и Z в графе Граф стоимостью Ст.
Эту процедуру можно использовать для нахождения пути минимальной стоимости. Мы можем построить путь минимальной стоимости между вершинами Верш1, Верш2 графа Граф, задав цели
путь( Bepш1, Верш2, Граф, МинПуть, МинСт),
not ( путь( Верш1, Верш2, Граф, _, Ст), Ст<МинСт )
Аналогично можно среди всех путей между вершинами графа найти путь максимальной стоимости, задав цели
путь( _, _, Граф, МаксПуть, МаксСт),
not ( путь( _, _, Граф, _, Ст), Ст > МаксСт)
Заметим, что приведенный способ поиска максимальных и минимальных путей крайне неэффективен, так как он предполагает просмотр всех возможных путей и потому не подходит для больших графов из-за своей высокой временной сложности. В искусственном интеллекте задача поиска пути возникает довольно часто. В главах 11 и 12 мы изучим более сложные методы нахождения оптимальных путей.
Построение остовного дерева3. Построение остовного дерева
Граф называется связным, если между любыми двумя его вершинами существует путь. Пусть G = (V, Е) - связный граф с множеством вершин V и множеством ребep Е. Остовное дерево графа G - это связный граф Т = ( V, Е'), где Е' - подмножество Е такое, что
(1) Т - связный граф,
(2) в Т нет циклов.
Выполнение этих двух условий гарантирует то, что Т - дерево. Для графа, изображенного в левой части рис. 9.18, существует три остовных дерева, соответствующих следующим трем спискам ребер:
Дер1 = [а-b, b-c, c-d]
Дер2 = [а-b, b-d, d-с]
Дер3 = [а-b, b-d, b-c]
Здесь каждый терм вида X-Y обозначает ребро, соединяющее вершины Х и Y. В качестве корня можно взять любую из вершин, указанных в списке. Остовные деревья представляют интерес, например в задачах проектирования сетей связи, поскольку они позволяют, имея минимальное число линий, установить связь между любыми двумя узлами, соответствующими вершинам графа.
Определим процедуру
остдерево( G, Т)
где Т - остовное дерево графа G. Будем предполагать, что G - связный граф. Можно представить себе алгоритмический процесс построения остовного дерева следующим образом. Начать с пустого множества ребер и постепенно добавлять новые ребра, постоянно следя за тем, чтобы не образовывались циклы. Продолжать этот процесс до тех пор, пока не обнаружится, что нельзя присоединить ни одного ребра, поскольку любое новое ребро порождает цикл. Полученное множество ребер будет остовным деревом. Отсутствие циклов можно обеспечить, если придерживаться следующего простого правила: ребро присоединяется к дереву только в том случае, когда одна из его вершин уже содержится в строящемся дереве, а другая пока еще не включена в него. Программа, реализующая эту идею, показана на рис. 9.22. Основное отношение, используемое в этой программе, - это
расширить( Дер1, Дер, G)
Здесь все три аргумента - множества ребер. G -
line();% Построение остовного дерева графа
%
% Деревья и графы представлены списками
% своих ребер, например:
% Граф = [а-b, b-с, b-d, c-d]
остдерево( Граф, Дер) :-
% Дер - остовное дерево Граф'а
принадлежит( Ребро, Граф),
расширить( [Ребро], Дер, Граф).
расширить( Дер1, Дер, Граф) :-
добребро( Дер1, Дер2, Граф),
расширить( Дер2, Дер, Граф).
расширить( Дер, Дер, Граф) :-
not добребро( Дер, _, Граф).
% Добавление любого ребра приводит к циклу
добребро( Дер, [А-В | Дер], Граф) :-
смеж( А, В, Граф),
% А и В - смежные вершины
вершина( А, Дер).
% А содержится в Дер
не вершина( В, Дер).
% А-В не порождает цикла
смеж( А, В, Граф) :-
принадлежит ( А-В, Граф);
принадлежит ( В-А, Граф).
вершина( А, Граф) :-
% А содержится в графе, если
смеж( А, _, Граф).
% А смежна какой-нибудь вершине
Pис. 9. 22. Построение остовного дерева: алгоритмический подход.
Предполагается, что Граф - связный граф.
связный граф; Дер1 и Дер - два подмножества G, являющиеся деревьями. Дер - остовное дерево графа G, полученное добавлением некоторого (может быть пустого) множества ребер из G к Дер1. Можно сказать, что "Дер1 расширено до Дер".
Интересно, что можно написать программу построения остовного дерева совершенно другим, полностью декларативным способом, просто формулируя на Прологе некоторые математические определения. Допустим, что как графы, так и деревья задаются списками своих ребер, как в программе рис. 9.22. Нам понадобятся следующие определения:
(1) Т является остовным деревом графа G, если Т - это подмножество графа G и Т - дерево и Т "накрывает" G, т.е. каждая вершина из G содержится также в Т.
(2) Множество ребер Т есть дерево, если Т - связный граф и Т не содержит циклов.
Эти определения можно сформулировать на Прологе (с использованием нашей программы путь из предыдущего раздела) так, как показано на рис. 9.23. Следует, однако, заметить, что эта программа в таком ее виде не представляет практического интереса из-за своей неэффективности.
line();% Построение остовного дерева
% Графы и деревья представлены списками ребер.
остдерево( Граф, Дер) :-
подмнож( Граф, Дер),
дерево( Дер),
накрывает( Дер, Граф).
дерево( Дер) :-
связи( Дер),
not имеетцикл( Дер).
связи( Дер) :-
not ( вершина( А, Дер), вершина( В, Дер),
not путь( А, А, Дер, _ ) ).
имеетцикл( Дер) :-
смеж( А, В, Дер),
путь( А, В, Дер, [А, X, Y | _ ).
% Длина пути > 1
накрывает( Дер, Граф) :-
not ( вершина( А, Граф), not вершина( А, Дер) ).
подмнож( [ ], [ ]).
подмнож( [ Х | L], S) :-
подмнож( L, L1),
( S = L1; S = [ Х | L1] ).
Поиск в графе граф ациклического пути путь из а в z.
Поиск в графе Граф ациклического пути Путь из А в Z.
На рис. 9.20 программа показана полностью. Здесь принадлежит - отношение принадлежности элемента списку. Отношение
смеж( X, Y, G)
означает, что в графе G существует дуга, ведущая из Х в Y. Определение этого отношения зависит от способа представления графа. Если G представлен как пара множеств (вершин и ребер)
G = граф( Верш, Реб)
то
смеж( X, Y, граф( Верш, Реб) ) :-
принадлежит( р( X, Y), Реб);
принадлежит( р( Y, X), Реб).
Классическая задача на графах - поиск Гамильтонова цикла, т.е. ациклического пути, проходящего через все вершины графа. Используя отношение путь, эту задачу можно решить так:
гамильтон( Граф, Путь) :-
путь( _, _, Граф, Путь),
всевершины( Путь, Граф).
всевершины( Путь, Граф) :-
not (вершина( В, Граф),
not принадлежит( В, Путь) ).
Здесь вершина( В, Граф) означает: В - вершина графа Граф.
Каждому пути можно приписать его стоимость. Стоимость пути равна сумме стоимостей входящих в него дуг. Если дугам не приписаны стоимости, то тогда, вместо стоимости, говорят о длине пути.
Для того, чтобы наши отношения путь и путь1 могли работать со стоимостями, их нужно модифицировать, введя дополнительный аргумент для каждого пути:
путь( А, Z, G, Р, С)
путь1( A, P1, C1, G, Р, С)
Здесь С - стоимость пути Р, a C1 - стоимость пути Р1. В отношении смеж также появится дополнительный аргумент, стоимость дуги. На рис. 9.21 показана программа поиска пути, которая строит путь и вычисляет его стоимость.
line(); путь( А, Z, Граф, Путь, Ст) :-
путь1( A, [Z], 0, Граф, Путь, Ст).
путь1( А, [А | Путь1], Ст1, Граф, [А | Путь1], Ст).
путь1( А, [Y | Путь1], Ст1, Граф, Путь, Ст) :-
смеж( X, Y, СтXY, Граф),
not принадлежит( X, Путь1),
Ст2 is Ст1 + СтXY,
путь1( А, [ X, Y | Путь1], Ст2, Граф, Путь, Ст).
Построение остовного дерева: "декларативный подход".
Построение остовного дерева: "декларативный подход".
Отношения вершина и смеж см. на рис. 9. 22.
Представление двоичных деревьев.
Представление двоичных деревьев.
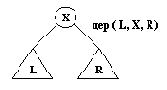
Эти правила непосредственно транслируются на Пролог следующим образом:
внутри( X, дер( -, X, -) ).
внутри( X, дер( L, -, -) ) :-
внутри( X, L).
внутри( X, дер( -, -, R) ) :-
внутри( X, R).
Очевидно, что цель
внутри( X, nil)
терпит неудачу при любом X.
Посмотрим, как ведет себя наша процедура. Рассмотрим рис. 9.4. Цель
внутри( X, Т)
используя механизм возвратов, находит все элементы данных, содержащиеся в множестве, причем обнаруживает их в следующем порядке:
Х = а; Х = b; Х = с; X = d
Теперь рассмотрим вопрос об эффективности. Цель
внутри( а, Т)
достигается сразу же после применения первого предложения процедуры внутри. С другой стороны, цель
внутри( d, Т)
будет успешно достигнута только после нескольких рекурсивных обращений. Аналогично цель
внутри( е, Т)
потерпит неудачу только после того, как будет просмотрено все дерево в результате рекурсивного применения процедуры внутри ко всем поддеревьям дерева Т.
В этом последнем случае мы видим такую же неэффективность, как если бы мы представили множество просто списком. Положение можно улучшить, если между элементами множества существует отношение порядка. Тогда можно упорядочить данные в дереве слева направо в соответствии с этим отношением.
Представление множеств двоичными деревьями
Представление множеств двоичными деревьями
Списки часто применяют для представления множеств. Такое использование списков имеет тот недостаток, что проверка принадлежности элемента множеству оказывается довольно неэффективной. Обычно предикат принадлежит( X, L) для проверки принадлежности Х к L программируют так:
принадлежит X, [X | L] ).
принадлежит X, [ Y | L] ) :-
принадлежит( X, L).
Для того, чтобы найти Х в списке L, эта процедура последовательно просматривает список элемент за элементом, пока ей не встретится либо элемент X, либо конец списка. Для длинных списков такой способ крайне неэффективен.
Для облегчения более эффективной реализация отношения принадлежности применяют различные древовидные структуры. В настоящем разделе мы рассмотрим двоичные деревья.
Двоичное дерево либо пусто, либо состоит из следующих трех частей: корень левое поддерево правое поддерево
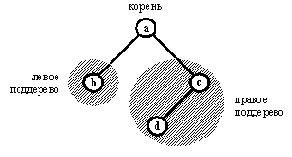
Корень может быть чем угодно, а поддеревья должны сами быть двоичными деревьями. На рис. 9.4 показано представление множества [а, b, с, d] двоичным деревом. Элементы множества хранятся в виде вершин дерева. Пустые поддеревья на рис. 9.4 не показаны. Например, вершина b имеет два поддерева, которые оба пусты.
Существует много способов представления двоичных деревьев на Прологе. Одна из простых возможностей - сделать корень главным функтором соответствующего терма, а поддеревья - его аргументами. Тогда дерево рис. 9.4 примет вид
а( b, с( d) )
Такое представление имеет среди прочих своих недостатков то слабое место, что для каждой вершины дерева нужен свой функтор. Это может привести к неприятностям, если вершины сами являются структурными объектами.
Представление списков. Сортировка
Представление списков. Сортировка
1. Замечания в некоторых альтернативных способах представления списков
В главе 3 была введена специальная система обозначений для списков (специальная прологовская нотация), которую мы и использовали в последующем изложении. Разумеется, это был всего лишь один из способов представления списков на Прологе. Список - это, в самом общем смысле, структура, которая либо пуста, либо состоит из головы и хвоста, причем хвост должен быть сам списком.
ничего_не_делать
в качестве символа, обозначающего пустой список, и атом
затем
в качестве инфиксного оператора для построения списка по заданным голове и хвосту. Этот оператор мы можем объявить в программе, например, так:
:- ор( 500, xfy, затем).
Список
[ войти, сесть, поужинать]
можно было бы тогда записать как
войти затем сесть затем поужинать
затем ничего_не_делать
Важно заметить, что на соответствующем уровне абстракции специальная прологовская нотация и всевозможные альтернативные способы обозначения списков сводятся, фактически, к одному и тому же представлению. В связи с этим типовые операции над списками, такие как
принадлежит ( X, L)
конк( L1, L2, L3)
удалить( X, L1, L2)
запрограммированные нами в специальной прологовской нотации, легко поддаются перепрограммированию в различные системы обозначений, выбранные пользователем. Например, отношение конк транслируется на язык "затем - ничего_не_делать" следующим образом. Определение, которое мы использовали до сих пор, имеет вид
конк( [ ], L, L).
конк( [X | L1], L2, [X | L3] ) :-
конк( L1, L2, L3).
В новой системе обозначений оно превращается в
конк( ничего_не_делать, L, L).
конк( Х затем L1, L2, Х затем L3) :-
конк(L1, L2, L3).
Этот пример показывает, как легко наши определения отношений над списками обобщаются на весь класс структур этого типа. Решение о том, какой именно способ записи списков будет использоваться в той или иной программе, следует принимать в соответствии с тем смыслом, который мы придаем списку в каждом конкретном случае. Если, например, список - это просто множество элементов, то наиболее удобна обычная прологовская нотация, поскольку в ней непосредственно выражается то, что программист имел в виду. С другой стороны, некоторые типы выражений также можно трактовать как своего рода списки. Например, для конъюнктов в исчислении высказываний подошло бы следующее спископодобное представление:
истина соответствует пустому списку,
& - оператор для соединения головы с хвостом, определяемый, например, как
:- ор( 300, xfy, &)
Конъюнкция членов а, b, и с выглядела бы тогда как
а & b & с & истина
Все приведенные примеры базируются, по существу, на одной и той же структуре, представляющей список. Однако в гл. 8 мы рассмотрели существенно другой способ, влияющий на эффективность вычислений. Уловка состояла в том, что список представлялся в виде пары списков, являясь их "разностью". Было показано, что такое представление приводит к очень эффективной реализации отношения конкатенации.
Материал настоящего раздела проливает свет и на то различие, которое существует между применением операторов в математике и применением их в Прологе. В математике с каждым оператором всегда связано некоторое действие, в то время как в Прологе операторы используются просто для представления структур.
В данной главе мы изучали
Резюме
В данной главе мы изучали реализацию на Прологе некоторых часто используемых структур данных и соответствующих операций над ними. В том числе Списки:
варианты представления списков
сортировка списков:
сортировка методом "пузырька"
сортировка со вставками
быстрая сортировка
эффективность этих процедур
Представление множеств двоичными деревьями и двоичными справочниками:
поиск элемента в дереве
добавление элемента
удаление элемента
добавление в качестве листа или корня
сбалансированность деревьев и его связь с
эффективностью этих операций
отображение деревьев
Графы:
представление графов
поиск пути в графе
построение остовного дерева
Сортировка списка процедурой быстрсорт.
Сортировка списка процедурой быстрсорт.
встав( X, [Y | УпорСпис], [Y | УпорСпис1]):-
больше( X, Y), !,
встав( X, УпорСпис, УпорСпис1).
встав( X, УпорСпис, [X | УпорСпис] ).
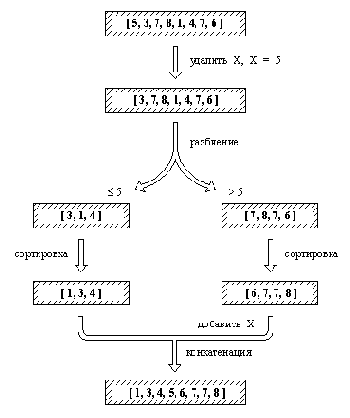
Процедуры сортировки пузырек и вставсорт просты, но не эффективны. Из этих двух процедур процедура со вставками более эффективна, однако среднее время, необходимое для сортировки списка длиной n процедурой вставсорт, возрастает с ростом n пропорционально n2. Поэтому для длинных списков значительно лучше работает алгоритм быстрой сортировки, основанный на следующей идее (рис. 9.1):
line();Для того, чтобы упорядочить непустой список L, необходимо:
(1) Удалить из списка L какой-нибудь элемент Х и разбить оставшуюся часть на два списка, называемые Меньш и Больш, следующим образом: все элементы большие, чем X, принадлежат списку Больш, остальные - списку Меньш.
(2) Отсортировать список Меньш, результат - список УпорМеньш.
(3) Отсортировать список Больш, результат - список УпорБольш.
(4) Получить результирующий упорядоченный список как конкатенацию списков УпорМеньш и [ Х | УпорБольш].
line();Заметим, что если исходный список пуст, то результатом сортировки также будет пустой список. Реализация быстрой сортировки на Прологе показана на рис. 9.2. Здесь в качестве элемента X, удаляемого из списка, всегда выбирается просто голова этого списка. Разбиение на два списка запрограммировано как отношение с четырьмя аргументами:
разбиение( X, L, Больш, Меньш).
Временная сложность нашего алгоритма зависит от того, насколько нам повезет при разбиении сортируемого списка. Если списки всегда разбиваются на два списка примерно равной длины, то процедура сортировки имеет временную сложность порядка nlogn, где n - длина исходного списка. Если же, наоборот, разбиение всегда приводит к тому, что один из списков оказывается значительно больше другого, то сложность будет порядка n2. Анализ показывает, что, к счастью, средняя производительность быстрой сортировки ближе к лучшему случаю, чем к худшему.
Программу, показанную на рис. 9.2, можно усовершенствовать, если реализовать операцию конкатенации более эффективно. Напомним, что конкатенация
line();быстрсорт( [ ], [ ] ).
быстрсорт( [X | Хвост], УпорСпис) :-
разбиение( X, Хвост, Меньш, Больш),
быстрсорт( Меньш, УпорМеньш),
быстрсорт( Больш, УпорБольш),
конк( УпорМеньш, [X | УпорБольш], УпорСпис).
разбиение( X, [ ], [ ], [ ] ).
разбиение( X, [Y | Хвост], [Y | Меньш], Больш ) :-
больше( X, Y), !,
разбиение( X, Хвост, Меньш, Больш).
разбиение( X, [Y | Хвост], Меньш, [Y | Больш] ) :-
разбиение( X, Хвост, Меньш, Больш).
конк( [ ], L, L).
конк( [X | L1], L2, [X | L3] ) :-
конк( L1, L2, L3 ).
Удаление элемента из двоичного справочника.
Удаление элемента из двоичного справочника.
line();
Для того, чтобы добавить Х в двоичный справочник Д, необходимо одно из двух: добавить Х на место корня дерева (так, что Х станет новым корнем) или если корень больше, чем X, то внести Х в левое поддерево, иначе - в правое поддерево. line();
Трудным моментом здесь является введение Х на место корня. Сформулируем эту операций в виде отношения
добкор( Д, X, X1)
где Х - новый элемент, вставляемый вместо корня в Д, а Д1 - новый справочник с корнем Х. На рис. 9.14 показано, как соотносятся X, Д и Д1. Остается вопрос: что из себя представляют поддеревья L1 и L2 (или, соответственно, R1 и R2) на рис. 9.14?
Удаление x из двоичного справочника. Возникает проблема наложения "заплаты" на место удаленного элемента x.
Удаление X из двоичного справочника. Возникает проблема наложения "заплаты" на место удаленного элемента X.
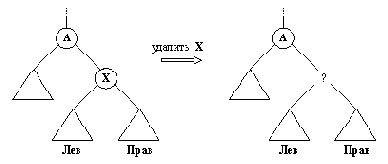
операции добавления листа:
удлист( Д1, X, Д2) :-
доблист( Д2, X, Д1).
К сожалению, если Х - это внутренняя вершина, то такой способ не работает, поскольку возникает проблема, иллюстрацией к которой служит рис. 9.11. Вершина Х имеет два поддерева Лев и Прав. После удаления вершины Х в дереве образуется "дыра", и поддеревья Лев и Прав теряют свою связь с остальной частью дерева. К вершине А оба эти поддерева присоединить невозможно, так как вершина А способна принять только одно из них.
Если одно из поддеревьев Лев и Прав пусто, то существует простое решение: подсоединить к А непустое поддерево. Если же оба поддерева непусты,
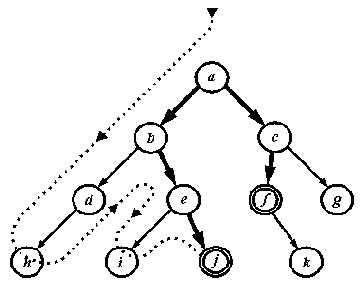
Наша процедура изображает дерево, ориентируя
Упражнение
9. 14. Наша процедура изображает дерево, ориентируя его необычным образом: корень находится слева, а листья - справа. Напишите (более сложную) процедуру для отображения дерева, ориентированного обычным образом, т.е. с корнем наверху и листьями внизу.
Посмотреть ответ
в случае, когда каждому ребру
Упражнение
9. 15. Рассмотрите остовные деревья в случае, когда каждому ребру графа приписана его стоимость. Пусть стоимость остовного дерева определена как сумма стоимостей составляющих его ребер. Напишите программу построения для заданного графа его остовного дерева минимальной стоимости.
к списку, используя систему обозначений,
Упражнения
Определите отношение
список( Объект)
для распознавания случаев, когда Объект является стандартным прологовским списком.
Посмотреть ответ
Определите отношение принадлежности к списку, используя систему обозначений, введенную в этой разделе: "затем - ничего_не_делать".
Посмотреть ответ
Определите отношение
преобр( СтандСпис, Спис)
для преобразования списков из стандартного представления в систему "затем-ничего_не_делать". Например:
преобр( [а, b], а затем b затем ничего_не_делать)
Посмотреть ответ
Обобщите отношение преобр на случай произвольного альтернативного представления списков. Конкретное представление задается символом, обозначающим пустой список, и функтором для соединения головы с хвостом. В отношении преобр придется добавить два новых аргумента:
преобр( СтандСпис, Спис, Функтор, ПустСпис)
Примеры применения этого отношения:
?- пpeoбp( [а, b], L, затем, ничего_не_делать).
L = а затем b затем ничего_не_делать
?- преобр( [а, b, с], L, +, 0).
L = а+(b+(с+0) )
Посмотреть ответ
Сортировка списков
2. Сортировка списков
Сортировка применяется очень часто. Список можно отсортировать (упорядочить), если между его элементами определено отношение порядка. Для удобства изложения мы будем использовать отношение порядка
больше( X, Y)
означающее, что Х больше, чем Y, независимо от того, что мы в действительности понимаем под "больше, чем". Если элементами списка являются числа, то отношение больше будет, вероятно, определено как
больше( X, Y) := Х > Y.
Если же элементы списка - атомы, то отношение больше может соответствовать алфавитному порядку между ними.
Пусть
сорт( Спис, УпорСпис)
обозначает отношение, в котором Спис - некоторый список, а УпорСпис - это список, составленный из тех же элементов, но упорядоченный по возрастанию в соответствия с отношением больше. Мы построим три определения этого отношения на Прологе, основанные на трех различных идеях о механизме сортировки. Вот первая идея:
line(); Для того, чтобы упорядочить список Спис, необходимо: Найти в Спис два смежных элемента Х и Y, таких, что больше( X, Y), и поменять Х и Y местами, получив тем самым новый список Спис1; затем отсортировать Спис1. Если в Спис нет ни одной пары смежных элементов Х и Y, таких, что больше( X, Y), то считать, что Спис уже отсортирован. line(); Мы переставили местами 2 элемента X и Y, расположенные в списке "не в том порядке", с целью приблизить список к своему упорядоченному состоянию. Имеется в виду, что после достаточно большого числа перестановок все элементы списка будут расположены в правильном порядке. Описанный принцип сортировки принято называть методом пузырька, поэтому соответствующая прологовская процедура будет называться пузырек.
пузырек( Спис, УпорСпис) :-
перест( Спис, Спис1), !, % Полезная перестановка ?
пузырек( Спис1, УпорСпис).
пузырек( УпорСпис, УпорСпис).
% Если нет, то список уже упорядочен
перест( [Х, Y | Остаток], [Y, Х ) Остаток] ):-
% Перестановка первых двух элементов
больше( X, Y).
перест( [Z | Остаток], [Z | Остаток1] ):-
перест( Остаток, Остаток1). % Перестановка в хвосте
Еще один простой алгоритм сортировки называется сортировкой со вставками. Он основан на следующей идее:
line(); Для того, чтобы упорядочить непустой список L = [X | Хв], необходимо:
(1) Упорядочить хвост Хв списка L.
(2) Вставить голову Х списка L в упорядоченный хвост, поместив ее в такое место, чтобы получившийся список остался упорядоченным. Список отсортирован.
line(); Этот алгоритм транслируется в следующую процедуру вставсорт на Прологе:
вставсорт([ ], [ ]).
вставсорт( [X | Хв], УпорСпис) :-
вставсорт( Хв, УпорХв), % Сортировка хвоста
встав( X, УпорХв, УпорСпис).
% Вставить Х на нужное место
Напишите процедуру слияния двух упорядоченных
Упражнения
Напишите процедуру слияния двух упорядоченных списков в один третий список. Например:
?- слить( [2, 5, 6, 6, 8], [1, 3, 5, 9], L).
L = [1, 2, 3, 5, 5, 6, 6, 8, 9]
Программы сортировки, показанные на рис. 9.2 и 9.3, отличаются друг от друга способом представления списков. Первая из них использует обычное представление, в то время как вторая - разностное представление. Преобразование из одного представления в другое очевидно и может быть автоматизировано. Введите в программу рис. 9.2 необходимые изменения, чтобы преобразовать ее в программу рис. 9.3.
Наша программа быстрсорт в случае, когда исходный список уже упорядочен или почти упорядочен, работает очень неэффективно. Проанализируйте причины этого явления.
Существует еще одна хорошая идея относительно механизма сортировки списков, позволяющая избавиться от недостатков программы быстрсорт, а именно: разбить список на два меньших списка, отсортировать их, а затем слить вместе. Итак, для того, чтобы отсортировать список L, необходимо разбить L на два списка L1 и L2 примерно одинаковой длины; произвести сортировку списков L1 и L2,получив списки S1 и S2; слить списки S1 и S2, завершив на этом сортировку списка L. Реализуйте этот принцип сортировки и сравните его эффективность с эффективностью программы быстрсорт.
Посмотреть ответ
двоичным деревом или двоичным справочником
Упражнения
Определите предикаты
двдерево( Объект)
справочник( Объект)
распознающие, является ли Объект двоичным деревом или двоичным справочником соответственно. Используйте обозначения, введенные в данном разделе.
Посмотреть ответ
9. 10. Определите процедуру
глубина( ДвДерево, Глубина)
вычисляющую глубину двоичного дерева в предположении, что глубина пустого дерева равна 0, а глубина одноэлементного дерева равна 1.
Посмотреть ответ
9. 11. Определите отношение
линеаризация( Дерево, Список)
соответствующее "выстраиванию" всех вершин дерева в список.
Посмотреть ответ
9. 12. Определите отношение
максэлемент( Д, Элемент)
таким образом, чтобы переменная Элемент приняла значение наибольшего из элементов, хранящихся в дереве Д.
Посмотреть ответ
9. 13. Внесите изменения в процедуру
внутри( Элемент, ДвСправочник)
добавив в нее третий аргумент Путь таким образом, чтобы можно было бы получить путь между корнем справочника и указанным элементом.
Посмотреть ответ
Внесение элемента на произвольный уровень двоичного справочника.
Внесение элемента на произвольный уровень двоичного справочника.
На рис. 9.15 показана программа для "недетерминированного" добавления элемента в двоичный справочник.
Эта процедура обладает тем замечательным свойством, что в нее не заложено никаких ограничений на уровень дерева, в который вносится новый элемент. В связи с этим операцию добавить можно использовать "в обратном направлении" для удаления элемента из справочника. Например, приведенная ниже последовательность целей строит справочник Д, содержащий элементы 3, 5, 1, 6, а затем удаляет из него элемент 5, после чего получается справочник ДД:
добавить( nil, 3, Д1), добавить( Д1, 5, Д2),
добавить( Д2, 1, Д3), добавить( Д3, 6, Д),
добавить( ДД, 5, Д).
Внесение х в двоичный справочник в качестве корня.
Внесение Х в двоичный справочник в качестве корня.
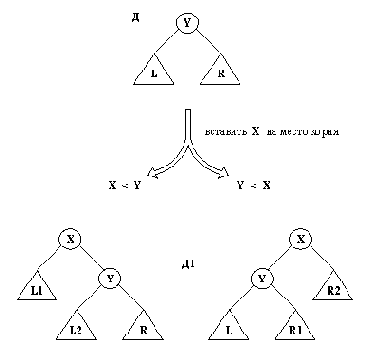
Ответ мы получим, если учтем следующие ограничения на L1, L2: L1 и L2 - двоичные справочники; множество всех вершин, содержащихся как в L1, так и в L2, совпадает с множеством вершин справочника L; все вершины из L1 меньше, чем X; все вершены из L2 больше, чем X.
Отношение, которое способно наложить все эти ограничения на L1, L2, - это как раз и есть наше отношение добкор. Действительно, если бы мы вводили Х в L на место корня, то поддеревьями результирующего дерева как раз и оказались бы L1 и L2. В терминах Пролога L1 и L2 должны быть такими, чтобы достигалась цель
добкор( L, X, дер( L1, X, L2) ).
Те же самые ограничения применимы к R1, R2:
добкор( R, X, дер( R1, X, R2) ).
line(); добавить( Д, X, Д1) :-
% Добавить Х на место корня
добкор( Д, X, Д1).
добавить( дер( L, Y, R), X, дер( L1, Y, R) ) :-
больше( Y, X),
% Ввести Х в левое поддерево
добавить( L, X, L1).
добавить( дер( L, Y, R), X, дер( L, Y, R1) ) :-
больше( X, Y),
% Ввести Х в правое поддерево
добавить( R, X, R1).
добкор( nil, X, дер( nil, X, nil) ). % Ввести Х в пустое дерево
добкор( дер( L, Y, R), Х, дер( L1, Х, дер( L2, Y, R) )) :-
больше( Y, X),
добкор( L, X, дер( L1, X, L2) ).
добкор( дep( L, Y, R), X, дep( дep( L, Y, R1), X, R2) ) :-
больше( X, Y),
добкор( R, X, дер( R1, X, R2) ).
Вставление в двоичный справочник нового элемента в качестве листа.
Вставление в двоичный справочник нового элемента в качестве листа.
Определим отношение добавить. Простейший способ: ввести новый элемент на самый нижний уровень дерева, так что он станет его листом. Место, на которое помещается новый элемент, выбрать таким образом, чтобы не нарушить упорядоченность дерева. На рис. 9.9 показано, какие изменения претерпевает дерево в процессе введения в него новых элементов. Назовем такой метод вставления элемента в множество
доблист( Д, X, Д1)
Правила добавления элемента на уровне листьев таковы: Результат добавления элемента Х к пустому дереву есть дерево дер( nil, X, nil). Если Х совпадает с корнем дерева Д, то Д1 = Д (в множестве не допускается дублирования элементов). Если корень дерева Д больше, чем X, то Х вносится в левое поддерево дерева Д; если корень меньше, чем X, то Х вносится в правое поддерево.
На рис. 9.10 показана соответствующая программа.
Теперь рассмотрим операцию удалить. Лист дерева удалить легко, однако удалить какую-либо внутреннюю вершину - дело не простое. Удаление листа можно на самом деле определить как операцию, обратную
Введение в двоичный справочник...
Введение в двоичный справочник нового элемента на уровне листьев. Показанные деревья соответствуют следующей последовательности вставок:
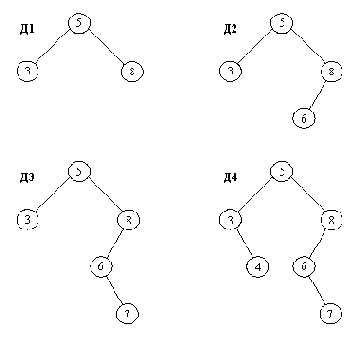
добавить( Д1, 6, Д2), добавить( Д2, 6, Д3), добавить( Д3, 6, Д4) line();
доблист( nil, X, дер( nil, X, nil) ).
доблист( дер( Лев, Х, Прав), Х, дер( Лев, Х, Прав) ).
доблист( дер( Лев, Кор, Прав), Х, дер( Лев1, Кор, Прав)) :-
больше( Кор, X),
доблист( Лев, X, Лев1)).
доблист( дер( Лев, Кор, Прав), Х, дер( Лев, Кор, Прав1)) :-
больше( X, Кор),
доблист( Прав, X, Прав1).
Заполнение пустого места после удаления x.
Заполнение пустого места после удаления X.
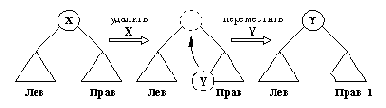
то можно использовать следующую идею (рис. 9.12): если самую левую вершину Y поддерева Прав переместить из ее текущего положения вверх и заполнить ею пробел, оставшийся после X, то упорядоченность дерева не нарушится. Разумеется, та же идея сработает и в симметричном случае, когда перемещается самая правая вершина поддерева Лев.
На рис. 9.13 показана программа, реализующая операцию удаления элементов в соответствии с изложенными выше соображениями. Основную работу по перемещению самой левой вершины выполняет отношение
удмин( Дер, Y, Дер1)
Здесь Y - минимальная (т.е. самая левая) вершина дерева Дер, а Дер1 - то, во что превращается дерево Дер после удаления вершины Y.
Существует другой, элегантный способ реализация операции добавить и удалить. Отношение добавить можно сделать недетерминированным в том смысле, что новый элемент вводится на произвольный уровень дерева, а не только на уровень листьев. Правила таковы:
line();уд( дер( nil, X, Прав), X, Прав).
уд( дер( Лев, X, nil), X, Лев).
уд( дер( Лев, Х, Прав), X, дер( Лев,Y, Прав1) ) :-
удмин( Прав, Y, Прав1).
уд( дер( Лев, Кор, Прав), X, дер( Лев1, Кор, Прав) ) :-
больше( Кор, X),
уд( Лев, X, Лев1).
уд( дер( Лев, Кор, Прав), X, дер( Лев, Кор, Прав1) ) :-
больше( X, Кор),
уд( Прав, X, Прав1).
удмин( дер( nil, Y, Прав), Y, Прав).
удмин( дер( Лев, Кор, Прав), Y, дер( Лев1, Кор, Прав) ) :-
удмин( Лев, Y, Лев1).
